hive中关于数据库与表等的基本操作
一:基本用法
1.新建数据库

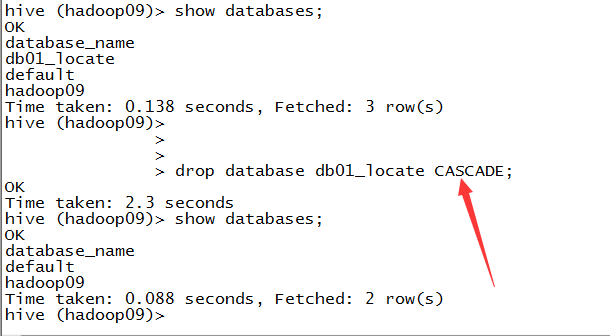
2.删除数据库

3.删除非空的数据库
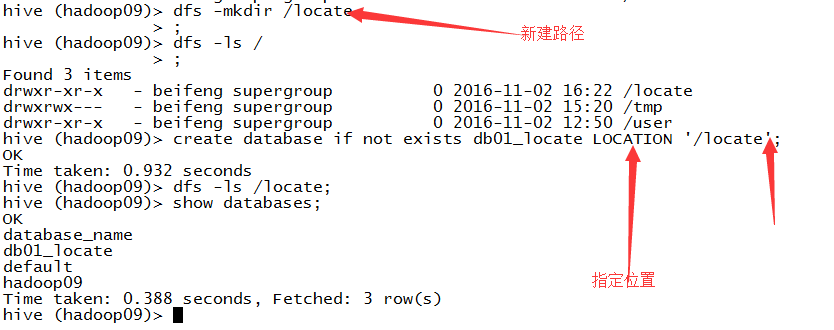
4.指定数据库的位置
LOCATION:指定数据库的位置,不会在系统的默认文件下。
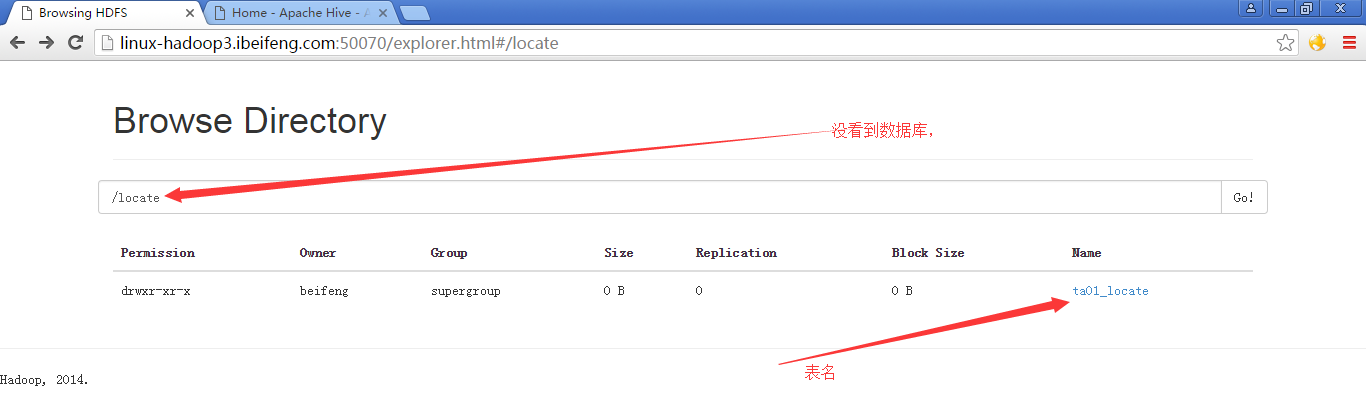
5.在指定数据库中新建表(验证在指定的数据库中可以建表)

6.在页面上观看表
可以看到在指定的目录下有一张新建的表。
但是,没有看到指定的数据库。
7.新建表

8.删除一张表
drop table if exists student;

