【Hive学习之二】Hive SQL
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
apache-hive-3.1.1
参考:官网hive操作手册
一、DDL
1、数据类型
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7. and later) primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2. and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8. and later)
| TIMESTAMP -- (Note: Available in Hive 0.8. and later)
| DECIMAL -- (Note: Available in Hive 0.11. and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13. and later)
| DATE -- (Note: Available in Hive 0.12. and later)
| VARCHAR -- (Note: Available in Hive 0.12. and later)
| CHAR -- (Note: Available in Hive 0.13. and later) array_type
: ARRAY < data_type > map_type
: MAP < primitive_type, data_type > struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...> union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7. and later)
2、数据库的创建、删除、修改;
3、表的创建、删除、修改;
举例:创建表
hive>CREATE TABLE person(
id INT,
name STRING,
age INT,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
查看表结构:
hive> desc person;
OK
id int
name string
age int
likes array<string>
address map<string,string>
Time taken: 0.095 seconds, Fetched: row(s)
hive> desc formatted person;
OK
# col_name data_type comment
id int
name string
age int
likes array<string>
address map<string,string> # Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Tue Jan :: CST
LastAccessTime: UNKNOWN
Retention:
Location: hdfs://PCS102:9820/root/hive_remote/warehouse/person
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"address\":\"true\",\"age\":\"true\",\"id\":\"true\",\"likes\":\"true\",\"name\":\"true\"}}
bucketing_version
numFiles
numRows
rawDataSize
totalSize
transient_lastDdlTime # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
collection.delim -
field.delim ,
line.delim \n
mapkey.delim :
serialization.format ,
Time taken: 0.157 seconds, Fetched: row(s)
向表内加载数据:
data:
,小明1,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明2,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明3,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明4,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明5,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明6,,lol-book-movie,beijing:shangxuetang-shanghai:pudong
hive> LOAD DATA LOCAL INPATH '/root/data' INTO TABLE person;
Loading data to table default.person
OK
Time taken: 0.185 seconds
hive> select * from person;
OK
小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明2 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明3 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明4 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明5 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明6 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
Time taken: 0.126 seconds, Fetched: row(s)
hive>
备注:向表导入数据最好按照表定义的结构来安排数据,如果不按照这个格式,文件也能上传到HDFS,这是通过hive select查看的时候查不出来,无法格式化输出。
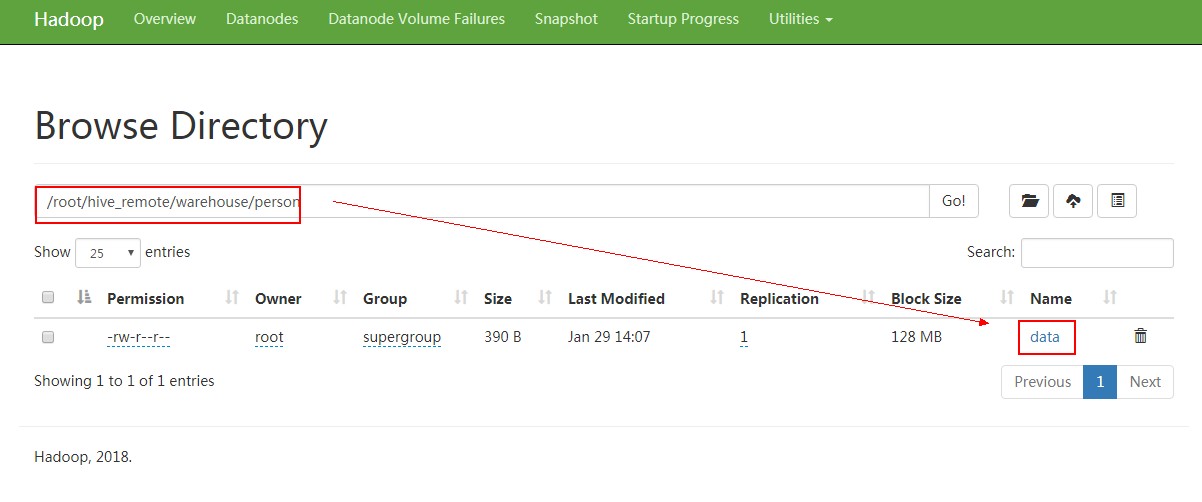
struct类型:
数据 /root/data:
,xiaoming:
,xiaohong:
建表 从linux本地文件系统导入数据:
hive> create table student(
> id int,
> info STRUCT <name:string,age:int>
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':'
> ;
OK
Time taken: 0.712 seconds
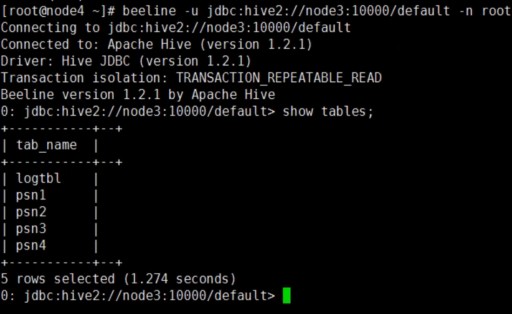
hive> show tables;
OK
logtbl
person
person3
psn2
psn3
psn4
student
test01
Time taken: 0.1 seconds, Fetched: row(s)
hive> load data local inpath '/root/data' into table student;
Loading data to table default.student
OK
Time taken: 0.365 seconds
hive> select * from student;
OK
1 {"name":"xiaoming","age":12}
2 {"name":"xiaohong","age":11}
Time taken: 1.601 seconds, Fetched: row(s)
hive>
对比从hdfs导入数据:
先上传文件到hdfs 根目录:
[root@PCS102 ~]# hdfs dfs -put data /
[root@PCS102 ~]#
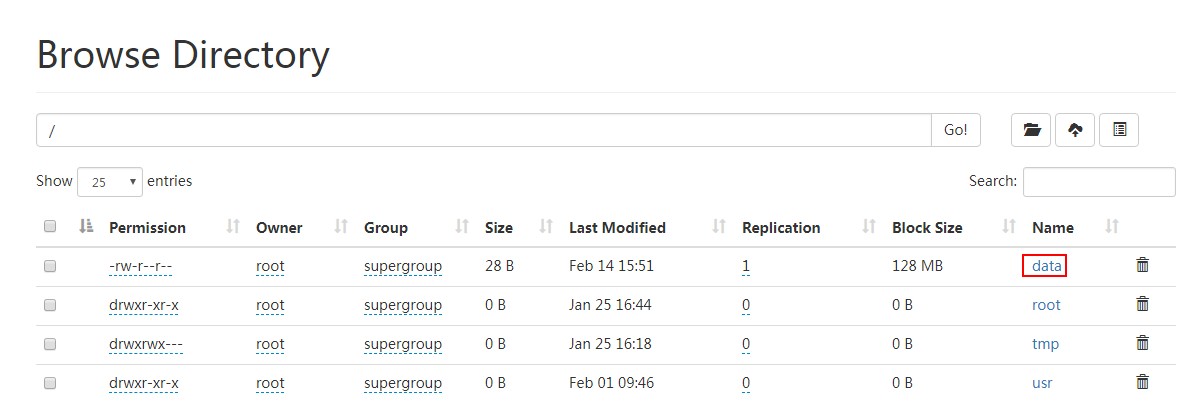
去掉 local:
hive> load data inpath '/data' into table student;
Loading data to table default.student
OK
Time taken: 0.161 seconds
