海量数据处理-BitMap算法
一、概述
本文将讲述Bit-Map算法的相关原理,Bit-Map算法的一些利用场景,例如BitMap解决海量数据寻找重复、判断个别元素是否在海量数据当中等问题.最后说说BitMap的特点已经在各个场景的使用性。
二、Bit-Map算法
先看看这样的一个场景:给一台普通PC,2G内存,要求处理一个包含40亿个不重复并且没有排过序的无符号的int整数,给出一个整数,问如果快速地判断这个整数是否在文件40亿个数据当中?
问题思考:
40亿个int占(40亿*4)/1024/1024/1024 大概为14.9G左右,很明显内存只有2G,放不下,因此不可能将这40亿数据放到内存中计算。要快速的解决这个问题最好的方案就是将数据搁内存了,所以现在的问题就在如何在2G内存空间以内存储着40亿整数。一个int整数在java中是占4个字节的即要32bit位,如果能够用一个bit位来标识一个int整数那么存储空间将大大减少,算一下40亿个int需要的内存空间为40亿/8/1024/1024大概为476.83 mb,这样的话我们完全可以将这40亿个int数放到内存中进行处理。
具体思路:
1个int占4字节即4*8=32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32]即可存储完这些数据,其中N代表要进行查找的总数,tmp中的每个元素在内存在占32位可以对应表示十进制数0~31,所以可得到BitMap表:
tmp[0]:可表示0~31
tmp[1]:可表示32~63
tmp[2]可表示64~95
.......
那么接下来就看看十进制数如何转换为对应的bit位:
假设这40亿int数据为:6,3,8,32,36,......,那么具体的BitMap表示为:
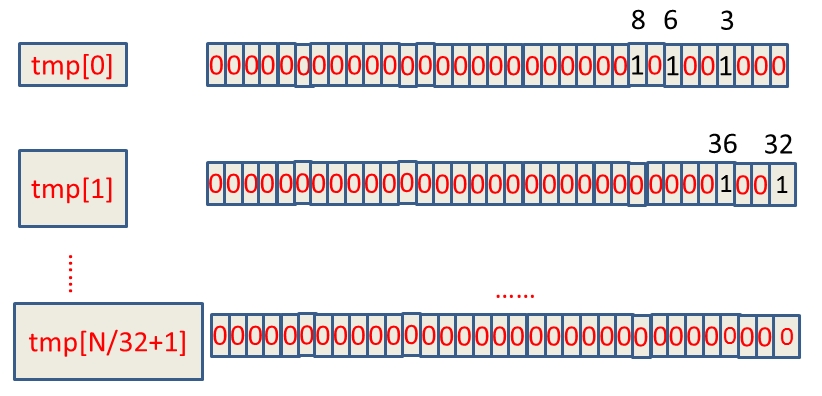
那么怎么快速定位它的索引呢。如果找到它的索引号,又怎么定位它的位置呢。Index(N)代表N的索引号,Position(N)代表N的所在的位置号。
Index(N) = N/8 = N >> 3; Position(N) = N%8 = N & 0x07;
add方法:
public void add(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。
bits[arrayIndex] |= 1 << position;
}
code:
public class BitMap {
//保存数据的
private byte[] bits;
//能够存储多少数据
private int capacity;
public BitMap(int capacity){
this.capacity = capacity;
//1bit能存储8个数据,那么capacity数据需要多少个bit呢,capacity/8+1,右移3位相当于除以8
bits = new byte[(capacity >>3 )+1];
}
public void add(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。
bits[arrayIndex] |= 1 << position;
}
public boolean contain(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做&,判断是否为0即可
return (bits[arrayIndex] & (1 << position)) !=0;
}
public void clear(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后对取反,再与当前值做&,即可清除当前的位置了.
bits[arrayIndex] &= ~(1 << position);
}
public static void main(String[] args) {
BitMap bitmap = new BitMap(100);
bitmap.add(7);
System.out.println("插入7成功");
boolean isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
bitmap.clear(7);
isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
}
}
每个byte存8个数字,相对于int类型来说,节省了32倍的存储空间
存储数据范围,就上面的例子来说,上面bits数组的长度为13,那么总共可以存储(13*8)104个数字,分别是(0~103)
上面的代码并没有扩容方法,超出范围会报错,
使用bit数组来表示某些元素是否存在,比如8位电话号码.
