云HBase发布全文索引服务,轻松应对复杂查询
云HBase发布了“全文索引服务”功能,自2019年01月25日后创建的云HBase实例,可以在控制台免费开启此“全文索引服务”功能。使用此功能可以让用户在HBase之上构建功能更丰富的搜索业务,不再局限于KV简单查询,不再苦恼于设计各种rowkey,不再后怕日益变化的HBase复杂查询业务。“全文索引服务”为云HBase增强查询能力而设计,自动同步数据,用户只需重点关注如何使用强大的检索功能来丰富自己的业务架构。
为什么要增强HBase的检索能力
我们在使用HBase的时候都会面临一个问题,就是设计HBase的rowkey。可尽管我们工程师是多么的优秀,整理罗列了所有业务检索需求,并裁剪折中了这样那样的业务,缺依然不能设计一个全能的rowkey来满足各种业务查询需求。
例如在某物流管理系统中,我们需要对收件人姓名/手机/地址、寄件人姓名/手机/地址、运单编号/开始时间/结束时间、邮递员姓名/手机等条件,进行任意组合查询。这种复杂查询情况下,HBase原先的KV查询无法满足,尽管我们如何设计rowkey,都不能满足查询条件的任意性。另外,在这些查询中,可能会涉及到姓名/地址/手机号等条件的模糊查询,这也是HBase rowkey不能很好满足的。
又例如在某新零售业务中,需要对商品标题或者描述内容进行关键字查询,在HBase中我们只能使用模糊查询来实现,但模糊查询在HBase中是比较低效的。类似这种标题/描述内容中进行关键字查询业务,比较合适使用分词查询,这个功能HBase都无法提供满足。