nodeJS爬虫---慕课网
源代码一(爬取html源码)
//引入http模块
var http = require('http');
//引入url地址
var url = 'http://www.imooc.com/learn/271';
http.get(url,function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end',function(){
console.log(html);
})
}).on('err', function(){
console.log('获取课程数据出错!');
})
源码二(爬取页面的具体信息)
//引入http模块
var http = require('http');
//引入url地址
var url = 'http://www.imooc.com/learn/271';
//引入cheerio对源码进行操作
var cheerio = require('cheerio');
//定义函数对源码进行过滤
function filterChapters(html){
var $ = cheerio.load(html);
//拿到每个大的章节
var chapters = $('.chapter ');
//声明一个数组用来存放所有的大章节的内容
var courseData = [];
//对每个大的章节进行遍历
chapters.each(function(item) {
//拿到单独的某一章
var chapter = $(this);
//获取章节的标题
var chapterTitle = chapter.find('strong').text();
//获取章节下面的内容
var videos = chapter.find('video').children('li');
//声明一个chapterData来存放一个章节的内容、
var chapterData = {
chapterTitle: chapterTitle,
videos: []
};
videos.each(function(item) {
var video = $(this).find('.J-media-item');
var videoTitle = video.text();
var id = video.attr('href').split('video/')[1];
chapterData.videos.push({
title: videoTitle,
id: id
});
});
courseData.push(chapterData);
});
return courseData;
}
//声明一个函数将取到的信息进行打印
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle = item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(item){
console.log(' ['+item.id+'] '+item.title+"\n");
})
})
}
http.get(url,function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end',function(){
//调用对源码进行过滤的函数
var courseData = filterChapters(html);
//调用将信息进行打印的函数
printCourseInfo(courseData);
})
}).on('err', function(){
console.log('获取课程数据出错!');
})
源码一的内容太长,效果就不截图了,源码二的效果截图如下:
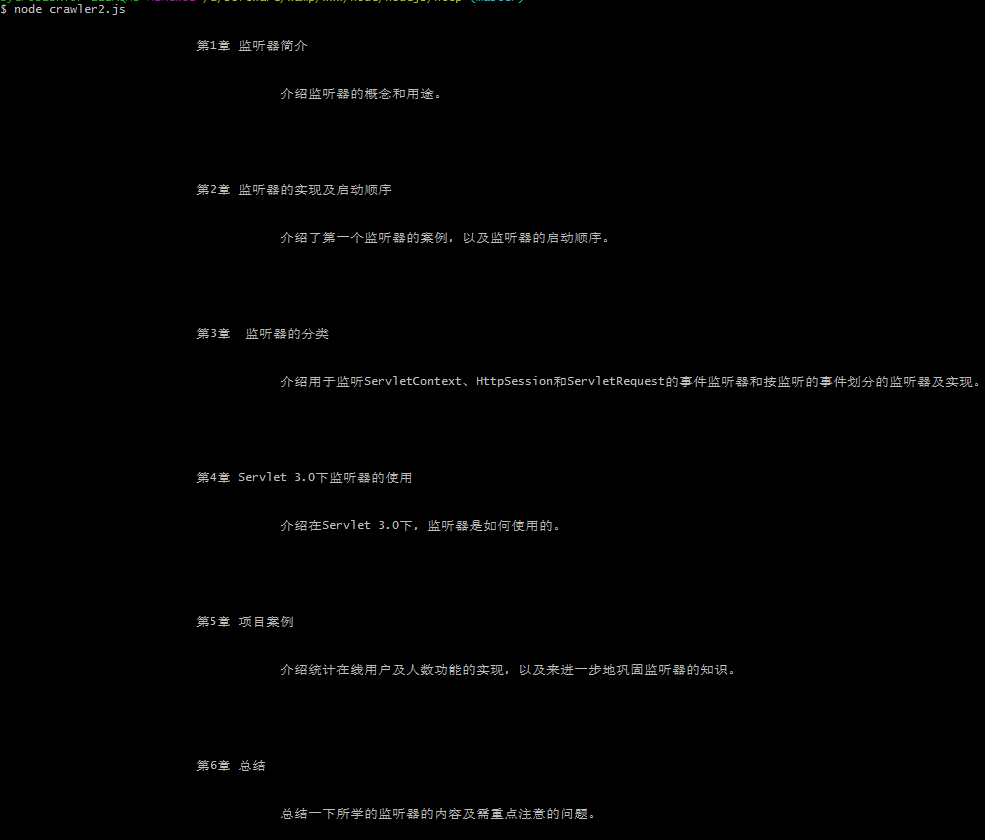
你也可以从https://github.com/byerHu/nodejs上下载源码!