9.清空一张表

10.加载数据
1)从本地加载

2)从HDFS上加载

3)区别:
移动。

11.查询

12.描述一张表
一张表的一些信息。

13.查看方法

14.描述方法

二:hive的参数的用法
1.到指定的数据库

2.命令行执行SQL

3.执行文件里的sql

4.启动时指定hive的陪置

5.查看当前的配置,更可以更改配置

三.hive shell中常用的操作
1.访问本地文件系统

2.访问hdfs

四.hive中表的使用
1.创建表的三种方式
1)第一种方式:普通方式

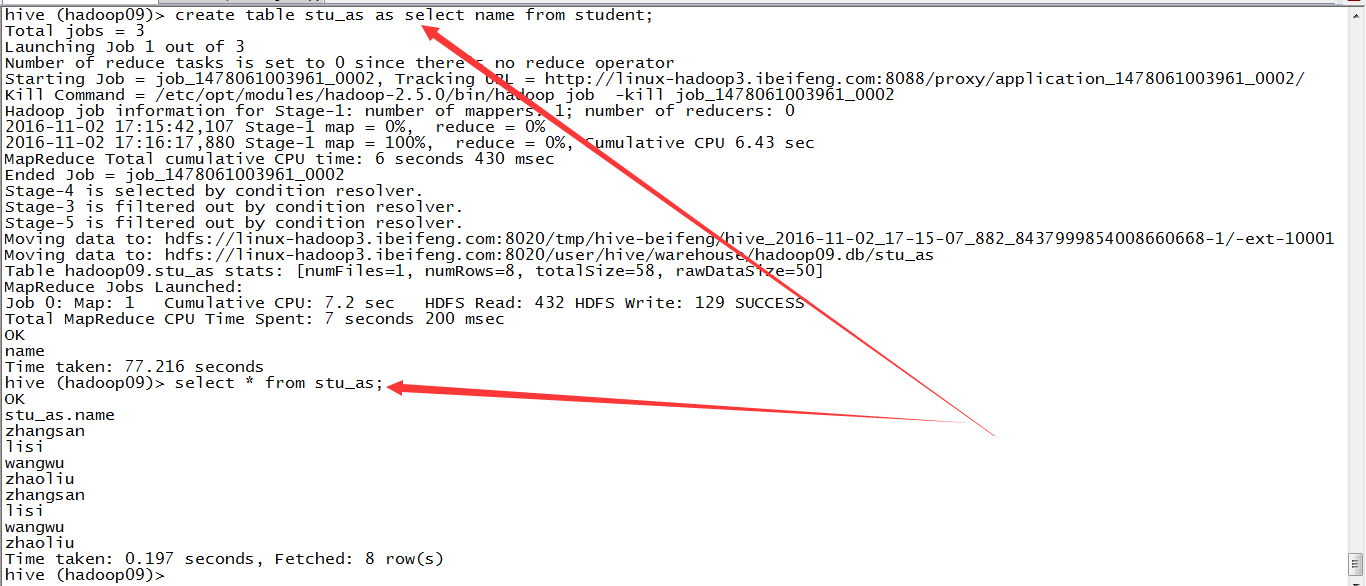
2)第二种方式:as select ,子查询方式
特点:将子查询的数据和结构复制给新的表。
3)第三种方式:like
特点:复制表的结构。

2.表的类型
1)新建员工表

2)新建部门表

3)默认表的类型:管理表
4)问题:文件还有一份,多人使用时,可以通过location指定创建多张表

看在HDFS中的效果

没有加载数据,但是依旧可以使用emp的数据,因为使用的目录。

如果这时候删除掉emp1:
这时,会删除掉元数据的信息,同时删除在HDFS中表的两个文件夹emp与emp1,但是hive中还保留着emp。
5)解决方案
使用外部表。
3.创建外部表
这时,在HDFS上依旧只有一张dept的元数据表。

4.EXCERANL新建的是外部表

5.外部表的好处
这时,删掉dept_ext,dept表的元数据依然还在。
6.分区表
当前的web服务器:
20161019.log
20161020.log
20161021.log
20161022.log
任务:分析前一天的数据
第一种: /logs/20161019.log
20161020.log
20161021.log
20161022.log
select * from logs where date='20161022';
先加载再过滤
第二种: /logs/20161019/20161019.log
/20161020/20161020.log
select * from logs where date='20161022';
直接加载
7.新建分区表
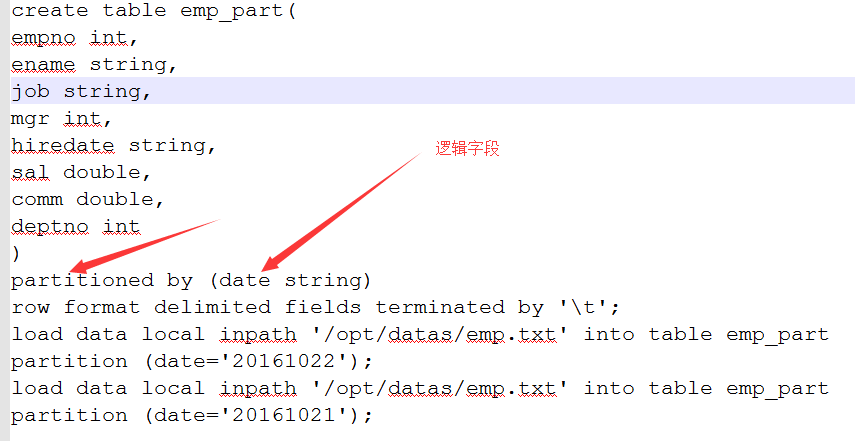
这时,HDFS上出现字段