hive> select * from student;
OK
1 {"name":"xiaoming","age":12}
2 {"name":"xiaohong","age":11}
1 {"name":"xiaoming","age":12}
2 {"name":"xiaohong","age":11}
Time taken: 0.118 seconds, Fetched: row(s)
hive>
导入之后,hdfs根目录下data文件被移动(注意不是复制)到student下面:
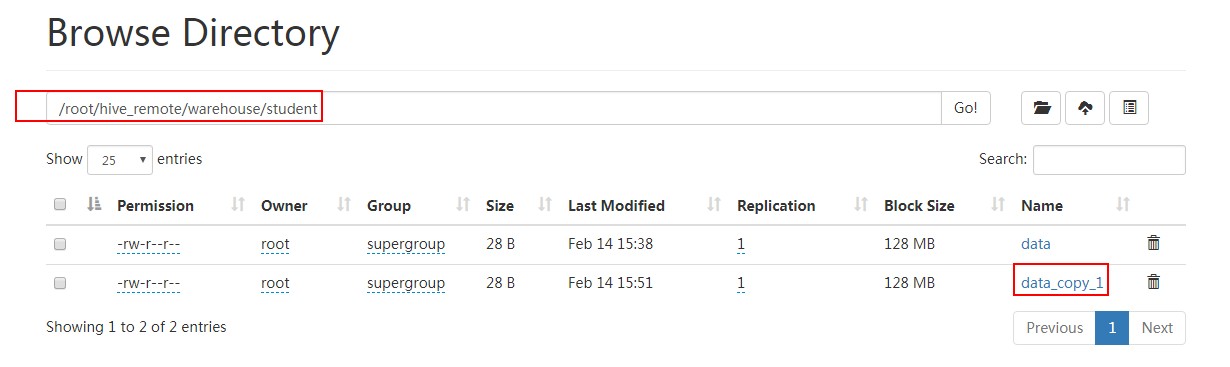
Hive 内部表:CREATE TABLE [IF NOT EXISTS] table_name,删除表时,元数据与数据都会被删除
Hive 外部表:CREATE EXTERNAL TABLE [IF NOT EXISTS] table_name LOCATION hdfs_path,删除外部表只删除metastore的元数据,不删除hdfs中的表数据
举例:
CREATE EXTERNAL TABLE person3(
id INT,
name STRING,
age INT,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
LOCATION '/usr/';
Hive 建表
Create Table Like:
CREATE TABLE empty_key_value_store LIKE key_value_store;
Create Table As Select (CTAS):
CREATE TABLE new_key_value_store
AS
SELECT columA, columB FROM key_value_store;
4、分区 提高查询效率,根据需求确定分区
(1)创建分区(分区字段不能再表的列中)
举例:
CREATE TABLE psn2(
id INT,
name STRING,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)
PARTITIONED BY (age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'; 否则报错:
FAILED: SemanticException [Error ]: Column repeated in partitioning columns
hive> CREATE TABLE psn2(
> id INT,
> name STRING,
> likes ARRAY<STRING>,
> address MAP<STRING,STRING>
> )
> PARTITIONED BY (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY '-'
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.167 seconds
hive> desc psn2;
OK
id int
name string
likes array<string>
address map<string,string>
age int # Partition Information
# col_name data_type comment
age int
Time taken: 0.221 seconds, Fetched: row(s)
hive>
导入数据:
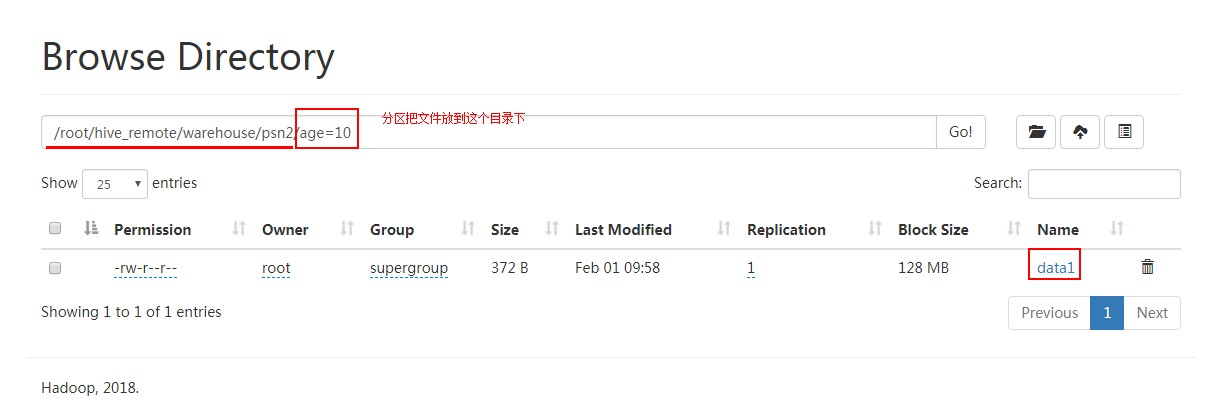
hive> LOAD DATA LOCAL INPATH '/root/data1' INTO TABLE psn2 partition (age=);
Loading data to table default.psn2 partition (age=)
OK
Time taken: 0.678 seconds
hive> select * from psn2;
OK
