Storm流处理项目案例
1.项目框架
======================程序需要一步一步的调试=====================
一:第一步,KafkaSpout与驱动类
1.此时启动的服务有
2.主驱动类
package com.jun.it2; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.TopologyBuilder;
import storm.kafka.*; import java.util.UUID; public class WebLogStatictis {
/**
* 主函数
* @param args
*/
public static void main(String[] args) {
WebLogStatictis webLogStatictis=new WebLogStatictis();
StormTopology stormTopology=webLogStatictis.createTopology();
Config config=new Config();
//集群或者本地
//conf.setNumAckers(4);
if(args == null || args.length == 0){
// 本地执行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("webloganalyse", config , stormTopology);
}else{
// 提交到集群上执行
config.setNumWorkers(4); // 指定使用多少个进程来执行该Topology
try {
StormSubmitter.submitTopology(args[0],config, stormTopology);
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} }
/**
* 构造一个kafkaspout
* @return
*/
private IRichSpout generateSpout(){
BrokerHosts hosts = new ZkHosts("linux-hadoop01.ibeifeng.com:2181");
String topic = "nginxlog";
String zkRoot = "/" + topic;
String id = UUID.randomUUID().toString();
SpoutConfig spoutConf = new SpoutConfig(hosts,topic,zkRoot,id);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme()); // 按字符串解析
spoutConf.forceFromStart = true;
KafkaSpout kafkaSpout = new KafkaSpout(spoutConf);
return kafkaSpout;
} public StormTopology createTopology() {
TopologyBuilder topologyBuilder=new TopologyBuilder();
//指定Spout
topologyBuilder.setSpout(WebLogConstants.KAFKA_SPOUT_ID,generateSpout());
//
topologyBuilder.setBolt(WebLogConstants.WEB_LOG_PARSER_BOLT,new WebLogParserBolt()).shuffleGrouping(WebLogConstants.KAFKA_SPOUT_ID); return topologyBuilder.createTopology();
} }
3.WebLogParserBolt
这个主要的是打印Kafka的Spout发送的数据是否正确。
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple; import java.util.Map; public class WebLogParserBolt implements IRichBolt {
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { } @Override
public void execute(Tuple tuple) {
String webLog=tuple.getStringByField("str");
System.out.println(webLog);
} @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
4.运行Main
先消费在Topic中的数据。

5.运行kafka的生产者
bin/kafka-console-producer.sh --topic nginxlog --broker-list linux-hadoop01.ibeifeng.com:9092
6.拷贝数据到kafka生产者控制台
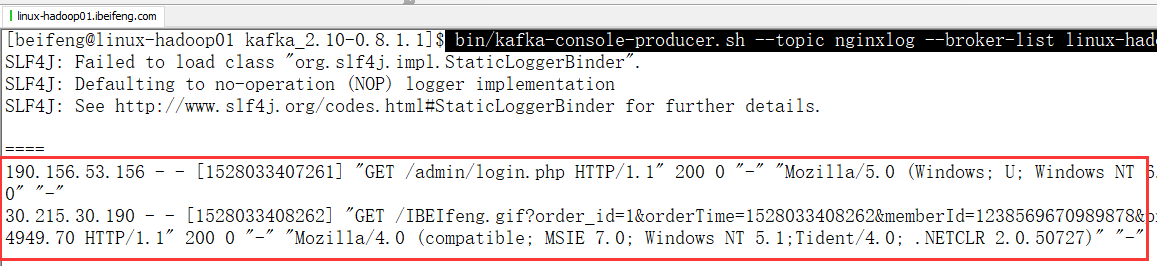
7.Main下面控制台的程序

二:第二步,解析Log
1.WebLogParserBolt
如果要是验证,就删除两个部分,打开一个注释:
删掉分流
删掉发射
打开打印的注释。
2.效果
这个只要启动Main函数就可以验证。
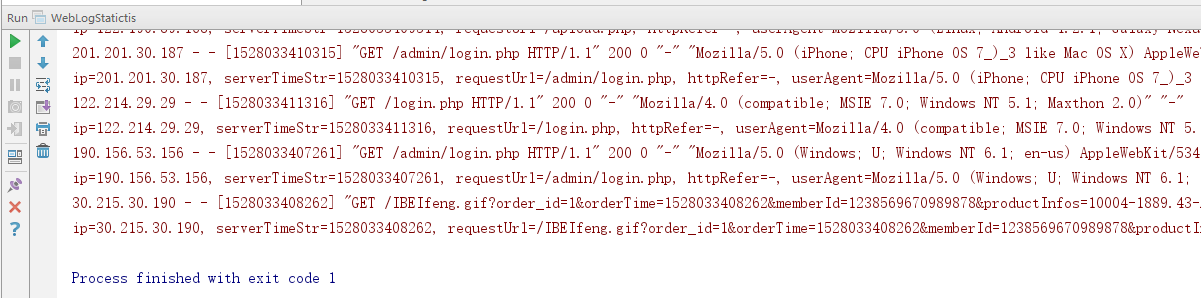
3.WebLogParserBolt
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import static com.jun.it2.WebLogConstants.*; public class WebLogParserBolt implements IRichBolt {
private Pattern pattern; private OutputCollector outputCollector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
pattern = Pattern.compile("([^ ]*) [^ ]* [^ ]* \\[([\\d+]*)\\] \\\"[^ ]* ([^ ]*) [^ ]*\\\" \\d{3} \\d+ \\\"([^\"]*)\\\" \\\"([^\"]*)\\\" \\\"[^ ]*\\\"");
this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String webLog=tuple.getStringByField("str");
