Flume 概述+环境配置+监听Hive日志信息并写入到hdfs
Flume介绍
Flume是Apache基金会组织的一个提供的高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本,Flume 0.9x版本之前的统称为Flume-og,Flume1.X版本被统称为Flume-ng。
参考文档:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6/FlumeUserGuide.html
Flume-og和Flume-ng的区别
主要区别如下:
1. Flume-og中采用master结构,为了保证数据的一致性,引入zookeeper进行管理。Flume-ng中取消了集中master机制和zookeeper管理机制,变成了一个纯粹的传输工具。
2. Flume-ng中采用不同的线程进行数据的读写操作;在Flume-og中,读数据和写数据是由同一个线程操作的,如果写出比较慢的话,可能会阻塞flume的接收数据的能力。
Flume结构
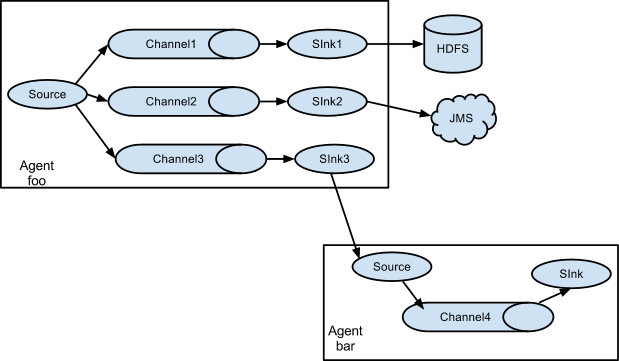
Flume中以Agent为基本单位,一个agent可以包括source、channel、sink,三种组件都可以有多个。其中source组件主要功能是接收外部数据,并将数据传递到channel中;sink组件主要功能是发送flume接收到的数据到目的地;channel的主要作用就是数据传输和保存的一个作用。Flume主要分为三类结构:单agent结构、多agent链式结构和多路复用agent结构。
单agent结构
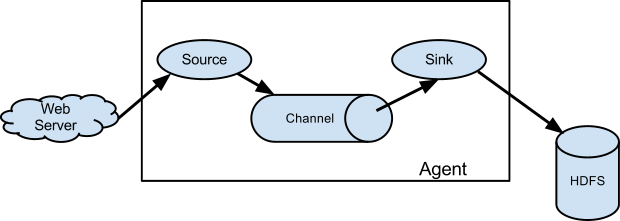
多agent链式结构
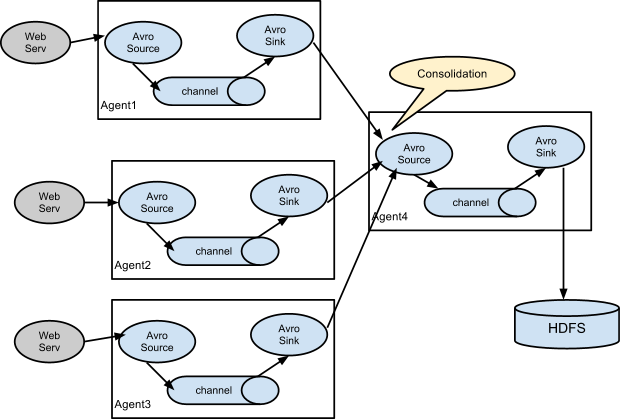
多路复用agent结构
Source介绍
Source的主要作用是接收客户端发送的数据,并将数据发送到channel中,source和channel之间的关系是多对多关系,不过一般情况下使用一个source对应多个channel。通过名称区分不同的source。Flume常用source有:Avro Source、Thrift Source、Exec Source、Kafka Source、Netcat Source等。设置格式如下:
<agent-name>.sources=source_names
<agent-name>.sources.<source_name>.type=指定类型
<agent-name>.sources.<source_name>.channels=channels
.... 其他对应source类型需要的参数
Channel介绍
Channel的主要作用是提供一个数据传输通道,提供数据传输和数据存储(可选)等功能。source将数据放到channel中,sink从channel中拿数据。通过不同的名称来区分channel。Flume常用channel有:Memory Channel、JDBC Channel、Kafka Channel、File Channel等。设置格式如下:
<agent-name>.channels=channel_names
<agent-name>.channels.<channel_name>.type=指定类型
.... 其他对应channel类型需要的参数
Sink介绍
Sink的主要作用是定义数据写出方式,一般情况下sink从channel中获取数据,然后将数据写出到file、hdfs或者网络上。channel和sink之间的关系是一对多的关系。通过不同的名称来区分sink。Flume常用sink有:
Hdfs Sink、Hive Sink、File Sink、HBase Sink、Avro Sink、Thrift Sink、Logger Sink等。
设置格式如下:
<agent-name>.sinks = sink_names
<agent-name>.sinks.<sink_name1>.type=指定类型
<agent-name>.sinks.<sink_name1>.channel=<channe_name>
.... 其他对应sink类型需要的参数
Flume中常用的source、channel、sink组件
1.2.2.1 source组件
|
Source类型 |
说明 |
|
Avro Source |
支持Avro协议(实际上是Avro RPC),内置支持 |
|
Thrift Source |
支持Thrift协议,内置支持 |
|
Exec Source |
基于Unix的command在标准输出上生产数据 |
|
JMS Source |
从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 |
|
Spooling Directory Source |
监控指定目录内数据变更 |
|
Twitter 1% firehose Source |
通过API持续下载Twitter数据,试验性质 |
|
Netcat Source |
监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
|
Sequence Generator Source |