另外,在新零售查询业务中,为了提高用户体验,经常会提高搜索结果进行分类统计的需求,例如我们在电商网站中,搜索关键字“时尚”,在显示匹配此关键字结果的商品中,按照 衣服、电子、日用等类型进行了分类统计匹配结果,这样用户就可以选择对应的大类进行二次查询,快速查询到用户想要的商品,从而提高了用户体验。像这个功能,HBase也无法满足。
最终为了适应HBase系统的查询特点,对业务做了折中,只保留部分KV查询的业务,其他可以提高用户体验的各种查询业务被全部砍掉了。
总结下来,我们列出来了几个使用HBase进行查询业务设计时碰到的痛点:
- 无法满足任意条件组合查询
- 不能高效支持模糊查询
- 不支持关键字分词查询
- 不能高效支持多维度的排序/分页
- 不能对查询的结果集进行分类统计
云HBase全文索引服务,增强HBase检索能力
全文索引服务是为了增强HBase查询能力而设计,使得HBase除了强大的KV能力外,更加丰富了它的在复杂条件查询下的能力,具体抽象出来以下几个场景:
- 复杂条件任意查询
- 多维度排序
- 复杂条件分页
- 分词关键字查询
- 匹配结果集分类统计
- 常用min/max/avg/sum等stats统计
云HBase全文索引服务使用简单,只需要DDL阶段建立索引,后续自动进行数据索引同步,架构如下: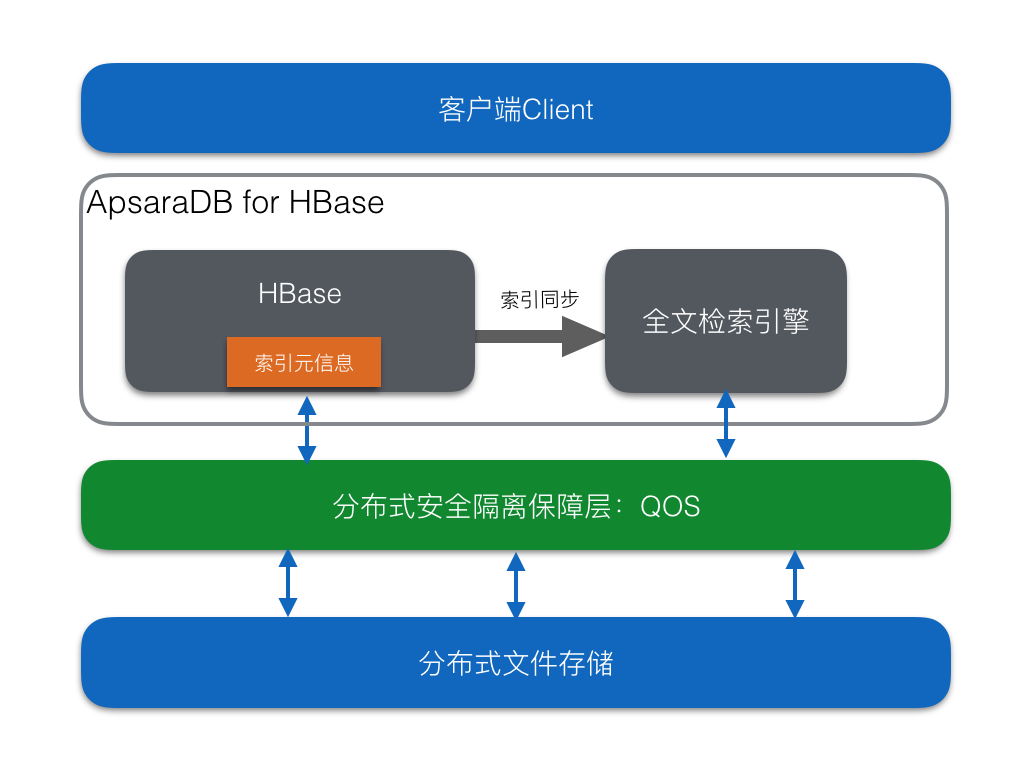
和自建的区别
| 功能 | 云HBase启用全文索引 | 自建HBase+indexer+solr | HBase |
|---|---|---|---|
| 简单rowkey查询 | 支持 | 支持 | 支持 |