if(webLog!= null || !"".equals(webLog)){ Matcher matcher = pattern.matcher(webLog);
if(matcher.find()){
//
String ip = matcher.group(1);
String serverTimeStr = matcher.group(2); // 处理时间
long timestamp = Long.parseLong(serverTimeStr);
Date date = new Date();
date.setTime(timestamp); DateFormat df = new SimpleDateFormat("yyyyMMddHHmm");
String dateStr = df.format(date);
String day = dateStr.substring(0,8);
String hour = dateStr.substring(0,10);
String minute = dateStr ; String requestUrl = matcher.group(3);
String httpRefer = matcher.group(4);
String userAgent = matcher.group(5); //可以验证是否匹配正确
// System.err.println(webLog);
// System.err.println(
// "ip=" + ip
// + ", serverTimeStr=" + serverTimeStr
// +", requestUrl=" + requestUrl
// +", httpRefer=" + httpRefer
// +", userAgent=" + userAgent
// ); //分流
this.outputCollector.emit(WebLogConstants.IP_COUNT_STREAM, tuple,new Values(day, hour, minute, ip));
this.outputCollector.emit(WebLogConstants.URL_PARSER_STREAM, tuple,new Values(day, hour, minute, requestUrl));
this.outputCollector.emit(WebLogConstants.HTTPREFER_PARSER_STREAM, tuple,new Values(day, hour, minute, httpRefer));
this.outputCollector.emit(WebLogConstants.USERAGENT_PARSER_STREAM, tuple,new Values(day, hour, minute, userAgent));
}
}
this.outputCollector.ack(tuple); } @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declareStream(WebLogConstants.IP_COUNT_STREAM,new Fields(DAY, HOUR, MINUTE, IP));
outputFieldsDeclarer.declareStream(WebLogConstants.URL_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, REQUEST_URL));
outputFieldsDeclarer.declareStream(WebLogConstants.HTTPREFER_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, HTTP_REFER));
outputFieldsDeclarer.declareStream(WebLogConstants.USERAGENT_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, USERAGENT));
} @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
三:第三步,通用计数器
1.CountKpiBolt
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; public class CountKpiBolt implements IRichBolt { private String kpiType; private Map<String,Integer> kpiCounts; private String currentDay = ""; private OutputCollector outputCollector; public CountKpiBolt(String kpiType){
this.kpiType = kpiType;
} @Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.kpiCounts = new HashMap<>();
this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String day = tuple.getStringByField("day");
String hour = tuple.getStringByField("hour");
String minute = tuple.getStringByField("minute");
String kpi = tuple.getString(3);
//日期与KPI组合
String kpiByDay = day + "_" + kpi;
String kpiByHour = hour +"_" + kpi;
String kpiByMinute = minute + "_" + kpi;
//将计数信息存放到Map中
int kpiCountByDay = 0;
int kpiCountByHour = 0;
int kpiCountByMinute = 0;
if(kpiCounts.containsKey(kpiByDay)){
kpiCountByDay = kpiCounts.get(kpiByDay);
}
if(kpiCounts.containsKey(kpiByHour)){
kpiCountByHour = kpiCounts.get(kpiByHour);
}
if(kpiCounts.containsKey(kpiByMinute)){
kpiCountByMinute = kpiCounts.get(kpiByMinute);
}
kpiCountByDay ++;
kpiCountByHour ++;
kpiCountByMinute ++;
kpiCounts.put(kpiByDay, kpiCountByDay);