小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明2 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明3 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明4 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明5 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明6 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
Time taken: 1.663 seconds, Fetched: row(s)
hive>
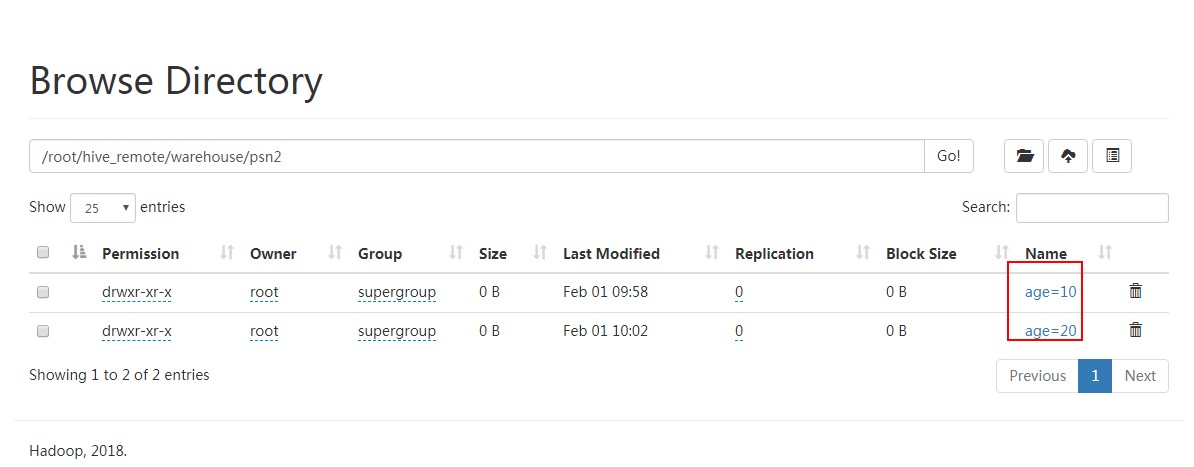
hive> LOAD DATA LOCAL INPATH '/root/data1' INTO TABLE psn2 partition (age=);
Loading data to table default.psn2 partition (age=)
OK
Time taken: 0.36 seconds
hive>
(2)修改分区
创建分区:
hive> CREATE TABLE psn3(
> id INT,
> name STRING,
> likes ARRAY<STRING>,
> address MAP<STRING,STRING>
> )
> PARTITIONED BY (age int,sex string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY '-'
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.061 seconds
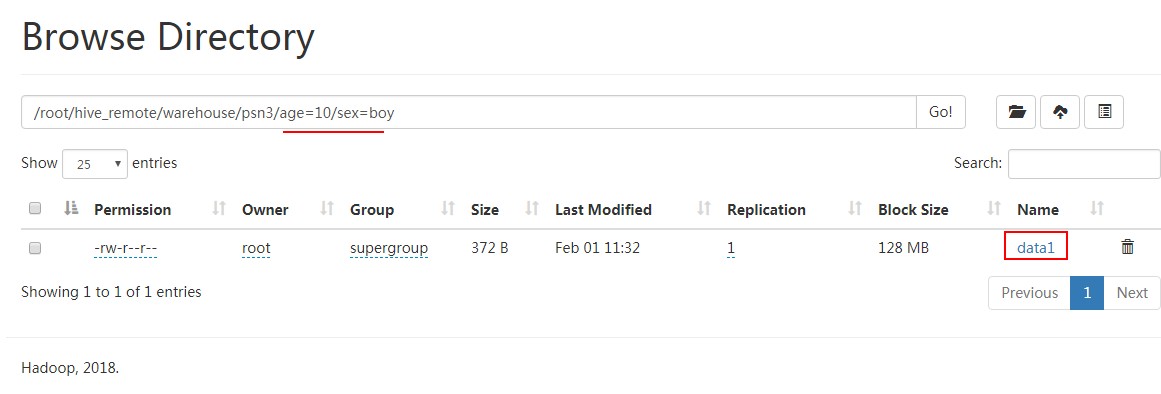
导入数据:
hive> LOAD DATA LOCAL INPATH '/root/data1' INTO TABLE psn3 partition (age=10,sex='boy');
Loading data to table default.psn3 partition (age=, sex=boy)
OK
Time taken: 0.351 seconds
hive> LOAD DATA LOCAL INPATH '/root/data1' INTO TABLE psn3 partition (age=20,sex='boy');
Loading data to table default.psn3 partition (age=, sex=boy)
OK
Time taken: 0.339 seconds
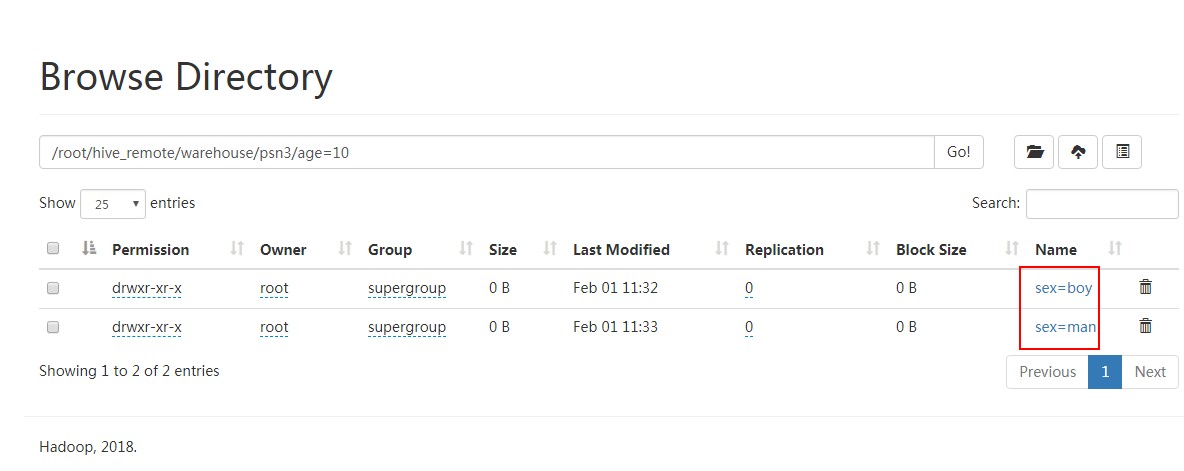
增加分区:
hive> alter table psn3 add partition (age=10,sex='man');
OK
Time taken: 0.1 seconds
hive> alter table psn3 add partition (age=20,sex='man');
OK
Time taken: 0.067 seconds
删除分区:
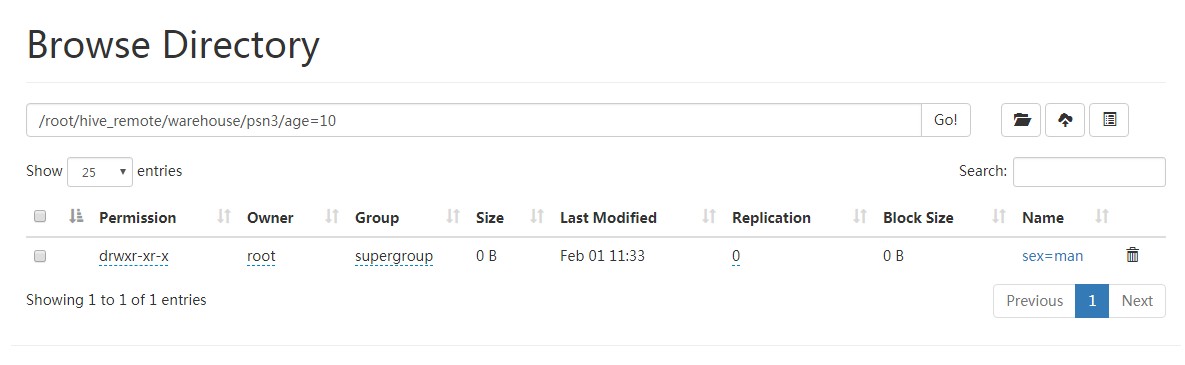
hive> alter table psn3 drop partition (sex='boy');
Dropped the partition age=10/sex=boy
Dropped the partition age=20/sex=boy
OK
Time taken: 0.472 seconds
hive>
二、DML
导入数据
1、load 其实就是hdfs dfs -put 上传文件
2、insert 插入数据,作用:(1)复制表;(2)中间表;(3)向不同表插入不同数据
CREATE TABLE psn4(
id INT,
name STRING,
likes ARRAY<STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
LINES TERMINATED BY '\n'; from psn3
insert overwrite table psn4
select id,name,likes;
或者
from psn3
insert overwrite table psn4