| 复杂查询 | 支持 | 支持 | 不支持 |
| 索引同步 | 支持 | 支持 | 不支持 |
| 乱序同步 | 支持 | 不支持 | ——— |
| 强一致 | 支持 | 不支持 | ——— |
| xml动态列 | 支持 | 不支持 | ——— |
另外,自建hbase+indexer+solr存在几个bug,导致很多用户反馈的自建这种架构丢数据现象;云HBase对此进行了许多bugfix和改进。
如何使用云HBase全文索引服务
云HBase全文索引服务的使用,启用此服务后,只需要简单DDL建立索引即可,插入同步无限管理,用户只需关注后续查询要使用HBase api/Solr api进行构建丰富的业务查询即可。下面我们来简单体验下整个流程。
开启服务
“全文索引服务”属于云HBase的免费扩展服务,自2019年1月25日后创建的云HBase实例控制台,实例左侧点击“全文索引服务”详情页进行服务开启即可,如下: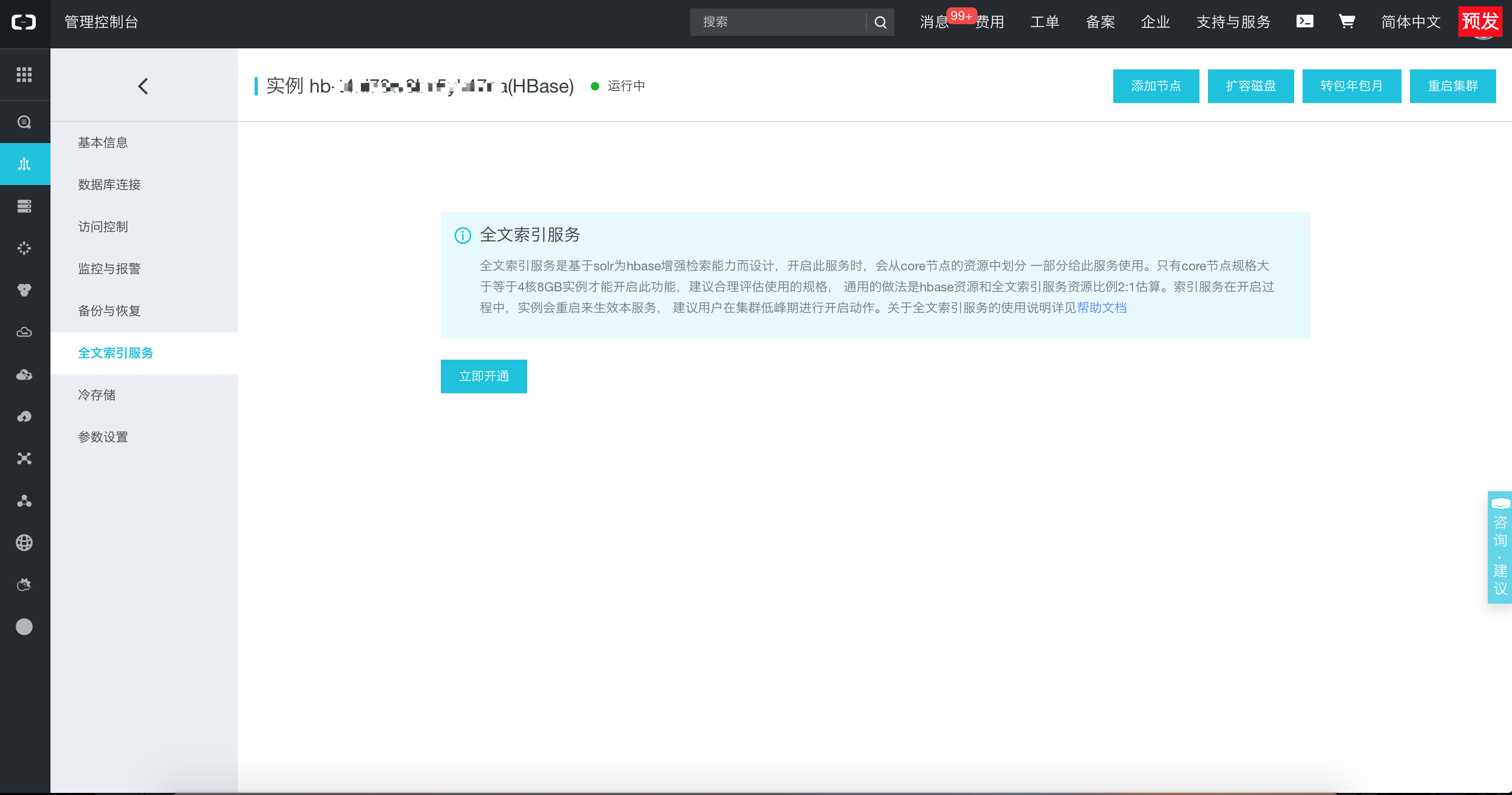
申请后的如下Solr访问地址以及WebUI连接,如图: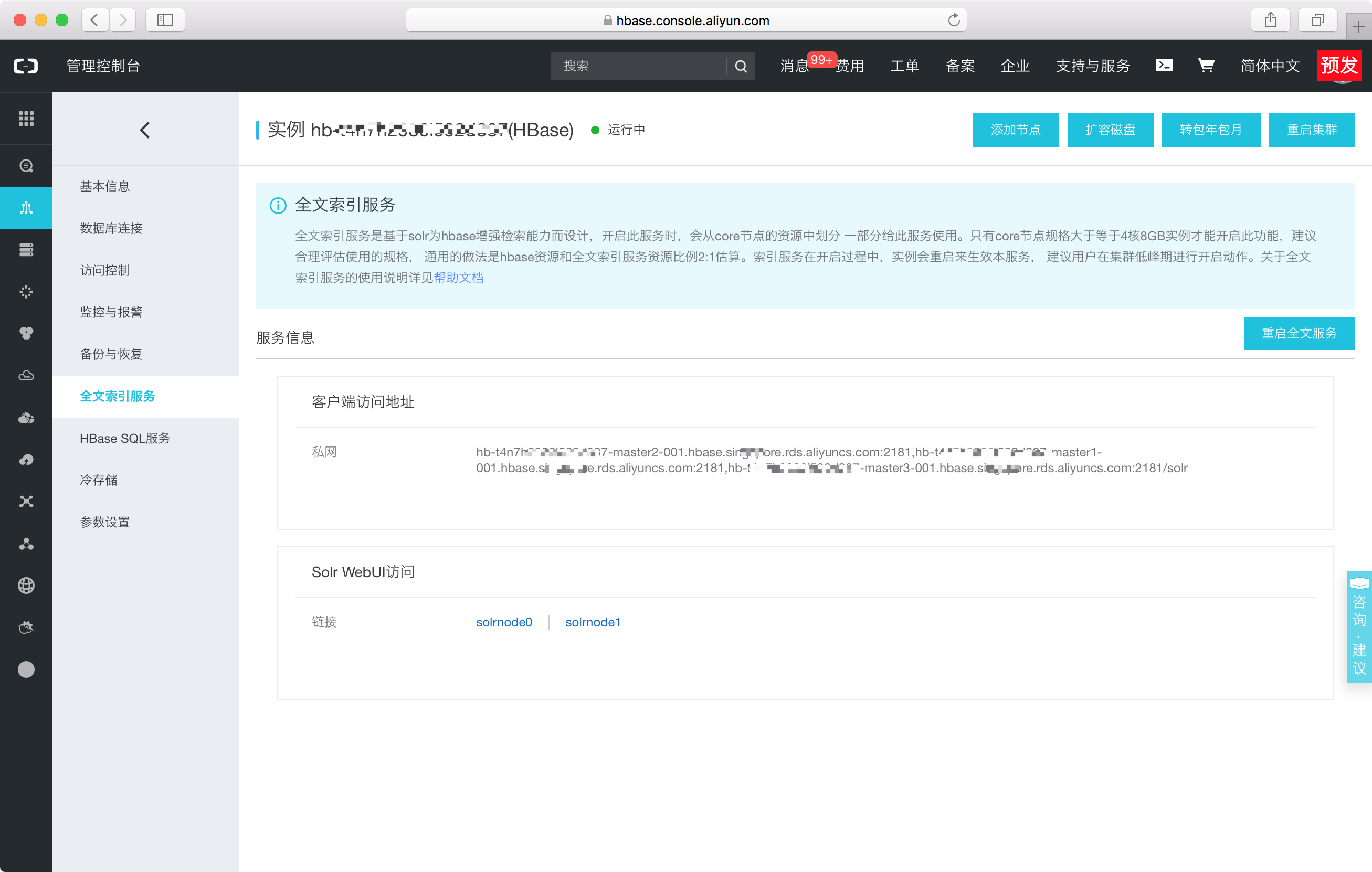
其中solr zk地址即可构造cloud solr client进行访问,此访问客户端自带负载均衡功能。Solr WebUI访问方式与云HBase WebUI访问一致,第一次访问是设置好用户密码与白名单,然后直接点上面的链接即可跳转到Solr的WebUI。
建立索引
- 下载索引管理客户端工具
