猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库
1.爬取目标
爬取猫眼电影TOP100榜单
要提取的信息包括:电影排名、电影名称、上映时间、分数
2.分析网页HTML源码
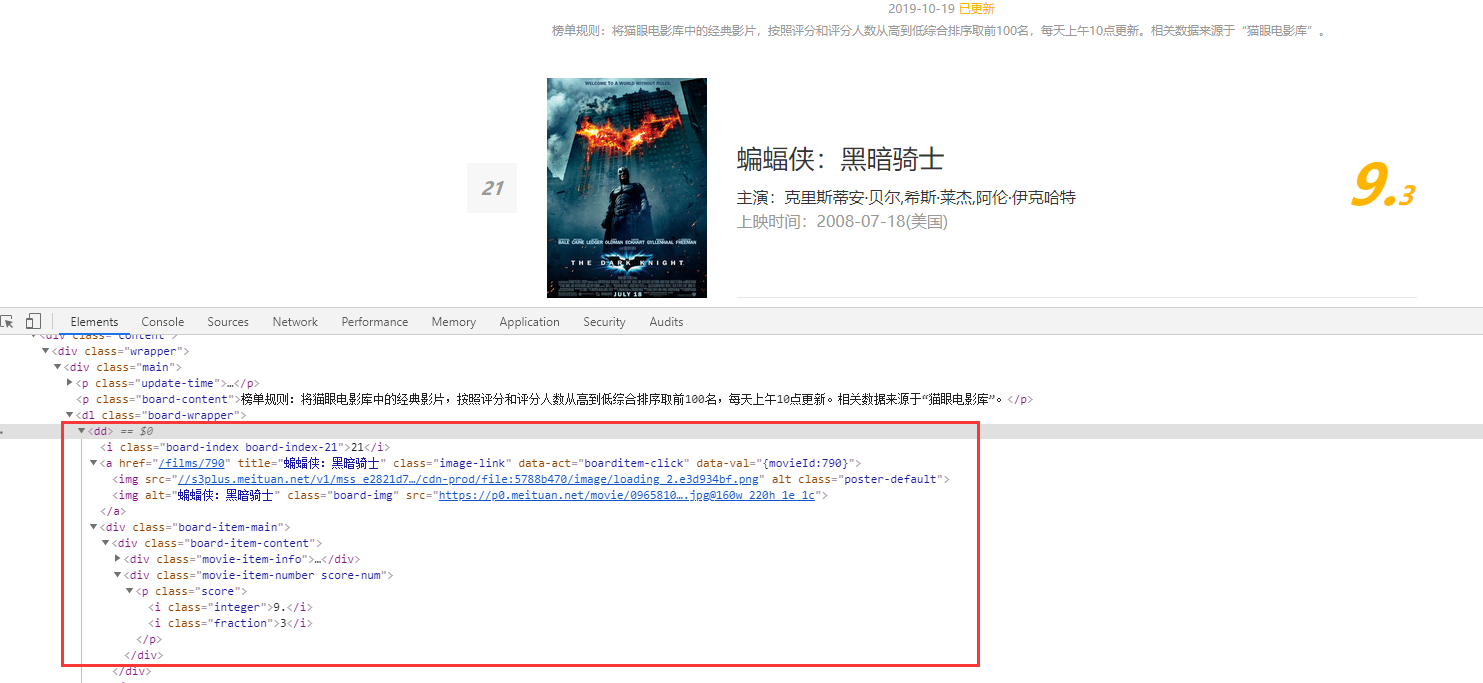
可以看到每部电影信息都被包裹在一对<dd>...</dd>标签中,所以我们只需提取出一个标签对中的上述信息即可。使用正则表达式提取
3. 完整过程
这个例子有2个关键点:正则编写和数据处理(写进mysql数据库)
(1) 正则表达式的编写
pattern = re.compile(r'<dd>.*?<i.*?>(\d+)</i>.*?' # 匹配电影排名(加个?表示非贪婪匹配,不是匹配0次或1次)
r'<p class="name"><a.*?data-val=".*?">(.*?)' # 匹配电影名称
r'</a>.*?<p.*?class="releasetime">(.*?)</p>' # 匹配上映时间
r'.*?<i.*?"integer">(.*?)</i>' # 匹配分数的整数位
r'.*?<i.*?"fraction">(.*?)</i>.*?</dd>', re.S) # 匹配分数小数位,re.S表示跨行匹配
m = pattern.findall(html)
# print(m)
使用findall()方法来匹配所有符合规则的字符,返回一个列表,下面是其中一页的匹配结果

(2)完整代码,注意get_data()函数是如何处理数据,然后通过write_sql()函数是写入数据库的
# coding: utf-8
# author: hmk
import requests
import re
import pymysql
def get_html(url, header):
response = requests.get(url, headers=header)
if response.status_code == 200:
return response.text
else:
return None
def get_data(html, list_data):
pattern = re.compile(r'<dd>.*?<i.*?>(\d+)</i>.*?' # 匹配电影排名
r'<p class="name"><a.*?data-val=".*?">(.*?)' # 匹配电影名称
r'</a>.*?<p.*?class="releasetime">(.*?)</p>' # 匹配上映时间
r'.*?<i.*?"integer">(.*?)</i>' # 匹配分数的整数位
r'.*?<i.*?"fraction">(.*?)</i>.*?</dd>', re.S) # 匹配分数小数位
m = pattern.findall(html)
for i in m: # 因为匹配到的所有结果会以列表形式返回,每部电影信息以元组形式保存,所以可以迭代处理每组电影信息
ranking = i[0] # 提取一组电影信息中的排名
movie = i[1] # 提取一组电影信息中的名称
release_time = i[2] # 提取一组电影信息中的上映时间
score = i[3] + i[4] # 提取一组电影信息中的分数,这里把分数的整数部分和小数部分拼在一起
list_data.append([ranking, movie, release_time, score]) # 每提取一组电影信息就放到一个列表中,同时追加到一个大列表里,这样最后得到的大列表就包含所有电影信息
def write_sql(data):
conn = pymysql.connect(host='localhost',
user='root',
password='123456',
db='test',
charset='utf8')
cur = conn.cursor()
for i in data:
"""这里的data参数是指正则匹配并处理后的列表数据(是一个大列表,包含所有电影信息,每个电影信息都存在各自的一个列表中;
对大列表进行迭代,提取每组电影信息,这样提取到的每组电影信息都是一个小列表,然后就可以把每组电影信息写入数据库了)"""
movie = i # 每组电影信息,这里可以看做是准备插入数据库的每组电影数据
sql = "insert into maoyan_movie(ranking,movie,release_time,score) values(%s, %s, %s, %s)" # sql插入语句
try:
cur.execute(sql, movie) # 执行sql语句,movie即是指要插入数据库的数据
conn.commit() # 插入完成后,不要忘记提交操作
print('导入成功')
except:
print('导入失败')
cur.close() # 关闭游标
conn.close() # 关闭连接
def main():
start_url = 'http://maoyan.com/board/4'
depth = 10 # 爬取深度(翻页)
header = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Host": "maoyan.com",
"Referer": "http://maoyan.com/board",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36"}