kpiCounts.put(kpiByHour, kpiCountByHour);
kpiCounts.put(kpiByMinute,kpiCountByMinute);
//隔天清空内存
if(!currentDay.equals(day)){
// 说明隔天了
Iterator<Map.Entry<String,Integer>> iter = kpiCounts.entrySet().iterator();
while(iter.hasNext()){
Map.Entry<String,Integer> entry = iter.next();
if(entry.getKey().startsWith(currentDay)){
iter.remove();
}
}
}
currentDay = day;
//发射
//发射两个字段
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByDay, kpiCountByDay));
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByHour, kpiCountByHour));
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByMinute, kpiCountByMinute));
this.outputCollector.ack(tuple); } @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields(WebLogConstants.SERVERTIME_KPI, WebLogConstants.KPI_COUNTS));
} @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
2.saveBolt.java
主要是打印功能。
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple; import java.util.Map; public class SaveBolt implements IRichBolt { @Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { } @Override
public void execute(Tuple tuple) {
String serverTimeAndKpi = tuple.getStringByField(WebLogConstants.SERVERTIME_KPI);
Integer kpiCounts = tuple.getIntegerByField(WebLogConstants.KPI_COUNTS);
System.err.println("serverTimeAndKpi=" + serverTimeAndKpi + ", kpiCounts=" + kpiCounts);
} @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
3.效果
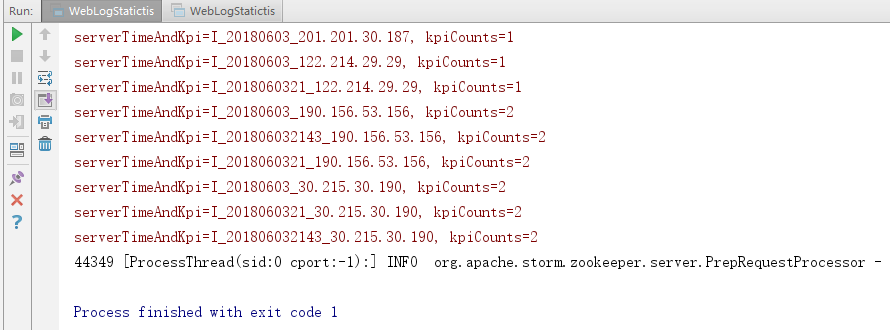
四:保存到HBase中
1.saveBolt.java
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException;
import java.util.Map; import static com.jun.it2.WebLogConstants.HBASE_TABLENAME; public class SaveBolt implements IRichBolt {
private HTable table; private OutputCollector outputCollector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
Configuration configuration = HBaseConfiguration.create();
try {
table = new HTable(configuration,HBASE_TABLENAME);
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
} this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String serverTimeAndKpi = tuple.getStringByField(WebLogConstants.SERVERTIME_KPI);
Integer kpiCounts = tuple.getIntegerByField(WebLogConstants.KPI_COUNTS);
// System.err.println("serverTimeAndKpi=" + serverTimeAndKpi + ", kpiCounts=" + kpiCounts);
if(serverTimeAndKpi!= null && kpiCounts != null){ Put put = new Put(Bytes.toBytes(serverTimeAndKpi));
String columnQuelifier = serverTimeAndKpi.split("_")[0];
put.add(Bytes.toBytes(WebLogConstants.COLUMN_FAMILY),
Bytes.toBytes(columnQuelifier),Bytes.toBytes(""+kpiCounts)); try {
table.put(put);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
this.outputCollector.ack(tuple);
} @Override
public void cleanup() {
if(table!= null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
2.当前服务
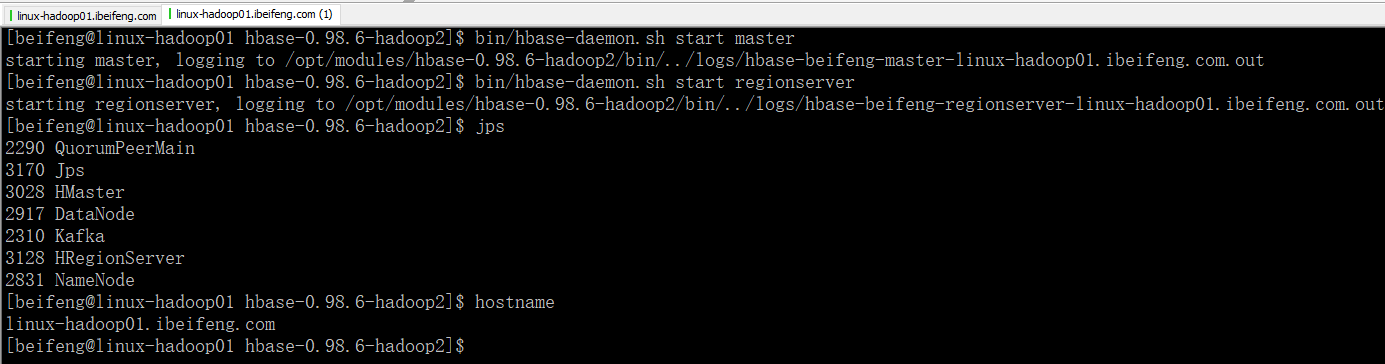
3.进入Hbase建表
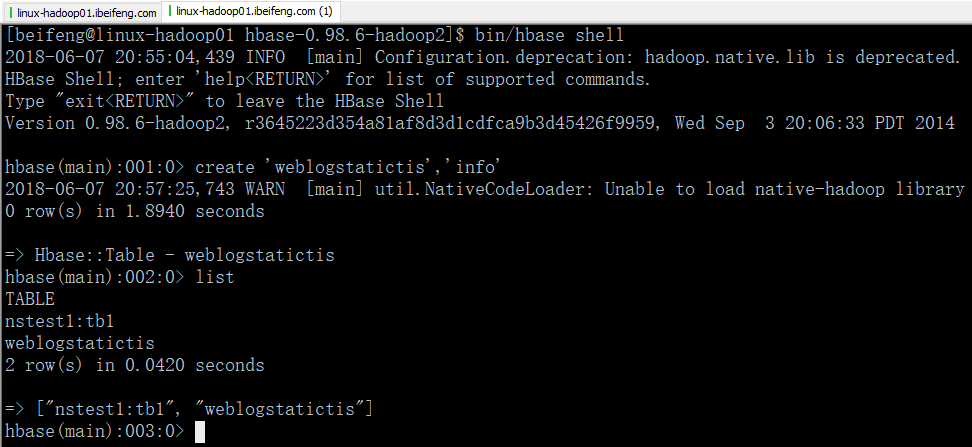
4.运行程序
出现报错信息