nodeJS爬虫---慕课网的更多相关文章
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- 教你一步一步用 Node.js 制作慕课网视频爬虫
转自:http://www.jianshu.com/p/d7631fc695af 开始 这个教程十分适合初学 Node.js 的初学者看(因为我也是一只初学的菜鸟~) 在这里,我就默认大家都已经在自己 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python爬虫入门教程 20-100 慕课网免费课程抓取
写在前面 美好的一天又开始了,今天咱继续爬取IT在线教育类网站,慕课网,这个平台的数据量并不是很多,所以爬取起来还是比较简单的 准备爬取 打开我们要爬取的页面,寻找分页点和查看是否是异步加载的数据. ...
- 07慕课网《进击Node.js基础(一)》HTTP小爬虫
获取HTML页面 var http = require('http') var url='http://www.imooc.com/learn/348' http.get(url,function(r ...
- nodejs爬虫笔记(一)---request与cheerio等模块的应用
目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库.以http://www.imooc.com/learn/857为例. 一.工具 1.安装nodejs:(操作系统环境:WiN 7 6 ...
随机推荐
- linux命令-文件命令
1.解压.tar文件 tar -vxf *.tar 2.把一个文件夹下的内容复制到另一个文件夹 将aaa内所有内容复制到bbb cp -a aaa/* /bbb/ * 3.复制文件时不改变文件的时间 ...
- 高级查询---嵌套and分页
高级嵌套语句: 子查询: 语句: select * from 表名 where 列名= ( 子查询语句 ) 注意:子查询语句必须放在小括号呢 可以使用< >=等运算符号,sql serve ...
- python下print结果到文件中的方法
目的是将print的结果输出到一个文件中,比如这个文件在D:\lianxi\out.txt下,我用的windows: s = '1234' f = open (r'D:\lianxi\out.txt' ...
- 基于pcDuino-V2的无线视频智能小车
这段时间抽空做了个智能视频小车.包含了pid电机控制.socket网络编程.多线程编程.epoll机制.gtk图形界面编程. 这是界面: 小车的底层是用的stm32f405系列的单片机+电机驱动做的一 ...
- PHP环境的搭建(Apache)
一,下载XAMPP集成软件包. 二,Apache的安装配置: Apache的安装就点击下一步下一步,默认路径在系统的C盘. 三,在star Apache的时候,出现了端口号80冲突(被占用),解决 ...
- [LeetCode] Integer Break 整数拆分
Given a positive integer n, break it into the sum of at least two positive integers and maximize the ...
- JavaScript OOP 之「创建对象」
工厂模式 工厂模式是软件工程领域一种广为人知的设计模式,这种模式抽象了创建具体对象的过程.工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题. function createPers ...
- JAVA的反射理解
1----------------------------反射的概念----------------------------------------------- JAVA的反射机制是在运行状态中,对 ...
- 数据集偏斜 - class skew problem - 以SVM松弛变量为例
原文 接下来要说的东西其实不是松弛变量本身,但由于是为了使用松弛变量才引入的,因此放在这里也算合适,那就是惩罚因子C.回头看一眼引入了松弛变量以后的优化问题: 注意其中C的位置,也可以回想一下C所起的 ...
- openvpn 启动
安装 yum -y install openvpn 配置文件可以放在: /etc/openvpn 例如,我这里的路径: [mslagee@centos-dev ~]$ cd /etc/openvpn/ ...