for i in range(depth):
url = start_url + '?offset=' + str(10 * i)
html = get_html(url, header)
list_data = []
get_data(html, list_data)
write_sql(list_data)
#print(list_data)
# for i in list_data:
# t = i
# print(t)
if __name__ == "__main__":
main()

注意一点,在请求url时,加了headers,这里必须加,估计是网站做了限制,直接爬的话会失败,可能认出请求链接的不是一个人而是一只虫了
代码中注释写得很详细,不再过多描述了
猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库的更多相关文章
- 爬取网贷之家平台数据保存到mysql数据库
# coding utf-8 import requests import json import datetime import pymysql user_agent = 'User-Agent: ...
- 猫眼电影爬取(二):requests+beautifulsoup,并将数据存储到mysql数据库
上一篇通过requests+正则爬取了猫眼电影榜单,这次通过requests+beautifulsoup再爬取一次(其实这个网站更适合使用beautifulsoup库爬取) 1.先分析网页源码 可以看 ...
- 猫眼电影爬取(三):requests+pyquery,并将数据存储到mysql数据库
还是以猫眼电影为例,这次用pyquery库进行爬取 1.简单demo,看看如何使用pyquery提取信息,并将提取到的数据进行组合 # coding: utf-8 # author: hmk impo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- 单线程多任务协程vip电影爬取
单线程多任务协程vip电影爬取 --仅供学习使用勿作商用如有违规后果自负!!! 这几天一直在使用python爬取电影,主要目的也是为了巩固前段时间强化学习的网络爬虫,也算是一个不错的检验吧,面对众 ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- Scrapy实战篇(七)之爬取爱基金网站基金业绩数据
本篇我们以scrapy+selelum的方式来爬取爱基金网站(http://fund.10jqka.com.cn/datacenter/jz/)的基金业绩数据. 思路:我们以http://fund.1 ...
随机推荐
- 纯手写SpringMVC到SpringBoot框架项目实战
引言 Spring Boot其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 通过这种方式,springboot ...
- shell实现每天0点备份mysql数据库
就两个文件, 本人学识尚浅,不解释,怕大佬喷. back.sh #/bin/bash MYSQLUSER=root MYSQLPWD=lizhenghua DATABASES=zskdb MYSQLD ...
- javaEE体系结构【转载】
转载自: http://blog.csdn.net/chjskarl/article/details/72629014?locationNum=3&fps=1 JavaEE是一套使用Java进 ...
- Python3 tkinter基础 Entry state 不可写 可以选 可复制的输入框
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- JMeter常用菜单以及设置
如何清空View Results Tree 先选中目标view results tree,然后在菜单上选择Run-->Clear https://stackoverflow.com/questi ...
- C# 截取 byte 字节 转字符串
byte[] byteArray = System.Text.Encoding.Default.GetBytes(content); Byte[] ThisByte = new Byte[1];Buf ...
- [蓝桥] 算法训练 K好数
时间限制:1.0s 内存限制:256.0MB 问题描述 如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数.求L位K进制数中K好数的数目.例如K = 4,L = ...
- Docker run 出现问题如何调试?
docker run -ti 3f5dd697cc83 /bin/bash #进入image的目录 ls -l #列出所有目录 dotnet run WestWin.Ads.Crawler.WebAp ...
- 接口Interface的四种含义
摘自<需求分析与系统设计(第3版)>第七章Q5 1. GUI——显示信息的计算机屏幕(注:其他终端) 2. API——是一套软件程序和开发工具,为应用程序提供函数调用,使程序可以访问一些级 ...
- Latex: 添加IEEE论文keywords
参考: How to use \IEEEkeywords Latex: 添加IEEE论文keywords 方法: \begin{IEEEkeywords} keyword1, keyword2. \e ...