ERROR org.apache.hadoop.util.Shell - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:104) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.Groups.<init>(Groups.java:86) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.Groups.<init>(Groups.java:66) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:280) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:269) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:246) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:775) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:760) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:633) [hadoop-common-2.5.0-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.security.User$SecureHadoopUser.<init>(User.java:260) [hbase-common-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.security.User$SecureHadoopUser.<init>(User.java:256) [hbase-common-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.security.User.getCurrent(User.java:160) [hbase-common-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.security.UserProvider.getCurrent(UserProvider.java:89) [hbase-common-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.client.HConnectionKey.<init>(HConnectionKey.java:70) [hbase-client-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.client.HConnectionManager.getConnection(HConnectionManager.java:267) [hbase-client-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.client.HTable.<init>(HTable.java:199) [hbase-client-0.98.6-cdh5.3.6.jar:na]
at org.apache.hadoop.hbase.client.HTable.<init>(HTable.java:161) [hbase-client-0.98.6-cdh5.3.6.jar:na]
at com.jun.it2.SaveBolt.prepare(SaveBolt.java:27) [classes/:na]
at backtype.storm.daemon.executor$fn__3439$fn__3451.invoke(executor.clj:699) [storm-core-0.9.6.jar:0.9.6]
at backtype.storm.util$async_loop$fn__460.invoke(util.clj:461) [storm-core-0.9.6.jar:0.9.6]
at clojure.lang.AFn.run(AFn.java:24) [clojure-1.5.1.jar:na]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_144]
5.网上的解决方
1.下载winutils的windows版本
GitHub上,有人提供了winutils的windows的版本,项目地址是:https://github.com/srccodes/hadoop-common-2.2.0-bin,直接下载此项目的zip包,下载后是文件名是hadoop-common-2.2.0-bin-master.zip,随便解压到一个目录
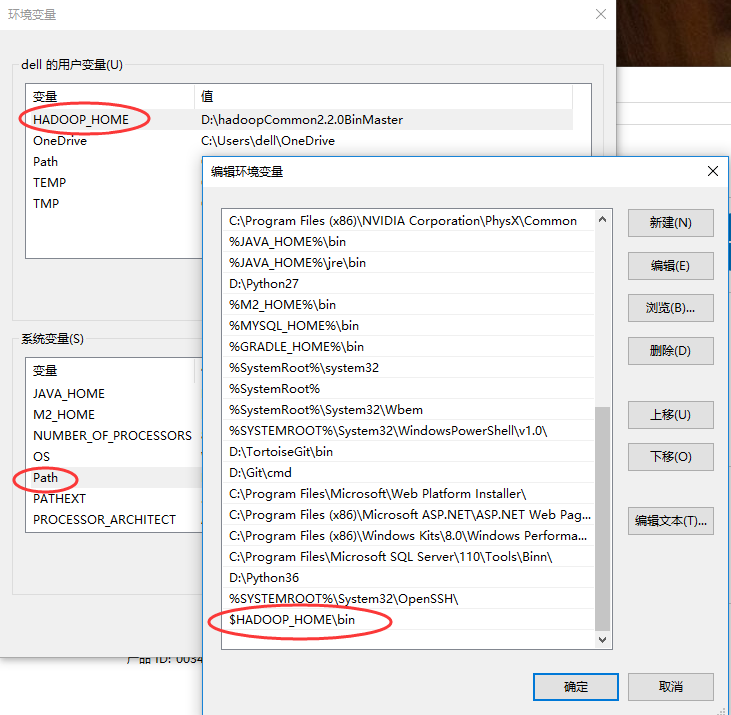
2.配置环境变量
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加$HADOOP_HOME\bin 即可。
再次运行程序,正常执行。
6.截图
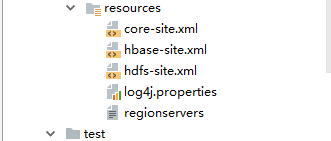
7.添加配置文件
这个是必须的,在window下面。
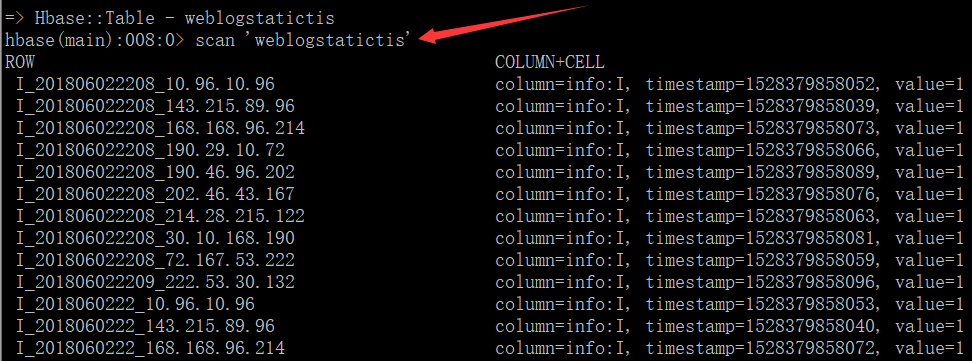
8.最终执行效果
五:PS---程序
1.主驱动类
package com.jun.it2; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import org.apache.hadoop.fs.Path;
import storm.kafka.*; import java.io.File;
import java.io.IOException;
import java.util.UUID; public class WebLogStatictis { /**
* 主函数
* @param args
*/
public static void main(String[] args) throws IOException {
WebLogStatictis webLogStatictis=new WebLogStatictis();
StormTopology stormTopology=webLogStatictis.createTopology();
Config config=new Config();
//集群或者本地
//conf.setNumAckers(4);
if(args == null || args.length == 0){
// 本地执行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("webloganalyse2", config , stormTopology);
}else{
// 提交到集群上执行
config.setNumWorkers(4); // 指定使用多少个进程来执行该Topology
try {
StormSubmitter.submitTopology(args[0],config, stormTopology);
