对pandas和pendulum的吐槽——TimeStamp numpy的datetime64的转型问题
今天被这俩货因为时间日期处理不兼容的问题折腾半天,气死人,不吐槽不行了!
这俩简称都可以是pd的库,都TM够轴的,互相兼容极差。
pandas 和 pendulum 知名度都很高,也很常用。但我就是用不习惯!各种小坑让我特别不爽。
pandas的api让我觉得奇葩。根本没有其他py库连蒙带猜就能平顺执行的感觉,反正感觉和py风格不太搭。只是个人感觉。用其他知名库从来没这种感觉。
然后它的很多操作,都是列优先的,df['A'] 取一列,然后做某事。这是数据固定,处理数据时方便。
但如果有时偷懒,把Dataframe当成数据库表,想按行操作,就非常别扭。连遍历都得是 for i,r in df.iterrows(): 只能说是相当不py的写法。。
其实现在pd用起来感觉现在稍微好点了,loc iloc, 以前还有乱七八糟的ix之类。还有过想修改覆盖某列时,动不动warning说copy怎么怎么样了,看半天文档我也记不住该怎么搞,还TM挺长。TM老子愿意这样写,TMBB什么啊,(就类似这种,df['c'] = df['c']XXX 记不清了,反正最近好像总算不提示了,你TM api反人类还TM有理了?看几遍TAOUP学学最小立异原则去!)
再说pendulum,首先文档特别没有条理,我从来找不到想用的功能。得一直看很长。感觉特别散
https://pendulum.eustace.io/docs/
很多转型也写不清楚,比如他用isinstance是判断成原生datetime.datetime的,也就是作者希望我们直接用pendulum.DateTime代替datetime.datetime的。
但你TM都欺骗过isinstance了,可以TM倒是把原生的datetime.datetime的属性和方法都TM老实实现了啊。在pd上用,一不留神就直接报告说:
AttributeError: 'DateTime' object has no attribute 'nanosecond'报错了也TM不改,https://github.com/sdispater/pendulum/issues/246 真是服了。
——懂不懂面向对象的规矩啊!懂不懂里氏替换原则(Liskov)原则啊!?子类能这么写的!?
而且,这也不代表,你自认为能替换原生datatime,就可以故意不写清楚 pendulum.DateTime和datetime.datetime的显式相互转型方法啊?
毕竟很多库还是只认原生datetime的。
pendulum转datetime,这个还好。但是那个问题,api奇葩,不常见,不容易记住
dt = datetime(2008, 1, 1)
>>> p = pendulum.instance(dt)
datetime转pendulum:
我只找到这种,就更奇葩了:要先定义个时区,然后转
to_zone = pendulum.timezone('Asia/Shanghai')
dt = to_zone.convert(dt)
而且2和1代还换过1次API风格。我TM到现在还是觉得1.X的API风格反而强些。
pandas 用的时区是pytz,而pendulum自己搞了一套时区,还特意写一篇文章自称比pytz好很多,但问题是,用的时候就恶心了
按说两个star都很高的库,互相兼容,应该是天经地义的啊。
pandas 如果把类似datetime的列定为index 会被转型成TimeStamp。还可以显示设置为DateTimeIndex,这还不算完
最坑的地方是: 如果我这样
[idx for idx in df.index]
遍历出来的是 TimeStamp型
但如果 [idx for list(df.index.values)]
得到的却是numpy.datetime64型。
最大的区别就是timezone。
大概是这样了:
TimeStamp -> numpy.datetime64
虽然找到了这个图参考,但是其实没解决我的问题。
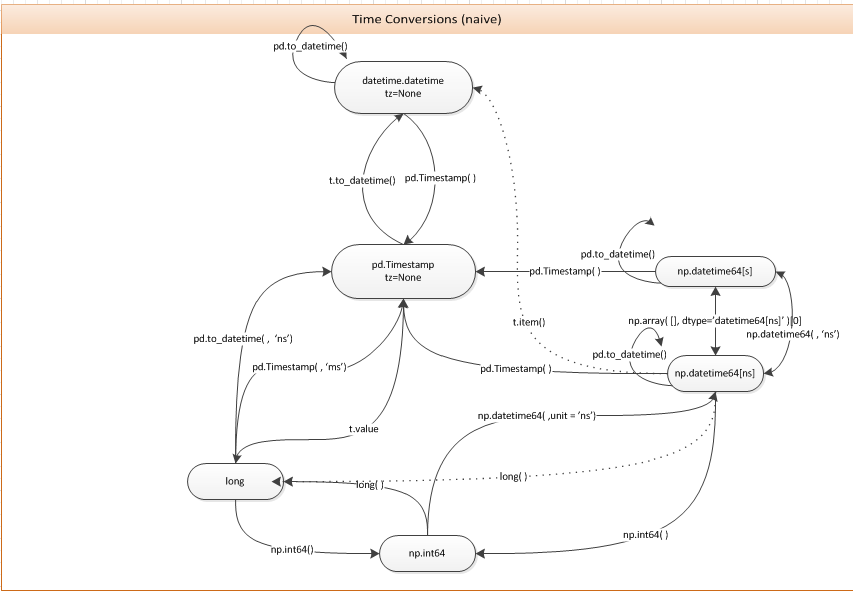
https://cloud.tencent.com/developer/ask/29186
用比较恶心的方法解决掉这个问题
if isinstance(obj_in, pd.Timestamp):
str_without_tz = obj_in.strftime("%Y-%m-%dT%H:%M:%S")
dt = pendulum.parse(str_without_tz, tz=tzinfo)
elif isinstance(obj_in, np.datetime64):
#'2004-06-07T15:00:00+08:00' -> '2018-02-23T07:00:00.000000000'
# 在self.df.index.values 时遇到 dt.strftime("%Y-%m-%dT%H:%M:%S")得到 2004-06-03T07:00:00+08:00 奇葩无法处理
dt = pd.Timestamp(obj_in)
str_without_tz = dt.strftime("%Y-%m-%dT%H:%M:%S")
#print(str_without_tz)
dt = pendulum.parse(str_without_tz, tz='UTC')
dt = to_zone.convert(dt)
比如pendulum 转 pandas TimeStamp,一不留神就报告DateTime上缺nanosecond属性,github上也有人报这个问题,
我只能这样
def dt2pd(dt):
'''pendulum 和pd不兼容'''
assert isinstance(dt, pendulum.DateTime)
#print(dt)
res_str = dt.strftime("%Y-%m-%dT%H:%M:%S")
#print(res_str)
return pd.Timestamp(res_str, tz=dt.timezone.name)
——总之,接口奇葩,很多地方严重不符合“最小立异原则”,转型时各种坑,是最大的问题。但是你不出他们画的圈,用的话倒还好。
