Hadoop_FileInputFormat分片
Hadoop学习笔记总结
01. InputFormat和OutFormat
1. 整个MapReduce组件

InputFormat类和OutFormat类都是抽象类。
可以实现文件系统的读写,数据库的读写,服务器端的读写。
这样的设计,具有高内聚、低耦合的特点。
2. 提交任务时,获取split切片信息的流程
JobSubmitter初始化submitterJobDir资源提交路径,是提交到HDFS保存文件路径,一些Jar包和配置文件:

接下来,是JobSubmitter中将切片信息写入submitJobDir目录。
int maps = writeSplits(job, submitJobDir);writeSplits方法中,首先会通过反射拿到用户设置的InputFormat子类的实例(默认为TextInputFormat类),然后调用FileInputFormat的getSplit方法(父类公共方法)再获得切片的信息,封装到InputSplit中,返回List。
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
最后将切片描述信息写到submitterJobDir资源提交路径中。
JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array);
InputSplit包含block块所在位置主机,路径,偏移量等信息。分片数据不包含数据本身,而是指向数据的引用。
input.getSplits()方法解析

由FileInputFormat类中getSplits方法决定。
计算公式://computeSplitSize中
minSize=max{getFormatMinSplitSize(),mapred.min.split.size} (getFormatMinSplitSize()大小默认为1B)
maxSize=mapred.max.split.size(不在配置文件中指定时大小为Long.MAX_VALUE)
//blockSize是默认的配置大小:128MB //分片大小的计算公式
splitSize=max{minSize,min{maxSize,blockSize}}
默认情况下,minSize < blockSize < maxSize
所以,默认不在配置文件配置split最大值和最小值,分片大小就是blockSize,128MB。
公式的含义:取分片大小不大于block,并且不小于在mapred.min.split.size配置中定义的最小Size。
举例说明如何控制分片大小:
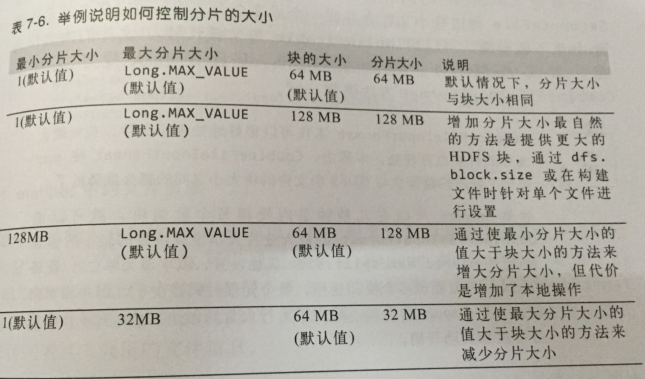
3. 为什么Hadoop不擅长小文件
逻辑上,FileInputFormat生成的分块是一个文件或者该文件的一部分,如果是很多小文件,就生成了很多的逻辑block。默认情况下,一个分片就是一个block,因而,会有很多个map任务,每次map操作都有很多额外的开销。
因此,运行大量小文件的任务,会增加运行作业的额外开销;浪费NameNode内存。
解决:CombineFileInputFormat
参考《Hadoop权威指南》
初接触,记下学习笔记,还有很多问题,望指导,谢谢。
Hadoop_FileInputFormat分片的更多相关文章
- elasticsearch高级配置一 ---- 分片分布规则设置
cluster.routing.allocation.allow_rebalance 设置根据集群中机器的状态来重新分配分片,可以设置为always, indices_primaries_active ...
- redis分片
本文是在window环境下测试 什么是分片 当数据量大的时候,把数据分散存入多个数据库中,减少单节点的连接压力,实现海量数据存储 那么当多个请求来取数据时,如何知道数据在哪个redis呢,redis有 ...
- CephRGW 在多个RGW负载均衡场景下,RGW 大文件并发分片上传功能验证
http://docs.ceph.com/docs/master/radosgw/s3/objectops/#initiate-multi-part-upload 根据分片上传的API描述,因为对同一 ...
- Ceph RGW服务 使用s3 java sdk 分片文件上传API 报‘SignatureDoesNotMatch’ 异常的定位及规避方案
import java.io.File; import com.amazonaws.AmazonClientException; import com.amazonaws.auth.profile ...
- IP分片详解
IP分片是网络上传输IP报文的一种技术手段.IP协议在传输数据包时,将数据报文分为若干分片进行传输,并在目标系统中进行重组.不同的链路类型规定有不同最大长度的链路层数据帧,称为链路层MTU(最大传输单 ...
- MongoDB的分片(9)
什么是分片 分片是指将数据库拆分,将其分散在不同的机器上的过程.将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载.基本思想就是将集合切成小块,这些块分散到若干片里, ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- 用百度webuploader分片上传大文件
一般在做文件上传的时候,都是通过客户端把要上传的文件上传到服务器,此时上传的文件都在服务器内存,如果上传的是视频等大文件,那么服务器内存就很紧张,而且一般我们都是用flash或者html5做异步上传, ...
- mongodb分片配置
通过YUM库自动安装Mongodb 手动安装配置mongodb 验证mongodb主从复制过程 验证mongodb副本集并实现自动切换 实验mongodb使用gridfs存放一个大文件 1.创建数据目 ...
随机推荐
- ASP.NET中Session简单原理图
刚学习Session,对session的理解相当肤浅,按照我的想法画了原理图,麻烦各位大神指正,谢了!
- POJ 3761 Bubble Sort 快速幂取模+组合数学
转载于:http://www.cnblogs.com/767355675hutaishi/p/3873770.html 题目大意:众所周知冒泡排序算法多数情况下不能只扫描一遍就结束排序,而是要扫描好几 ...
- php中的字符串常用函数(四) ord() 获得字符的ascii码 chr()获取ascii码对应的字符
ord('a');//=>97 返回小写a 的ascii码值97 chr(97);//=>a 返回ascii码表上的97对应的 小写a
- java线程控制、状态同步、volatile、Thread.interupt以及ConcurrentLinkedQueue
在有些严格的系统中,我们需要做到干净的停止线程并清理相关状态.涉及到这个主题会带出很多的相关点,简单的总结如下: 我们知道,在java中,有一个volatile关键字,其官方说明(https://do ...
- 操作iframe
iframe是在页面中嵌套的子页,当前页面(这里称为父页)和嵌套页面(这里称为子页)可以相互控制: 当父页控制子页用contentWindow,用法为 对象.contentWindow.documen ...
- Bootstrap 我的学习记录4 轮播图的使用和理解
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="utf-8& ...
- andriod 用户名和密码
<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android=&quo ...
- 关于const和define的内存分配问题的总结
关于const和define的内存分配问题 const与#define宏定义的区别----C语言深度剖析 1, const定义的只读变量在程序运行过程中只有一份拷贝(因为它是全局的只读变量,存放在静 ...
- OC-分类
1.不能再分类里面添加属性, 只能添加方法. 2.如果在分类里面使用@property,那么他只生成sette,getter的声明而没有实现. 3.如在在分类中写了与本类同名的方法,优先调用分类里面的 ...
- iOS 7中实现模糊效果
本文译自iOS 7 Blur Effects with GPUImage. iOS 7在视觉方面有许多改变,其中非常吸引人的功能之一就是在整个系统中巧妙的使用了模糊效果.许多第三方应用程序已经采用了这 ...