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} }
/**
* 构造一个kafkaspout
* @return
*/
private IRichSpout generateSpout(){
BrokerHosts hosts = new ZkHosts("linux-hadoop01.ibeifeng.com:2181");
String topic = "nginxlog";
String zkRoot = "/" + topic;
String id = UUID.randomUUID().toString();
SpoutConfig spoutConf = new SpoutConfig(hosts,topic,zkRoot,id);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme()); // 按字符串解析
spoutConf.forceFromStart = true;
KafkaSpout kafkaSpout = new KafkaSpout(spoutConf);
return kafkaSpout;
} public StormTopology createTopology() {
TopologyBuilder topologyBuilder=new TopologyBuilder();
//指定Spout
topologyBuilder.setSpout(WebLogConstants.KAFKA_SPOUT_ID,generateSpout());
//指定WebLogParserBolt
topologyBuilder.setBolt(WebLogConstants.WEB_LOG_PARSER_BOLT,new WebLogParserBolt()).shuffleGrouping(WebLogConstants.KAFKA_SPOUT_ID);
//指定CountKpiBolt:第一个参数是组件,第二个参数是流ID,第三个参数是分组字段
topologyBuilder.setBolt(WebLogConstants.COUNT_IP_BOLT, new CountKpiBolt(WebLogConstants.IP_KPI))
.fieldsGrouping(WebLogConstants.WEB_LOG_PARSER_BOLT, WebLogConstants.IP_COUNT_STREAM, new Fields(WebLogConstants.IP));
//指定SaveBolt:汇总
topologyBuilder.setBolt(WebLogConstants.SAVE_BOLT ,new SaveBolt(),3)
.shuffleGrouping(WebLogConstants.COUNT_IP_BOLT)
;
return topologyBuilder.createTopology();
} }
2.常量类
package com.jun.it2;
public class WebLogConstants {
//Spout与Bolt的ID
public static String KAFKA_SPOUT_ID="kafkaSpoutId";
public static final String WEB_LOG_PARSER_BOLT = "webLogParserBolt";
public static final String COUNT_IP_BOLT = "countIpBolt";
public static final String COUNT_BROWSER_BOLT = "countBrowserBolt";
public static final String COUNT_OS_BOLT = "countOsBolt";
public static final String USER_AGENT_PARSER_BOLT = "userAgentParserBolt";
public static final String SAVE_BOLT = "saveBolt";
//流ID
public static final String IP_COUNT_STREAM = "ipCountStream";
public static final String URL_PARSER_STREAM = "urlParserStream";
public static final String HTTPREFER_PARSER_STREAM = "httpReferParserStream";
public static final String USERAGENT_PARSER_STREAM = "userAgentParserStream";
public static final String BROWSER_COUNT_STREAM = "browserCountStream";
public static final String OS_COUNT_STREAM = "osCountStream";
//tuple key名称
public static final String DAY = "day";
public static final String HOUR = "hour";
public static final String MINUTE = "minute";
public static final String IP = "ip";
public static final String REQUEST_URL = "requestUrl";
public static final String HTTP_REFER = "httpRefer";
public static final String USERAGENT = "userAgent";
public static final String BROWSER = "browser";
public static final String OS = "os";
public static final String SERVERTIME_KPI = "serverTimeAndKpi";
public static final String KPI_COUNTS = "kpiCounts";
//kpi类型
public static final String IP_KPI = "I";
public static final String URL_KPI = "U";
public static final String BROWSER_KPI = "B";
public static final String OS_KPI = "O";
//Hbase
public static final String HBASE_TABLENAME = "weblogstatictis";
