NLP 中的embedding layer
https://blog.csdn.net/chuchus/article/details/78386059
词汇是语料库的基本元素, 所以, 使用embedding layer来学习词嵌入, 将一个词映射成为固定维度的稠密向量. 有了这一步, 才能构造矩阵, 实现神经网络的前向传播.
如何使用?
- 从头训练
就像word2vec一样, 这一层是可学习的, 用随机数initialize , 通过BP去调整. - pre-trained + fine tuning
用其他网络(如 word2vec) 训练好的现成的词向量, 作为初始化参数, 然后继续学习. - pre-trained + static
用其他网络(如 word2vec) 训练好的现成的词向量, 作为初始化参数, 并且这些参数保持固定, 不参与网络的学习.
keras 的 Embedding
Embedding(Layer)
类. 将索引映射为固定维度的稠密的向量.
eg. [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
This layer can only be used as the first layer in a model.
__init__(self, input_dim, output_dim,input_length,...)
构造函数, 分别为三个参数分别代表vocab_size,vector_dimension,fixed_word_number.
还有继承自父类的weights,trainable参数.
如一个语料库, 词汇量为20万, word representation vector is 200d, 文章的截断长度为250个单词, 那么
embedding_layer=Embedding(input_dim=20E4,output_dim=200,input_length=250,weights=embedding_matrix,trainable=is_trainable)
keras:3)Embedding层详解
https://blog.csdn.net/jiangpeng59/article/details/77533309
Embedding层
keras.layers.embeddings.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)- 1
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
Embedding层只能作为模型的第一层
参数
input_dim:大或等于0的整数,字典长度,即输入数据最大下标+1
output_dim:大于0的整数,代表全连接嵌入的维度
embeddings_initializer: 嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
embeddings_regularizer: 嵌入矩阵的正则项,为Regularizer对象
embeddings_constraint: 嵌入矩阵的约束项,为Constraints对象
mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为|vocabulary| + 2。
input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
输入shape
形如(samples,sequence_length)的2D张量
输出shape
形如(samples, sequence_length, output_dim)的3D张量
较为费劲的就是第一句话:
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
哪到底咋转啊,亲?
这涉及到词向量,具体看可以参考这篇文章:Word2vec 之 Skip-Gram 模型,下面只进行简单的描述,
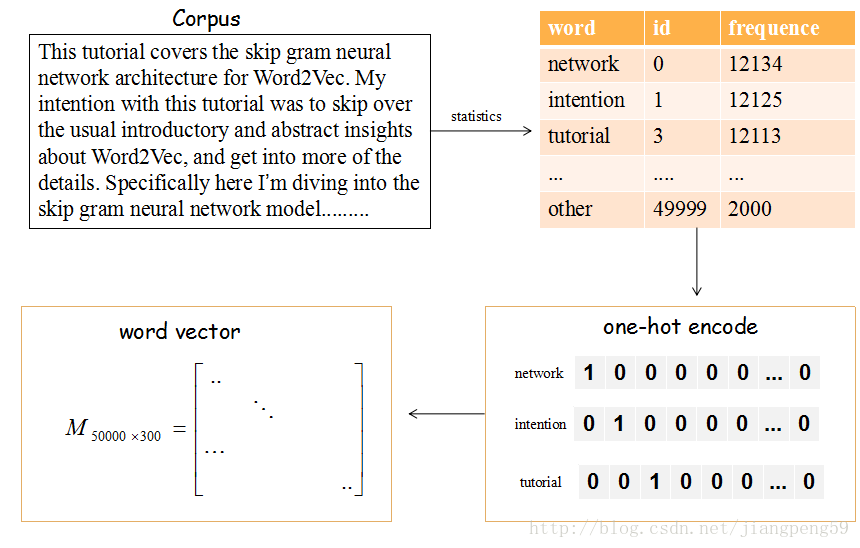
上图的流程是把文章的单词使用词向量来表示。