序列生成器数据源,生产序列数据 |
|
Syslog Sources |
读取syslog数据,产生Event,支持UDP和TCP两种协议 |
|
HTTP Source |
基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
|
Legacy Sources |
兼容老的Flume OG中Source(0.9.x版本) |
1.2.2.2 Channel组件
|
Channel类型 |
说明 |
|
Memory Channel |
Event数据存储在内存中 |
|
JDBC Channel |
Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
|
File Channel |
Event数据存储在磁盘文件中 |
|
Spillable Memory Channel |
Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
|
Pseudo Transaction Channel |
测试用途 |
|
Custom Channel |
自定义Channel实现 |
1.2.2.3 sink组件
|
Sink类型 |
说明 |
|
HDFS Sink |
数据写入HDFS |
|
Logger Sink |
数据写入日志文件 |
|
Avro Sink |
数据被转换成Avro Event,然后发送到配置的RPC端口上 |
|
Thrift Sink |
数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
|
IRC Sink |
数据在IRC上进行回放 |
|
File Roll Sink |
存储数据到本地文件系统 |
|
Null Sink |
丢弃到所有数据 |
|
HBase Sink |
数据写入HBase数据库 |
|
Morphline Solr Sink |
数据发送到Solr搜索服务器(集群) |
|
ElasticSearch Sink |
数据发送到Elastic Search搜索服务器(集群) |
|
Kite Dataset Sink |
写数据到Kite Dataset,试验性质的 |
|
Custom Sink |
自定义Sink实现 |
Flume支持众多的source、channel、sink类型,详细手册可参考官方文档
Flume安装
安装步骤如下:
1. 下载flume:wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6.tar.gz
2. 解压flume。
3. 修改conf/flume-env.sh文件,如果没有就新建一个。
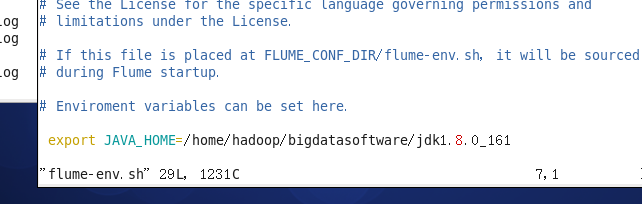
4. 添加flume的bin目录到环境变量中去。
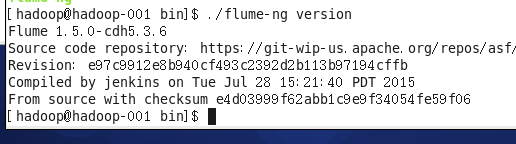
5. 验证是否安装成功, flume-ng version
监听Hive日志信息并写入到hdfs
1. 编写nginx配置信息
在hive根目录下创建log文件夹,
2. 编写flume的agent配置信息
配置如下
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /home/hadoop/bigdatasoftware/apache-hive-0.13.1-bin/log/hive.log #要监控的log文件
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop-001:9000/logs/%Y%m%d/%H0 #生成hdfs文件的目录格式
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
3. 移动hdfs依赖包到flume的lib文件夹中。
cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar ./
cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar ./
cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar ./
cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar ./
4. 进入flume根目录,启动
flume: ./bin/flume-ng agent --conf ./conf/ --name a2 --conf-file ./conf/flume-file-hdfs.conf
5.在hive上进行一系列操作
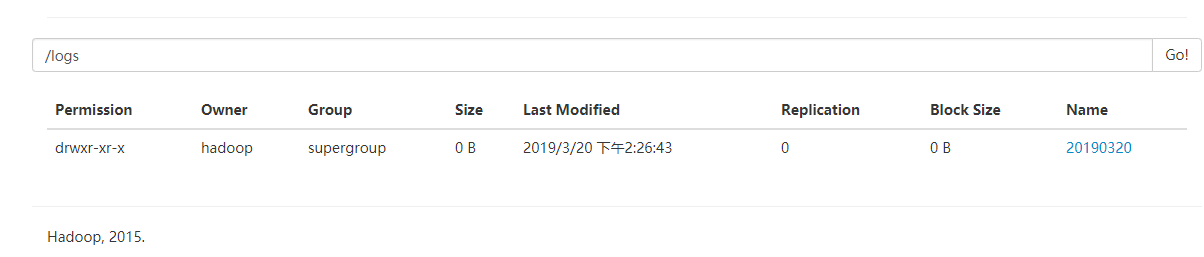
在hdfs上查看即可发现已生成文件
Flume 概述+环境配置+监听Hive日志信息并写入到hdfs的更多相关文章
- 涂抹Oracle笔记1-创建数据库及配置监听程序
一.安装ORACLE数据库软件及创建实例OLTP:online transaction processing 指那些短事务,高并发,读写频繁的数据库系统.--DB_BLOCK_SIZE通常设置较小.O ...