8.多级分区

9.多级分区的效果

hive中关于数据库与表等的基本操作的更多相关文章
- 039 hive中关于数据库与表等的基本操作
一:基本用法 1.新建数据库 2.删除数据库 3.删除非空的数据库 4.指定数据库的位置 LOCATION:指定数据库的位置,不会在系统的默认文件下. 5.在指定数据库中新建表(验证在指定的数据库中可 ...
- Hive中的数据库、表、数据与HDFS的对应关系
1.hive数据库 我们在hive终端,查看数据库信息,可以看出hive有一个默认的数据库default,而且我们还知道hive数据库对应的是hdfs上面的一个目录,那么默认的数据库default到底 ...
- Hive中的数据库(Database)和表(Table)
在前面的文章中,介绍了可以把Hive当成一个"数据库",它也具备传统数据库的数据单元,数据库(Database/Schema)和表(Table). 本文介绍一下Hive中的数据库( ...
- SQL Server中查询数据库及表的信息语句
/* -- 本文件主要是汇总了 Microsoft SQL Server 中有关数据库与表的相关信息查询语句. -- 下面的查询语句中一般给出两种查询方法, -- A方法访问系统表,适应于SQL 20 ...
- SQL中查看数据库各表的大小
SQL中查看数据库各表的大小 编写人:CC阿爸 2014-6-17 在日常SQL数据库的操作中,如何快速的查询数据库中各表中数据的大小. 以下有两种方法供参考: 第一种: create table # ...
- impala不能查询hive中新增加的表问题
使用Cloudera Manager部署安装的CDH和Impala,Hive中新增加的表,impala中查询不到,其原因是/etc/impala/conf下面没有hadoop和hive相关的 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hive中使用正則表達式不当导致执行奇慢无比
业务保障部有一个需求,须要用hive实时计算上一小时的数据.比方如今是12点,我须要计算11点的数据,并且必须在1小时之后执行出来.可是他们用hive实现的时候发现就单个map任务执行都超过了1小时, ...
- 在hive中查询导入数据表时FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
当我们出现这种情况时 FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least ...
随机推荐
- POJ1679 The Unique MST(次小生成树)
可以依次枚举MST上的各条边并删去再求最小生成树,如果结果和第一次求的一样,那就是最小生成树不唯一. 用prim算法,时间复杂度O(n^3). #include<cstdio> #incl ...
- python IDLE 改变窗口背景颜色
初学Python,想必大家拿来练习最多的IDE就是Python自带的IDLE了,但是默认的代码配色及语法高亮主题确实很不适应. 能不能把IDLE配置成像sublime_text那样的主题呢? 答案是当 ...
- BZOJ3448 : [Usaco2014 Feb]Auto-complete
RE了几十发,实在没办法了…只好向管理员要数据,然后发现数据规模与题目描述不符… 建立Trie并求出DFS序,同时根据DFS序确定字典序 然后每次询问相当于询问子树第k小,用主席树维护,注意压缩内存 ...
- POJ 3352 (边双连通分量)
题目链接: http://poj.org/problem?id=3352 题目大意:一个连通图中,至少添加多少条边,使得删除任意一条边之后,图还是连通的. 解题思路: 首先来看下边双连通分量的定义: ...
- ios CGImageRelease 出现 EXC_BAD_ACCESS的错误 ios特定形状剪裁图片 内存泄露
CGImageRef imgRef = [image CGImage]; 通过此种方式的得到的CGImageRef不能利用CGImageRelease释放,因为你不拥有它所以不用释放 在ios中特定形 ...
- 参考XML操作类
转载参考地址: http://blog.csdn.net/happy09li/article/details/7460521
- 用MyEclipse搭建SSH框架(Struts2 Spring Hibernate)
1.new一个web project. 2.右键项目,为项目添加Struts支持. 点击Finish.src目录下多了struts.xml配置文件. 3.使用MyEclipse DataBase Ex ...
- PHPUnit在Windows下的配置及使用
由于我们项目涉及到php,因此需要对php代码进行单元测试.经过一番了解,决定用PHPUnit来测试php.PHPUnit花了不少时间摸索如何配置PHPUnit,看官网的文档也是一把泪.但知道怎么配置 ...
- QCheckBox 的按钮响应
Qt中QCheckBox的按键响应如下,其中checkbox为对象名: void YourClass::on_checkbox_toggled(bool state) { // Do somethin ...
- JS - 超强大文本动画插件Textillate.js
http://www.yyyweb.com/demo/textillate/ Textillate.js AsimplepluginforCSS3textanimations.