wget http://public-hbase.oss-cn-hangzhou.aliyuncs.com/installpackage/solr-7.3.1-ali-1.0.tgz
tar zxvf solr-7.3.1-ali-1.0.tgz- 修改solr-7.3.1-ali-1.0/bin/solr.in.sh文件的ZK_HOST如下:
ZK_HOST=zk1:2181,zk2:2181,zk3:2181/solrzk地址即为上图控制台开通全文索引服务后的solr zk访问地址。
- 创建HBase表,开启replication同步机制
create 'solrdemo',{NAME=>'info', REPLICATION_SCOPE=> '1'}- 创建Solr表democollection
第一步,修改并上传solrconfig.xml/schema,如果不需要修改,可使用demo默认config进行上传,如下:
solr-7.3.1-ali-1.0/bin/solr zk upconfig -d _democonfig -n democollection_config -z zk1:2181/solr第二步,使用刚上传的配置创建democollection,如下:
curl "http://hostname:8983/solr/admin/collections?action=CREATE&name=democollection&numShards=1&replicationFactor=1&collection.configName=democollection_config"其中hostname可以使用master3-1中缀的zk hostname进行替换。
- 配置HBase solrdemo表到Solr democollection表的字段映射索引关系
第一步,编辑index_conf.xml配置映射关系,例如:
<?xml version="1.0"?>
<indexer table="solrdemo">
<field name="name_s" value="info:q2" type="string"/>
<field name="age_i" value="info:q3" type="int"/>
<param name="update_version_l" value="true"/>
</indexer>配置描述了hbase表solrdemo的 info:q2 info:3 分别映射成solr democollection里面的name_s和age_i 字段。并指定以string解析info:q2 列保存到name_s字段中,以int解析info:q3 保存到age_i中。其中solr collection的name_s、age_i是何种类型,是根据solr collection的配置觉得,默认采用动态类型推断,即根据collection字段的名字后缀判断类型进行存储。常见类型_i、_s、_l、_b、_f、_d分别对应int/string/long/boolean/float/double。当然,用户也可以直接指定字段类型。最后一个update_version_l为固定写法,保存document级别的最新更新时间。