select id,name,likes
insert overwrite table psn5
select id,name;
三、Hive SerDe - Serializer and Deserializer
SerDe 用于做序列化和反序列化。
构建在数据存储和执行引擎之间,对两者实现解耦。
Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写。
row_format
: DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
: SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
建表:
hive> CREATE TABLE logtbl (
> host STRING,
> identity STRING,
> t_user STRING,
> a_time STRING,
> request STRING,
> referer STRING,
> agent STRING)
> ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
> WITH SERDEPROPERTIES (
> "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
> )
> STORED AS TEXTFILE;
OK
Time taken: 0.059 seconds
数据:
192.168.57.4 - - [/Feb/::: +] "GET /bg-upper.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-nav.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /asf-logo.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-button.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-middle.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET / HTTP/1.1"
192.168.57.4 - - [/Feb/::: +] "GET / HTTP/1.1"
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.css HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /asf-logo.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-middle.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-button.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-nav.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-upper.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET / HTTP/1.1"
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.css HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET / HTTP/1.1"
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.css HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /tomcat.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-button.png HTTP/1.1" -
192.168.57.4 - - [/Feb/::: +] "GET /bg-upper.png HTTP/1.1" -
导入数据:
hive> load data local inpath '/root/log' into table logtbl;
Loading data to table default.logtbl
OK
Time taken: 0.137 seconds
查询数据:
hive> select * from logtbl;
OK
192.168.57.4 - - /Feb/::: + GET /bg-upper.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-nav.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /asf-logo.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-button.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-middle.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET / HTTP/1.1
192.168.57.4 - - /Feb/::: + GET / HTTP/1.1
192.168.57.4 - - /Feb/::: + GET /tomcat.css HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /tomcat.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /asf-logo.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-middle.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-button.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-nav.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-upper.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET / HTTP/1.1
192.168.57.4 - - /Feb/::: + GET /tomcat.css HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /tomcat.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET / HTTP/1.1
192.168.57.4 - - /Feb/::: + GET /tomcat.css HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /tomcat.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-button.png HTTP/1.1 -
192.168.57.4 - - /Feb/::: + GET /bg-upper.png HTTP/1.1 -
Time taken: 0.102 seconds, Fetched: row(s)
hive>
四、Beeline 和hive作用相同另外一种方式,主要作用输出类似二维表格(mysql控制台风格)
/usr/local/apache-hive-3.1.1-bin/bin/beeline 要与/usr/local/apache-hive-3.1.1-bin/bin/HiveServer2配合使用
首先,服务端启动hiveserver2
然后,客户端通过beeline两种方式连接到hive
1、beeline -u jdbc:hive2://localhost:10000/default -n root
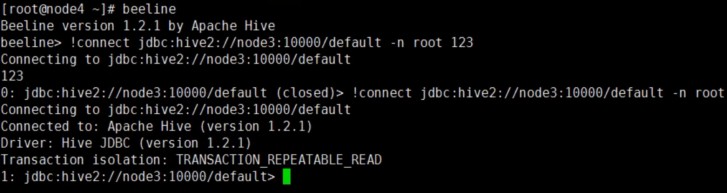
2、beeline
beeline> !connect jdbc:hive2://<host>:<port>/<db>;auth=noSasl root 123
默认 用户名、密码不验证,命令行使用命令前面加!