缺点:
如果是比较特殊的数字,比如[1,100000000],那么就会浪费存储空间,比如这个就必须要(100000000>>3)个字节
针对上面的缺点,谷歌所实现的EWAHCompressedBitmap对bitmap存储空间做了一定的优化
相信的讲解:http://www.sohu.com/a/166661005_479559
问题实例
1、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
解法一:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
解法二:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。”
2、给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
解法一:可以用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
https://www.jianshu.com/p/6082a2f7df8e
https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/06.07.html
http://blog.51cto.com/zengzhaozheng/1404108
http://blog.csdn.net/h348592532/article/details/45362661
https://www.cnblogs.com/protected/p/6626447.html
海量数据处理-BitMap算法的更多相关文章
- (面试)Hash表算法十道海量数据处理面试题
Hash表算法处理海量数据处理面试题 主要针对遇到的海量数据处理问题进行分析,参考互联网上的面试题及相关处理方法,归纳为三种问题 (1)数据量大,内存小情况处理方式(分而治之+Hash映射) (2)判 ...
- 海量数据处理算法—Bloom Filter
海量数据处理算法—Bloom Filter 1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bl ...
- 从hadoop框架与MapReduce模式中谈海量数据处理
http://blog.csdn.net/wind19/article/details/7716326 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显 ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- july教你如何迅速秒杀掉:99%的海量数据处理面试题
作者:July出处:结构之法算法之道blog 以下是原博客链接网址 http://blog.csdn.net/v_july_v/article/details/7382693 微软面试100题系列 h ...
- 海量数据处理面试题学习zz
来吧骚年,看看海量数据处理方面的面试题吧. 原文:(Link, 其实引自这里 Link, 而这个又是 Link 的总结) 另外还有一个系列,挺好的:http://blog.csdn.net/v_jul ...
- 海量数据处理的 Top K 相关问题
Top-k的最小堆解决方法 问题描述:有N(N>>10000)个整数,求出其中的前K个最大的数.(称作Top k或者Top 10) 问题分析:由于(1)输入的大量数据:(2)只要前K个,对 ...
- DBA_Oracle海量数据处理分析(方法论)
2014-12-18 Created By BaoXinjian
随机推荐
- ubuntu16.4中安装samba服务
一.下载samba软件包,不用安装其他的了,因为它会自动帮我们下载所需要的其他依赖包 sudo apt-get install samba 二.修改/etc/samba目录下的配置文件,smb.con ...
- SQL SERVER 聚集索引 非聚集索引 区别
转自http://blog.csdn.net/single_wolf_wolf/article/details/52915862 一.理解索引的结构 索引在数据库中的作用类似于目录在书籍中的作用,用来 ...
- iOS入门怎样选择Swift和objective-c
版权声明:本文为博主原创文章,未经博主同意不得转载.博主微信:lofocus https://blog.csdn.net/cuibo1123/article/details/28261795 学oc吧 ...
- [py]编码-强力理解版
py编码骨灰级总结 思路: python执行py文件步骤--py2/3定义变量时unicode差异 1,py2 py3执行py文件的步骤 2,py2 定义变量x='mao' 1.x='mao', # ...
- [wx]自然数学规律
有趣的数学规律 椭圆 双曲线 抛物线都叫圆锥曲线 它们跟圆锥有着怎样的关系? 他们都是圆锥与平面在不同姿势下交配的产物. 参考 椭圆 抛物线 小结 e: 离线率 P: 任意一点 F: 焦点 准线: 一 ...
- PHP开启CORS
CORS 定义 Cross-Origin Resource Sharing(CORS)跨来源资源共享是一份浏览器技术的规范,提供了 Web 服务从不同域传来沙盒脚本的方法,以避开浏览器的同源策略,是 ...
- 包管理 ----- Linux操作系统rpm包安装方式步骤
Linux操作系统rpm包安装方式步骤 2016年08月04日 07:00:26 阅读数:17140 转自 : http://os.51cto.com/art/201003/186467.htm 特别 ...
- jmeter Bean Shell的使用(一)
未经作者允许,禁止转载!!! Jmeter有哪些Bean Shell 定时器: BeanShell Timer 前置处理器:BeanShell PreProcessor 采样器: BeanShell ...
- 禁止F12与右键
实践项目的代码哦,给大家分享下,如何屏蔽右键与F12. 应用网站 www.empiretreasure.vip 与 www.MineBook.vip.可以去逛逛哦. 不多说了,上代码 ...
- Trove系列(五)—Trove的数据存储管理程序类型和版本管理功能介绍
功能描述数据存储管理程序(Datastore)类型管理允许Trove的用户从操作者列出的名单中选择数据库存储管理程序和版本.操作者将可以控制数据库存储管理程序的类型,添加一个新的版本并去活一个老版本. ...