第二步,使用工具将 index_conf.xml 设置关联hbase表solrdemo和solr表democollection的索引映射关系,命令如下:
solr-7.3.1-ali-1.0/bin/solr-indexer add \
-n demoindex \
-f indexer_conf.xml \
-c democollection到此,我们就完成了索引的关系映射,随后正常插入hbase即可,就不需要关心索引同步,它会自动同步hbase solrdemo表的对应字段到solr democollection表的对应字段中。如上例映射如下: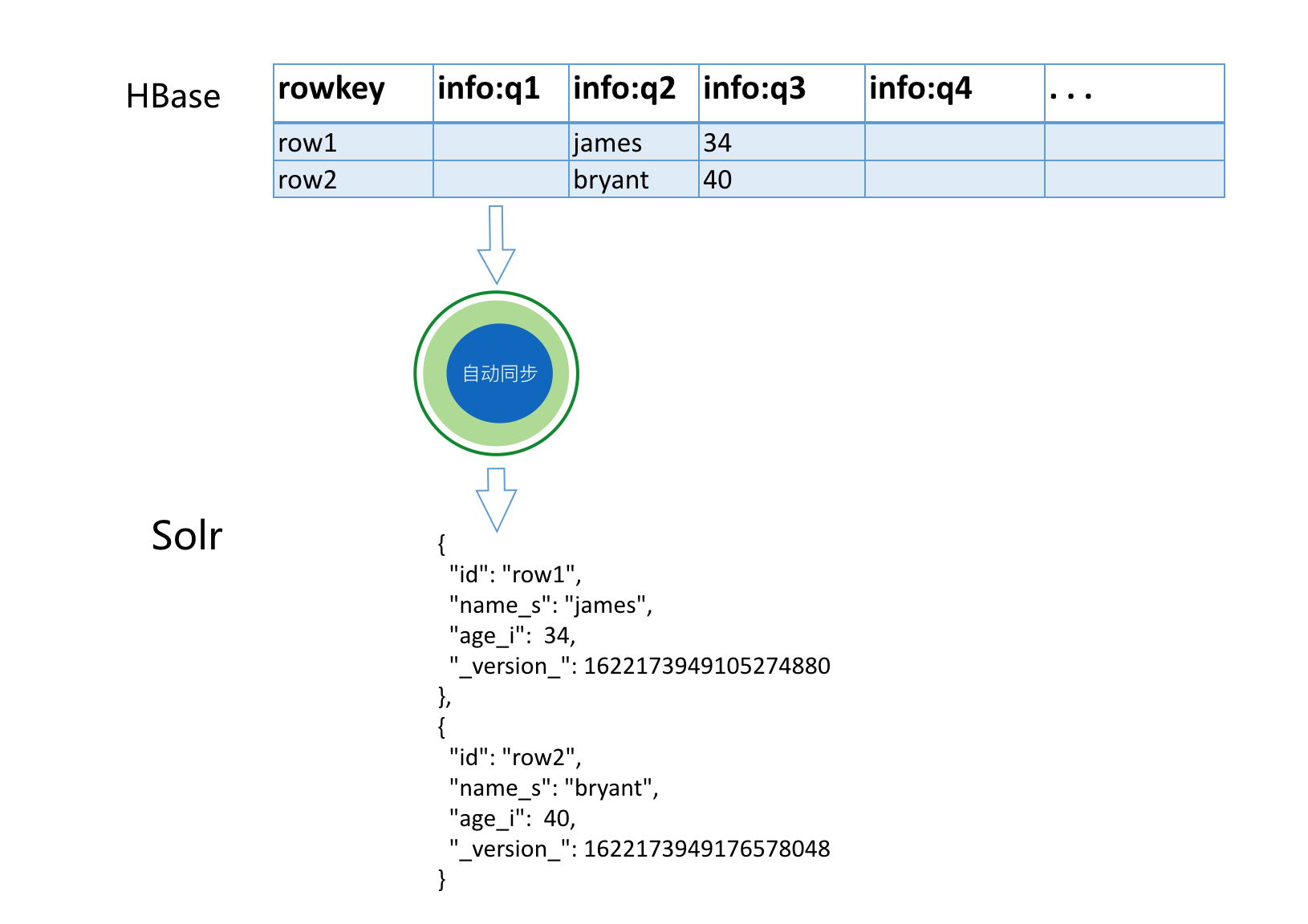
其中,HBase表的rowkey映射到Solr表里面的id字段。
查询检索
查询较为简单,依然完全兼容开源HBase API和Solr API的操作,根据业务使用solr进行条件查询,结果集中,id字段就是所有符合条件的hbase rowkey,我们只有这个id转换为rowkey,并使用HBase API读取属于这个行的原数据即可。流程图大致如下: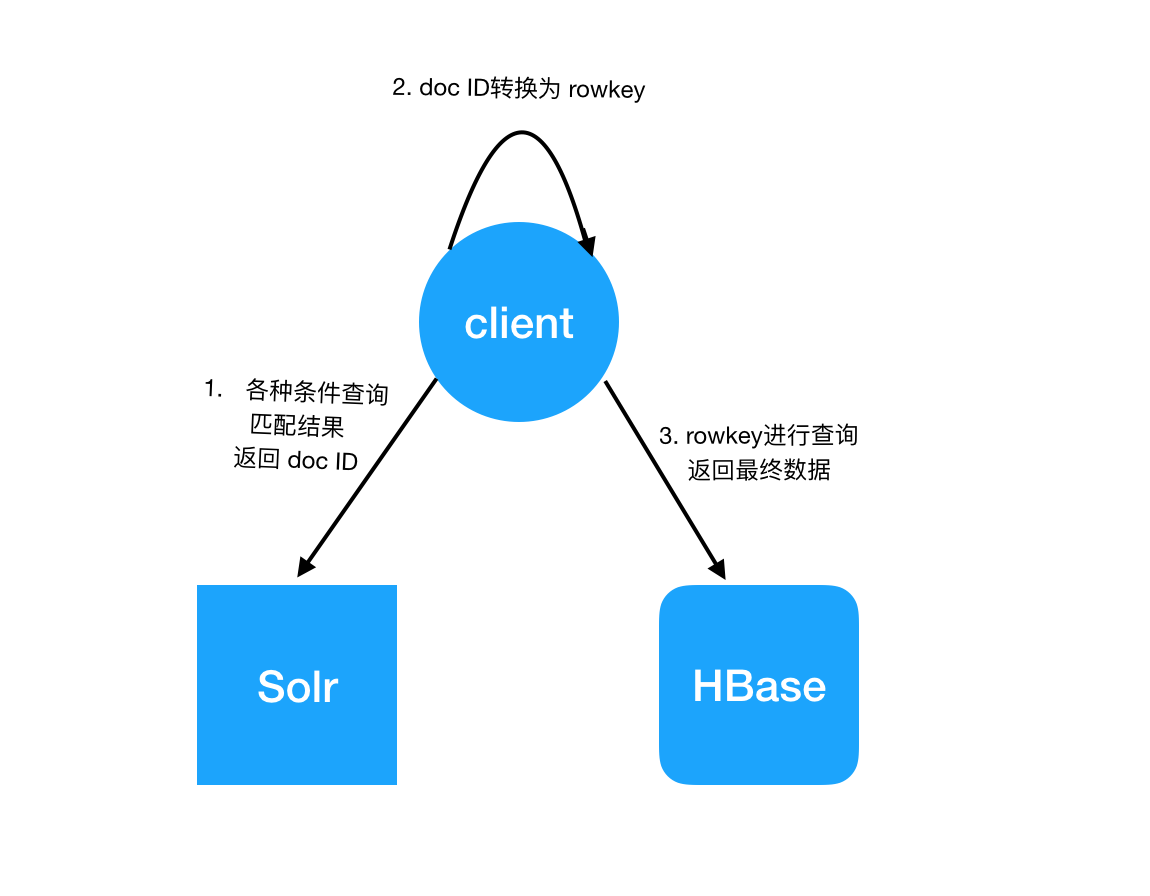
展望
- 索引管理更简单易用
- SQL入口接入全文索引服务
- 全文引擎新一代更高效副本机制
- 除了异步索引,同步索引也会后续支持
原文链接
本文为云栖社区原创内容,未经允许不得转载。
云HBase发布全文索引服务,轻松应对复杂查询的更多相关文章
- 阿里云HBase推出普惠性高可用服务,独家支持用户的自建、混合云环境集群