public static final String COLUMN_FAMILY = "info";
}
3.解析类
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import static com.jun.it2.WebLogConstants.*; public class WebLogParserBolt implements IRichBolt {
private Pattern pattern; private OutputCollector outputCollector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
pattern = Pattern.compile("([^ ]*) [^ ]* [^ ]* \\[([\\d+]*)\\] \\\"[^ ]* ([^ ]*) [^ ]*\\\" \\d{3} \\d+ \\\"([^\"]*)\\\" \\\"([^\"]*)\\\" \\\"[^ ]*\\\"");
this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String webLog=tuple.getStringByField("str");
if(webLog!= null || !"".equals(webLog)){ Matcher matcher = pattern.matcher(webLog);
if(matcher.find()){
//
String ip = matcher.group(1);
String serverTimeStr = matcher.group(2); // 处理时间
long timestamp = Long.parseLong(serverTimeStr);
Date date = new Date();
date.setTime(timestamp); DateFormat df = new SimpleDateFormat("yyyyMMddHHmm");
String dateStr = df.format(date);
String day = dateStr.substring(0,8);
String hour = dateStr.substring(0,10);
String minute = dateStr ; String requestUrl = matcher.group(3);
String httpRefer = matcher.group(4);
String userAgent = matcher.group(5); //可以验证是否匹配正确
// System.err.println(webLog);
// System.err.println(
// "ip=" + ip
// + ", serverTimeStr=" + serverTimeStr
// +", requestUrl=" + requestUrl
// +", httpRefer=" + httpRefer
// +", userAgent=" + userAgent
// ); //分流
this.outputCollector.emit(WebLogConstants.IP_COUNT_STREAM, tuple,new Values(day, hour, minute, ip));
this.outputCollector.emit(WebLogConstants.URL_PARSER_STREAM, tuple,new Values(day, hour, minute, requestUrl));
this.outputCollector.emit(WebLogConstants.HTTPREFER_PARSER_STREAM, tuple,new Values(day, hour, minute, httpRefer));
this.outputCollector.emit(WebLogConstants.USERAGENT_PARSER_STREAM, tuple,new Values(day, hour, minute, userAgent));
}
}
this.outputCollector.ack(tuple); } @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declareStream(WebLogConstants.IP_COUNT_STREAM,new Fields(DAY, HOUR, MINUTE, IP));
outputFieldsDeclarer.declareStream(WebLogConstants.URL_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, REQUEST_URL));
outputFieldsDeclarer.declareStream(WebLogConstants.HTTPREFER_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, HTTP_REFER));
outputFieldsDeclarer.declareStream(WebLogConstants.USERAGENT_PARSER_STREAM,new Fields(DAY, HOUR, MINUTE, USERAGENT));
} @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
4.计算类
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; public class CountKpiBolt implements IRichBolt { private String kpiType; private Map<String,Integer> kpiCounts; private String currentDay = ""; private OutputCollector outputCollector; public CountKpiBolt(String kpiType){
this.kpiType = kpiType;
} @Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.kpiCounts = new HashMap<>();
this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String day = tuple.getStringByField("day");
String hour = tuple.getStringByField("hour");
String minute = tuple.getStringByField("minute");