- ASP.NET Core中配置监听URLs的五种方式
原文: 5 ways to set the URLs for an ASP.NET Core app 作者: Andrew Lock 译者: Lamond Lu 默认情况下,ASP. NET Core ...
- Sprinboot优雅配置监听,并记录所有启动事件
在阅读Springboot启动源码的时候,发现Springboot自动启动listeners是通过uopeizhi文件配置的,本文就是采用Springboot方式自动装入listeners. 项目依赖 ...
- oracle 11g 服务启动时提示1053错误,服务启动不了,重新配置监听解决问题
早上发现oracle服务启动不了了,找了很多资料,没找到有用的.通过重新配置监听解决问题.
- 新建Oracle数据库时,提示使用database control配置数据库时,要求在当前oracle主目录中配置监听程序
新建一个oracle数据库时,当提示使用database control配置数据库时,要求在当前oracle主目录中配置监听程序等字样的时候,问题是那个监听的服务没有启动,解决方法如下: 打开cmd命 ...
- 12C cdb/pdb 配置监听
. PDB is not an instance, so using SID in the connection string will not work. When the database is ...
- spring中配置监听队列的MQ
一.spring中配置监听队列的MQ相关信息注:${}是读取propertites文件的常量,这里忽略.绿色部分配置在接收和发送端都要配置. <bean id="axx" ...
- Oracle 配置监听和本地网络服务
一.配置监听 在oracle的配置和移植工具中打开Net Configuration Assistant,然后点击下一步. 点击下一步,然后输入监听的名称点击下一步 点击下一步后如图 点击下一步如图 ...
- oracle12安装软件后安装数据库,然后需要自己配置监听
oracle12安装软件后安装数据库,然后需要自己配置监听 没想到你是这样的oracle12: 不能同时安装软件和数据库,分别安装之后,\NETWORD\ADMIN\下面竟然没有listener.or ...
随机推荐
- elasticsearch.in.sh优化内存
elasticsearch.in.sh文件主要是内存优化 ES_MIN_MEM=24g(24g是物理内存的一半) ES_MAX_MEM=24g ES调优: 1.Java层面的调优,加大JVM的可用内存 ...
- python基础操作以及其常用内置方法
#可变类型: 值变了,但是id没有变,证明没有生成新的值而是在改变原值,原值是可变类型#不可变类型:值变了,id也跟着变,证明是生成了新的值而不是在改变原值,原值是不可变 # x=10# print( ...
- java学习笔记5(方法)
方法: 1.如何创建方法 修饰符 返回值类型 方法名(参数){被封装的代码段} 2.方法的定义和使用的注意事项: a:方法不能定义在另一个方法里面: b:方法 名字和方法的参数列表,定义和调用时 ...
- mysqli扩展库的预处理
预处理的特点:1.效率高,执行速度快 2.安全性高,可以防止sql注入 $mysqli 中的函数 $stmt=$mysqli->prepare($sql); 预备一条s ...
- Dalvik源码阅读笔记(一)
dalvik 虚拟机启动入口在 JNI_CreateJavaVM(), 在进行完 JNIEnv 等环境设置后,调用 dvmStartup() 函数进行真正的 DVM 初始化. jint JNI_Cre ...
- c#网站文件下载次数统计
参考:http://q.cnblogs.com/q/17954/ 项目中需要准确记录文件的下载次数,和帖子的要求差不多. 参考了帖子中推荐的链接,问题得到了有效控制. 大概方法:逐字节(大小可以自己控 ...
- xdoj-1324 (区间离散化-线段树求区间最值)
思想 : 1 优化:题意是覆盖点,将区间看成 (l,r)转化为( l-1,r) 覆盖区间 2 核心:dp[i] 覆盖从1到i区间的最小花费 dp[a[i].r]=min (dp[k])+a[i]s; ...
- Automatic Text Difficulty Classifier Assisting the Selection Of Adequate Reading Materials For European Portuguese Teaching --paper
the system uses existing Natural Language Processing (NLP) tools, a parser and an hyphenator, and tw ...
- 更换JDK版本时的问题:Error: could not open `C:\Java\jre7\lib\amd64\jvm.cfg'
1.先把oracle自带的weblogic给卸载了,然后打开eclipse,发现报错了:Error: could not open `C:\Java\jre7\lib\amd64\jvm.cfg' J ...
- rest-framework之响应器(渲染器)
rest-framework之响应器(渲染器) 本文目录 一 作用 二 内置渲染器 三 局部使用 四 全局使用 五 自定义显示模版 回到目录 一 作用 根据 用户请求URL 或 用户可接受的类型,筛选 ...