HBase可以支持百TB数据规模.数百万QPS压力下的毫秒响应,适用于大数据背景下的风控和推荐等在线场景.阿里云HBase服务了多家金融.广告.媒体类业务中的风控和推荐,持续的在高可用.低延迟.低成本 ...
- 云HBase备份恢复,为云HBase数据安全保驾护航
摘要: 介绍了阿里云HBase自研备份恢复功能的基本背景以及基本原理架构和基本使用方法. 云HBase发布备份恢复功能,为用户数据保驾护航.对大多数公司来说数据的安全性以及可靠性是非常重要的,如何 ...
- 阿里云HBase全新发布X-Pack 赋能轻量级大数据平台
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
- 阿里云HBase全新发布X-Pack NoSQL数据库再上新台阶
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
- 阿里云HBase推出全新X-Pack服务 定义HBase云服务新标准
2018年12月13日,第八届中国云计算标准和应用大会在京召开,会上阿里云HBase宣布推出全新X-Pack服务,支持SQL.时序.时空.图.全文检索能力.复杂分析,从处理到分析全栈式数据库,客户开箱 ...
- 云小课 | WAF反爬虫“三板斧”:轻松应对网站恶意爬虫
描述:反爬虫是一个复杂的过程,针对爬虫常见的行为特征,WAF反爬虫三板斧——Robot检测(识别User-Agent).网站反爬虫(检查浏览器合法性)和CC攻击防护(限制访问频率)可以全方位帮您解决业 ...