String kpi = tuple.getString(3);
//日期与KPI组合
String kpiByDay = day + "_" + kpi;
String kpiByHour = hour +"_" + kpi;
String kpiByMinute = minute + "_" + kpi;
//将计数信息存放到Map中
int kpiCountByDay = 0;
int kpiCountByHour = 0;
int kpiCountByMinute = 0;
if(kpiCounts.containsKey(kpiByDay)){
kpiCountByDay = kpiCounts.get(kpiByDay);
}
if(kpiCounts.containsKey(kpiByHour)){
kpiCountByHour = kpiCounts.get(kpiByHour);
}
if(kpiCounts.containsKey(kpiByMinute)){
kpiCountByMinute = kpiCounts.get(kpiByMinute);
}
kpiCountByDay ++;
kpiCountByHour ++;
kpiCountByMinute ++;
kpiCounts.put(kpiByDay, kpiCountByDay);
kpiCounts.put(kpiByHour, kpiCountByHour);
kpiCounts.put(kpiByMinute,kpiCountByMinute);
//隔天清空内存
if(!currentDay.equals(day)){
// 说明隔天了
Iterator<Map.Entry<String,Integer>> iter = kpiCounts.entrySet().iterator();
while(iter.hasNext()){
Map.Entry<String,Integer> entry = iter.next();
if(entry.getKey().startsWith(currentDay)){
iter.remove();
}
}
}
currentDay = day;
//发射
//发射两个字段
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByDay, kpiCountByDay));
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByHour, kpiCountByHour));
this.outputCollector.emit(tuple, new Values(kpiType+"_" + kpiByMinute, kpiCountByMinute));
this.outputCollector.ack(tuple); } @Override
public void cleanup() { } @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields(WebLogConstants.SERVERTIME_KPI, WebLogConstants.KPI_COUNTS));
} @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
5.保存类
package com.jun.it2; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException;
import java.util.Map; import static com.jun.it2.WebLogConstants.HBASE_TABLENAME; public class SaveBolt implements IRichBolt {
private HTable table; private OutputCollector outputCollector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
Configuration configuration = HBaseConfiguration.create();
try {
table = new HTable(configuration,HBASE_TABLENAME);
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
} this.outputCollector = outputCollector;
} @Override
public void execute(Tuple tuple) {
String serverTimeAndKpi = tuple.getStringByField(WebLogConstants.SERVERTIME_KPI);
Integer kpiCounts = tuple.getIntegerByField(WebLogConstants.KPI_COUNTS);
System.err.println("serverTimeAndKpi=" + serverTimeAndKpi + ", kpiCounts=" + kpiCounts);
if(serverTimeAndKpi!= null && kpiCounts != null){ Put put = new Put(Bytes.toBytes(serverTimeAndKpi));
String columnQuelifier = serverTimeAndKpi.split("_")[0];
put.add(Bytes.toBytes(WebLogConstants.COLUMN_FAMILY),
Bytes.toBytes(columnQuelifier),Bytes.toBytes(""+kpiCounts)); try {
table.put(put);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
this.outputCollector.ack(tuple);
} @Override
public void cleanup() {
if(table!= null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } @Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
Storm流处理项目案例的更多相关文章
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- Storm自带测试案例的运行
之前Storm安装之后,也知道了Storm的一些相关概念,那么怎么样才可以运行一个例子对Storm流式计算有一个感性的认识呢,那么下面来运行一个Storm安装目录自带的测试案例,我们的Storm安装在 ...