对pandas和pendulum的吐槽——TimeStamp numpy的datetime64的转型问题的更多相关文章
- pandas数据类型(二)与numpy的str和object类型之间的区别
现象: Numpy区分了str和object类型,其中dtype(‘S’)和dtype(‘O’)分别对应于str和object. 然而,pandas缺乏这种区别 str和object类型都对应dtyp ...
- [Pandas] 01 - A guy based on NumPy
主要搞明白NumPy“为什么快”. 学习资源 Panda 中文 易百教程 远程登录Jupyter笔记本 效率进化 四步效率优化 NumPy 底层进行了不错的优化. %timeit 对于任意语句,它会自 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 《Python数据分析常用手册》一、NumPy和Pandas篇
一.常用链接: 1.Python官网:https://www.python.org/ 2.各种库的whl离线安装包:http://www.lfd.uci.edu/~gohlke/pythonlibs/ ...
- 【转】python 中NumPy和Pandas工具包中的函数使用笔记(方便自己查找)
二.常用库 1.NumPy NumPy是高性能科学计算和数据分析的基础包.部分功能如下: ndarray, 具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组. 用于对整组数据进行快速运算的标准 ...
- 无用之学matplotlib,numpy,pandas
一.matplotlib学习 matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 例子1: # coding=utf- from ...
- pandas numpy处理缺失值,none与nan比较
原文链接:https://junjiecai.github.io/posts/2016/Oct/20/none_vs_nan/ 建议从这里下载这篇文章对应的.ipynb文件和相关资源.这样你就能在Ju ...
- 使用pandas时遇到ValueError: numpy.dtype has the wrong size, try recompiling
[问题]使用pandas时遇到ValueError: numpy.dtype has the wrong size, try recompiling [原因] 这是因为 Python 包的版本问题,例 ...
- python3安装pandas执行pip3 install pandas命令后卡住不动的问题及安装scipy、sklearn库的numpy.distutils.system_info.NotFoundError: no lapack/blas resources found问题
一直尝试在python3中安装pandas等一系列软件,但每次执行pip3 install pandas后就卡住不动了,一直停在那,开始以为是pip命令的版本不对,还执行过 python -m pip ...
随机推荐
- scrapy 关于 rule, 关于多页
分页 https://www.jianshu.com/p/0c957c57ae10 关于 follow=true, rule https://zhuanlan.zhihu.com/p/25650763 ...
- 18位身份证验证(Java)加入身份证输入验证是否满足18位代码(修订稿)
package day20181016; /** * 身份证的验证 34052419800101001X * */ import java.util.Scanner; public class Zuo ...
- Android之socket服务端
import java.io.DataInputStream; import java.io.IOException; import java.io.PrintWriter; import java. ...
- Bugku-CTF之flag.php(点了login咋没反应)
Day2 flag.php(点了login咋没反应) 地址:http://123.206.87.240:8002/flagphp/
- 【转】java提高篇之理解java的三大特性——多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- com.fasterxml.jackson.databind.JsonMappingException
背景 在搭建SSM整合activiti项目时,在查找activiti定义的流程模板时,前台不能够接受到ProcessDefinition这个对象. 原因 ProcessDefinition是一个接口, ...
- Android 充电信息的获取【转】
本文转载自:https://blog.csdn.net/wateryi/article/details/50834821 在android系统中,电池信息是由BatteryService.java统一 ...
- LD_RUN_PATH和LD_LIBRARY_PATH是干什么的?
1. 使用场合 LD_RUN_PATH在链接时使用 LD_LIBRARY_PATH在执行时使用 2. 如何指定环境变量 export LD_LIBRARY_PATH=/opt/jello/lib:$L ...
- centos7重新调整分区大小
As others have pointed out, XFS filesystem cannot be shrunk. So your best bet is to backup /home, re ...
- 【bzoj1706】[usaco2007 Nov]relays 奶牛接力跑
题意 给出一张无向图,求出恰巧经过n条边的最短路. 题解 考虑先离散化,那么点的个数只会有202个最多.于是复杂度里面就可以有一个\(n^3\).考虑构造矩阵\(d^1\)表示经过一条边的最短路,那么 ...