- 阿里云HBase携X-Pack再进化,重新赋能轻量级大数据平台
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
- 大数据时代数据库-云HBase架构&生态&实践
业务的挑战 存储量量/并发计算增大 现如今大量的中小型公司并没有大规模的数据,如果一家公司的数据量超过100T,且能通过数据产生新的价值,基本可以说是大数据公司了 .起初,一个创业公司的基本思路就是首 ...
- 阿里云异构计算发布:轻量级GPU云服务器实例VGN5i
阿里云发布了国内首个公共云上的轻量级GPU异构计算产品——VGN5i实例,该实例打破了传统直通模式的局限,可以提供比单颗物理GPU更细粒度的服务,从而让客户以更低成本.更高弹性开展业务.适用于云游戏. ...
随机推荐
- K短路 (A*算法) [Usaco2008 Mar]牛跑步&[Sdoi2010]魔法猪学院
A*属于搜索的一种,启发式搜索,即:每次搜索时加一个估价函数 这个算法可以用来解决K短路问题,常用的估价函数是:已经走过的距离+期望上最短的距离 通常和Dijkstra一起解决K短路 BZOJ1598 ...
- Spring事务(一) Markdown 版
事务 事务的特性(ACID) 原子性(Atomicity) 原子性要求事务所包含的全部操作是一个不可分割的整体,这些操作要么全部提交成功,要么只要其中一个操作失败,就全部"成仁" ...
- 【实战小项目】python开发自动化运维工具--批量操作主机
有很多开源自动化运维工具都很好用如ansible/salt stack等,完全不用重复造轮子.只不过,很多运维同学学习Python之后,苦于没小项目训练.本篇就演示用Python写一个批量操作主机的工 ...
- 滴滴 App 的质量优化框架 Booster,开源了!
一. 序 当 App 达到一定体量的时候,肯定是要考虑质量优化.有些小问题,看似只有 0.01% 触发率,但是如果发生在 DAU 过千万的产品中,就很严重了. 滴滴这个独角兽的 DAU 早已过千万,自 ...
- img 灰色默认外边框的去除
最近在做一个小游戏时发现了一个问题,总是在弹出img时先出现一个灰色的边框,所以为了查找问题,查找了一些关于img 默认边框的小知识点. 在这里整理了一些知识点: 一. 下面代码都试验过后会发现,im ...
- linux根目录下的各文件夹含义说明
在早期的 UNIX 系统中,各个厂家各自定义了自己的 UNIX 系统文件目录,比较混乱. Linux 面世不久后,对文件目录进行了标准化,于1994年对根文件目录做了统一的规范, 推出 FHS ( F ...
- Asp.Net Core 轻松学-10分钟使用EFCore连接MSSQL数据库
前言 在 .Net Core 2.2中 Microsoft.AspNetCore.App 默认内置了EntityFramework Core 包,所以在使用过程中,我们无需再从 NuGet 仓 ...
- java 轻量级同步volatile关键字简介与可见性有序性与synchronized区别 多线程中篇(十二)
概念 JMM规范解决了线程安全的问题,主要三个方面:原子性.可见性.有序性,借助于synchronized关键字体现,可以有效地保障线程安全(前提是你正确运用) 之前说过,这三个特性并不一定需要全部同 ...
- Windows Server 2016-DNS 新增或改进功能
本章节补充介绍在 Windows Server 2016 中域名系统 (DNS) 服务器新增或已更改的功能相关信息,具体内容如下: 功能 新增或改进 描述 DNS 策略 新增 您可以配置 DNS 策略 ...
- 织梦dedecms如何修改关键词的字数长度限制
亲测,这个教程比较完善,百度了很多有些少步骤,或者方法根本不对,导致不成功.这个方法我亲子测试了.奏效. 首先登陆数据库后台,如phpmyadmin,找到相应的数据表dede_archives和ded ...