- 常见的七种Hadoop和Spark项目案例
常见的七种Hadoop和Spark项目案例 有一句古老的格言是这样说的,如果你向某人提供你的全部支持和金融支持去做一些不同的和创新的事情,他们最终却会做别人正在做的事情.如比较火爆的Hadoop.Sp ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Storm流计算从入门到精通之技术篇(高并发策略、批处理事务、Trident精解、运维监控、企业场景)
1.Storm全面.系统.深入讲解,采用最新的稳定版本Storm 0.9.0.1 : 2.注重实践,对较抽象难懂的技术点如Grouping策略.并发度及线程安全.批处理事务.DRPC.Storm ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- Selenium自动化测试项目案例实践公开课
Selenium自动化测试项目案例实践公开课: http://gdtesting.cn/news.php?id=55
- Java学生管理系统项目案例
这是一个不错的Java学生管理系统项目案例,希望能够帮到大家的学习吧. 分代码如下 package com.student.util; import java.sql.Connection; impo ...
随机推荐
- pandas 读csv文件 TypeError: Empty 'DataFrame': no numeric data to plot
简单的代码,利用pandas模块读csv数据文件,这里有两种方式,一种是被新版本pandas遗弃的Series.from_csv:另一种就是pandas.read_csv 先说一下问题这个问题就是在读 ...
- luogu P2480 [SDOI2010]古代猪文
M_sea:这道题你分析完后就是一堆板子 废话 理解完题意后,我们要求的东西是\(G^s(s=\sum_{d|n} \binom{n}{d})\) 但是这个指数\(s\)算出来非常大,,, 我们可以利 ...
- Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/l ...
- 【文件】java生成PDF文件
package test; import java.awt.Color; import java.io.FileOutputStream; import org.junit.Test; import ...
- 【BARTS计划】【Share_Week1】社交产品思考
Share:每周分享篇有观点和思考的技术文章 社交梦是每个互联网大厂都在做的,好像大家都默认了一种说法:没有社交功能的产品是不完整的,不做社交产品的公司是缺少战略眼光的.但就目前来看,微信的社交霸 ...
- SpringBoot集成Spring Security(授权与认证)
⒈添加starter依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifact ...
- JavaScript中 this 的指向
很多人都会被JavaScript中this的指向(也就是函数在调用时的调用上下文)弄晕,这里做一下总结: 首先,顶层的this指向全局对象. 函数中的this按照调用方法的不同,其指向也不同: 1.函 ...
- ubuntu16.04+caffe+python接口配置
在Windows上用了一个学期的caffe了.深感各种不便,于是乎这几天在ubuntu上配置了caffe和它的python接口,现在记录配置过程,亲测可用: 环境:ubuntu16.04 , caff ...
- suse系统开启ssh方法
1.防火墙放开ssh服务 打开/etc/sysconfig/SuSEfirewall2 文件,FW_SERVICES_EXT_TCP="ssh"可以定义开放ssh的服务 2.编辑s ...
- oracle数据文件迁移
这篇文章是从网络上获取的,然后根据内容一步步操作, 1.目前的疑问:移动日志文件的时候,为何要先进行切换? 2.move操作后,再进行rename操作的原理 --------------------- ...