退出使用:!quit
五、Hive JDBC
Hive JDBC运行方式
服务端启动hiveserver2后,在java代码中通过调用hive的jdbc访问默认端口10000进行连接、访问
package test.hive; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement; public class HiveJdbcClient { private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} Connection conn = DriverManager.getConnection("jdbc:hive2://134.32.123.102:10000/default", "root", "");
Statement stmt = conn.createStatement();
String sql = "select * from psn2 limit 5";
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "-" + res.getString("name"));
}
} }
【Hive学习之二】Hive SQL的更多相关文章
- MyBatis学习 之 二、SQL语句映射文件(2)增删改查、参数、缓存
目录(?)[-] 二SQL语句映射文件2增删改查参数缓存 select insert updatedelete sql parameters 基本类型参数 Java实体类型参数 Map参数 多参数的实 ...
- MyBatis学习 之 二、SQL语句映射文件(1)resultMap
目录(?)[-] 二SQL语句映射文件1resultMap resultMap idresult constructor association联合 使用select实现联合 使用resultMap实 ...
- Hive学习笔记二
目录 Hive常见属性配置 将本地库文件导入Hive案例 Hive常用交互命令 Hive其他命令操作 参数配置方式 Hive常见属性配置 1.Hive数据仓库位置配置 1)Default数据仓库的最原 ...
- Hive学习之二 《Hive的安装之自定义mysql数据库》
由于MySQL便于管理,在学习过程中,我选择MySQL. 一,配置元数据库. 1.安装MySQL,采用yum方式. ①yum install mysql-server,安装mysql服务端,安装服 ...
- Hive学习之六 《Hive进阶— —hive jdbc》 详解
接Hive学习五 http://www.cnblogs.com/invban/p/5331159.html 一.配置环境变量 hive jdbc的开发,在开发环境中,配置Java环境变量 修改/etc ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- 【Hive学习之八】Hive 调优【重要】
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- 【Hive学习之七】Hive 运行方式&权限管理
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- 【Hive学习之一】Hive简介
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
随机推荐
- 如何使用Beyond Compare 对比差异文件【制作Patch(补丁包)文件】
场景:研发部的代码从SVN变更至GIt,通过Jenkins每天自动生成程序包. 如需要获取单独的程序包更新,而不是整个程序包覆盖更新,这时候就需要用到Beyond Compare 对比工具 操作步骤1 ...
- 【python基础】sys
sys模块 参考: https://blog.csdn.net/qq_38526635/article/details/81739321 http://www.cnblogs.com/cherishr ...
- byte数组存储到mysql
public int AddVeinMessage(byte[] data)//插入数据库 { using (BCSSqlConnection = new MySqlConnection(strCon ...
- 重读《深入理解Java虚拟机》二、Java如何分配和回收内存?Java垃圾收集器如何工作?
线程私有的内存区域随用户线程的结束而回收,内存分配编译期已确定,内存分配和回收具有确定性.共享线程随虚拟机的启动.结束而建立和销毁,在运行期进行动态分配.垃圾收集器主要对共享内存区域(堆和方法区)进行 ...
- 对web标准化(或网站重构)知道哪些相关的知识,简述几条你知道的Web标准?
网页主要有三部分组成:结构(Structrue).表现(Presentation)和行为(Behavior).对应的网站标准也分为三方面: 1.结构化标准语言,主要包括XHTML和XML: 2.表现标 ...
- mysql命令行各个参数解释
mysql命令行各个参数解释 http://blog.51yip.com/mysql/1056.html Usage: mysql [OPTIONS] [database] //命令方式 -?, ...
- 小程序-formdata传参
项目背景,后端接口要求formData传参: 在util.js文件中封装转化函数,代码如下: const formatTime = date => { const year = date.get ...
- awesome vue
https://blog.csdn.net/caijunfen/article/details/78216868
- java.lang.SecurityException: Permission Denial: writing android.support.v4.content.FileProvider uri
在使用红米手机拍摄照片时,出现闪退的情况. 调用系统相机拍摄照片,使用FileProvider.getUriForFile传入Uri时,报异常 java.lang.SecurityException: ...
- MJExtension代码解释
Runtime 是什么? objective-C会把函数调用的转换为消息发送,objc_MsgSend(receiver, msg), 注意,recevier指的是消息的接受者.那么self, sup ...