小白的Python之路 day5 re正则模块
re正则模块
一、概述
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,要讲他的具体用法要讲一本书!它内嵌在Python中,并通过 re 模块实现。你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。然后你可以问诸如“这个字符串匹配该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。你也可以使用 RE 以各种方式来修改或分割字符串。今天就来讲讲re模块的最常用的用法。
二、常用的正在表达式符号
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配 re.search("(?P<province>\d{4})(?P<city>\d{2})(?P<birthday>\d{4})","320922199306143242").groupdict()
结果:{'province': '3209', 'city': '22', 'birthday': '1993'}'\' 转义 [a-z] 匹配[a-z][A-Z] 匹配[A-Z][0-9] 匹配数字0-9'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的'\Z' 匹配字符结尾,同$'\d' 匹配数字0-9'\D' 匹配非数字'\w' 匹配[A-Za-z0-9]'\W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' |
三、常用的匹配方法
1、re.match(pattern, string, flags=0)
说明:在string的开始处匹配模式
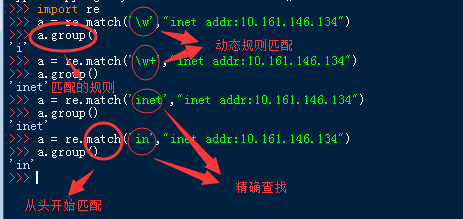
2、re.search(pattern, string, flags=0)
说明:在string中寻找模式

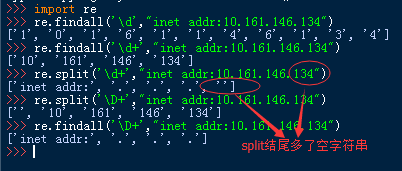
3、re.findall(pattern, string, flags=0)
说明:把匹配到的字符以列表的形式返回

4、re.split(pattern, string, maxsplit=0, flags=0)
说明:匹配到的字符被当做列表分割符
5、re.sub(pattern, repl, string, count=0, flags=0)
说明:匹配字符并替换

四、常用方法
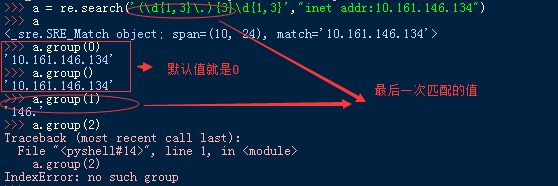
1、group([group1, ...])
说明:获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
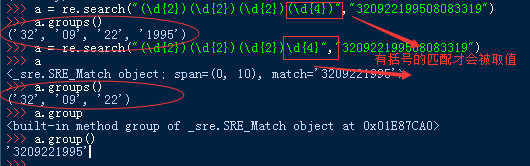
2、groups(default=None)
说明:以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。这个要跟分组匹配结合起来使用'(...)'
3、groupdict(default=None)
说明:返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。这个是跟另外一个分组匹配结合起来用的:

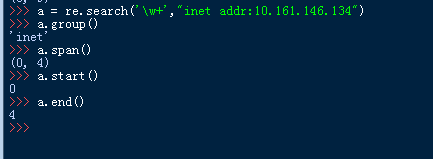
4、span([group])
说明:返回(start(group), end(group))
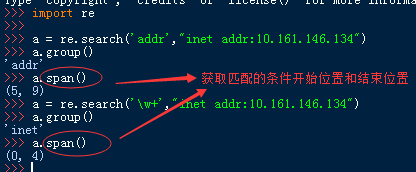
5、start([group])
说明:返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引),group默认值为0。
6、end([group])
说明:返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1),group默认值为0。
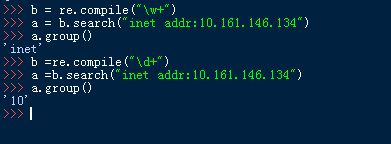
7、compile(pattern[, flags])
说明:根据包含正则表达式的字符串创建模式对象
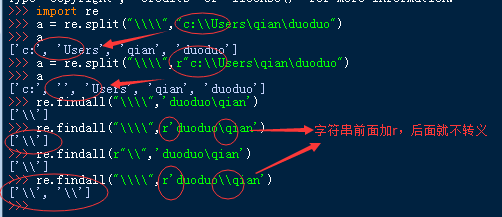
五、反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
六、其他匹配模式
1、re.I(re.IGNORECASE)
说明:忽略大小写(括号内是完整的写法,下同)
|
1
2
3
4
|
>>> import re>>> a = re.search('addr',"inet Addr:10.161.146.134",flags=re.I)>>> a.group()'Addr' #忽略大小写 |
2、re.M(MULTILINE)
说明:多行模式,改变'^'和'$'的行为,详细请见第2点
|
1
2
3
4
|
>>> import re>>> a = re.search('^a',"inet\naddr:10.161.146.134",flags=re.M)>>> a.group()'a' |
3、re.S(DOTALL)
说明:点任意匹配模式,改变'.'的行为
|
1
2
3
4
|
>>> import re>>> a = re.search('.+',"inet\naddr:10.161.146.134",flags=re.S)>>> a.group()'inet\naddr:10.161.146.134' |
注意:上面这三种匹配模式,知道就行。
七、总结
1、用r''的方式表示的字符串叫做raw字符串,用于抑制转义。
2、正则表达式使用反斜杆(\)来转义特殊字符,使其可以匹配字符本身,而不是指定其他特殊的含义。
3、这可能会和python字面意义上的字符串转义相冲突,这也许有些令人费解,比如,要匹配一个反斜杆本身,你也许要用'\\\\'来做为正则表达式的字符串,而字符串里,每个反斜杆都要写成\\。
4、你也可以在字符串前加上 r 这个前缀来避免部分疑惑,因为 r 开头的python字符串是 raw 字符串,所以里面的所有字符都不会被转义,比如r'\n'这个字符串就是一个反斜杆加上一字母n,而'\n'我们知道这是个换行符。因此,上面的'\\\\'你也可以写成r'\\',这样,应该就好理解很多了。
小白的Python之路 day5 re正则模块的更多相关文章
- 小白的Python之路 day5 time,datatime模块详解
一.模块的分类 可以分成三大类: 1.标准库 2.开源模块 3.自定义模块 二.标准库模块详解 1.time与datetime 在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时 ...
- 小白的Python之路 day5 os,sys模块详解
os模块详解 1.作用: 提供对操作系统调用的接口 2.常用方法: os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname" ...
- 小白的Python之路 day5 python模块详解及import本质
一.定义 模块:用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能) 本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test) 包:用来从逻辑上组织模块 ...
- 小白的Python之路 day5 random模块和string模块详解
random模块详解 一.概述 首先我们看到这个单词是随机的意思,他在python中的主要用于一些随机数,或者需要写一些随机数的代码,下面我们就来整理他的一些用法 二.常用方法 1. random.r ...
- 小白的Python之路 day5 shelve模块讲解
shelve模块讲解 一.概述 之前我们说不管是json也好,还是pickle也好,在python3中只能dump一次和load一次,有什么方法可以向dump多少次就dump多少次,并且load不会出 ...
- 小白的Python之路 day5 模块XML特点和用法
模块XML的特点和用法 一.简介 xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今 ...
- 小白的Python之路 day5 configparser模块的特点和用法
configparser模块的特点和用法 一.概述 主要用于生成和修改常见配置文件,当前模块的名称在 python 3.x 版本中变更为 configparser.在python2.x版本中为Conf ...
- 小白的Python之路 day5 hashlib模块
hashlib模块 一.概述 用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 二.算法的演 ...
- 小白的Python之路 day5 logging模块
logging模块的特点及用法 一.概述 很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你 ...
随机推荐
- 搬个小板凳,我们扯扯Docker的前生
一.新瓶装旧酒 首先我们需要知道,Docker是一个"箩筐": 1.存储:Device Mapper.BtrFS.AUFS 2.名字空间:UTS.IPC.Mount.PID.Net ...
- LeetCode第[1]题(Java):Two Sum 标签:Array
题目: Given an array of integers, return indices of the two numbers such that they add up to a specifi ...
- Redis随笔(一)Linux Redis 搭建
1.到官网下载redis上传服务器或者使用wget 下载 wget redis下载的路径 2.查看linux是否安装编译环境gcc,没有先安装 yum -y install gcc 3.解压redis ...
- 扒一扒offsetleft,srollleft,pagex,clientx,postion().left等精确位置的获取与理解
先上个pc端和手机端的图: 说明:上面的属性,都是in这个div的属性值.我是点击的in这个div的左上角,所以pageX.pageY是40. HTML: <div class=" ...
- jsp+servlet登录框架模板
一.建立一个名叫jsp_servlet的工程 二.建立一个AcountBean类和CheckAccount类 1.AcountBean类包含登录名(username)和登录密码(password) p ...
- 用LSTM分类 MNIST
LSTM是RNN的一种算法, 在序列分类中比较有用.常用于语音识别,文字处理(NLP)等领域. 等同于VGG等CNN模型在在图像识别领域的位置. 本篇文章是叙述LSTM 在MNIST 手写图中的使用 ...
- 【三十三】thinkphp之SQL查询语句(全)
一:字符串条件查询 //直接实例化Model $user=M('user1'); var_dump($user->where ('id=1 OR age=55')->select()); ...
- XML(一)XML大揭秘
前言 每天都要学习很多新的知识,比你厉害的程序员比你还努力,那你混的下这口饭吗?所以不抱怨,坚持!接下来给大家分享的是xml.可能很多做开发的都遇到过xml, 比如maven,各种框架的配置文件都有, ...
- [51nod1474]宝藏图
有n堆宝藏,每一堆宝藏有一个挖掘所需要的时间ti,有一个价值qi. 现在是做一个宝藏图.这个宝藏图是这样的,宝藏图的形状是一棵二叉树,二叉树刚好有k个叶子结点,从n堆宝藏中选k堆放到二叉树的叶子结点上 ...
- [bzoj1692] [Usaco2007 Dec]队列变换 (hash||暴力)
本题同bzoj1640...双倍经验双倍幸福 虽然数据范围n=3w然而O(n²)毫无压力= = http://blog.csdn.net/xueyifan1993/article/details/77 ...