(1)提取文章所有的单词,把其按其出现的次数降许(这里只取前50000个),比如单词‘network’出现的次数最多,编号ID为0,依次类推…
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)最后,我们会生产一个矩阵M,行大小为词的个数50000,列大小为词向量的维度(通常取128或300),比如矩阵的第一行就是编号ID=0,即network对应的词向量。
那这个矩阵M怎么获得呢?在Skip-Gram 模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵
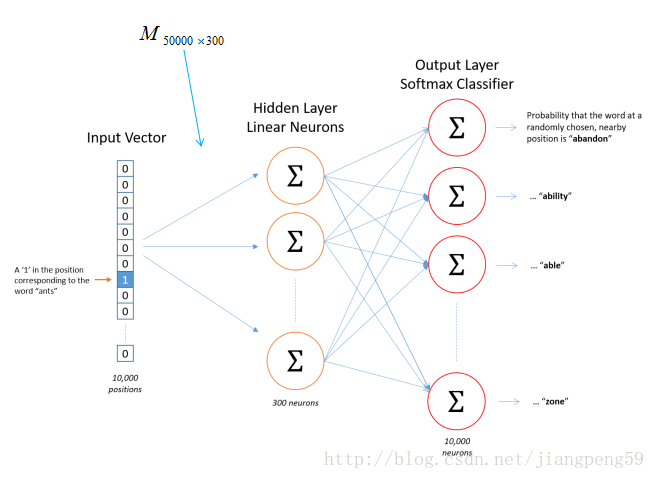
那我们的输入数据和标签是什么?如下图,输入数据就是中间的哪个蓝色的词对应的one-hot编码,标签就是它附近词的one-hot编码(这里windown_size=2,左右各取2个)
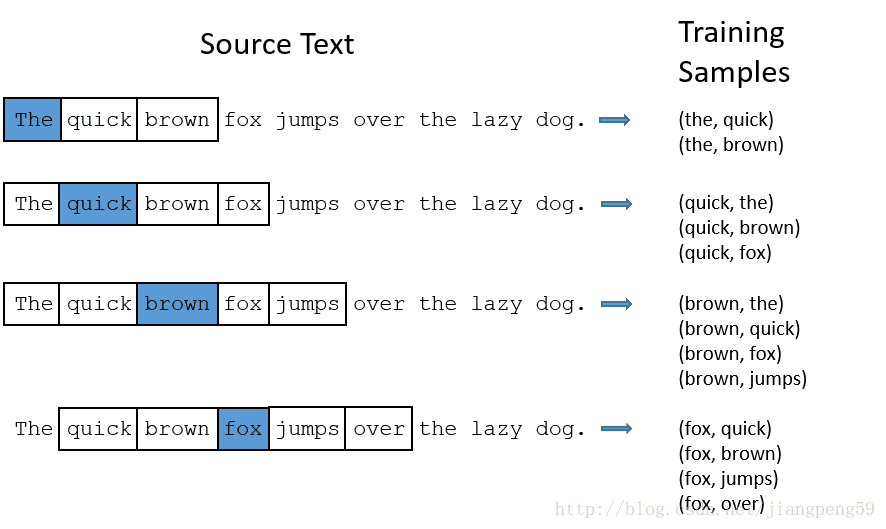
就上述的Word2Vec中的demo而言,它的单词表大小为1000,词向量的维度为300,所以Embedding的参数 input_dim=10000,output_dim=300
回到最初的问题:嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
举个栗子:假如单词表的大小为1000,词向量维度为2,经单词频数统计后,tom对应的id=4,而jerry对应的id=20,经上述的转换后,我们会得到一个M1000×2M1000×2的矩阵,而tom对应的是该矩阵的第4行,取出该行的数据就是[0.25,0.1]
如果输入数据不需要词的语义特征语义,简单使用Embedding层就可以得到一个对应的词向量矩阵,但如果需要语义特征,我们大可把以及训练好的词向量权重直接扔到Embedding层中即可,具体看参考keras提供的栗子:在Keras模型中使用预训练的词向量
NLP 中的embedding layer的更多相关文章
- NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键, ...
- 机器学习-NLP之Word embedding 原理及应用
概述 自然语言是非常复杂多变的,计算机也不认识咱们的语言,那么咱们如何让咱们的计算机学习咱们的语言呢?首先肯定得对咱们的所有文字进行编码吧,那咱们很多小伙伴肯定立马就想出了这还不简单嘛,咱们的计算机不 ...
- GAN︱GAN 在 NLP 中的尝试、困境、经验
GAN 自从被提出以来,就广受大家的关注,尤其是在计算机视觉领域引起了很大的反响,但是这么好的理论是否可以成功地被应用到自然语言处理(NLP)任务呢? Ian Goodfellow 博士 一年前,网友 ...
- [转] 理解NLP中的卷积&&Pooling
转自:http://blog.csdn.net/malefactor/article/details/51078135 CNN是目前自然语言处理中和RNN并驾齐驱的两种最常见的深度学习模型.图1展示了 ...
- 理解NLP中的卷积神经网络(CNN)
此篇文章是Denny Britz关于CNN在NLP中应用的理解,他本人也曾在Google Brain项目中参与多项关于NLP的项目. · 翻译不周到的地方请大家见谅. 阅读完本文大概需要7分钟左右的时 ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- 图解BERT(NLP中的迁移学习)
目录 一.例子:句子分类 二.模型架构 模型的输入 模型的输出 三.与卷积网络并行 四.嵌入表示的新时代 回顾一下词嵌入 ELMo: 语境的重要性 五.ULM-FiT:搞懂NLP中的迁移学习 六.Tr ...
随机推荐
- Codeforces Round #375 (Div. 2) A. The New Year: Meeting Friends 水题
A. The New Year: Meeting Friends 题目连接: http://codeforces.com/contest/723/problem/A Description There ...
- LayoutInflater作用及使用(转)
作用: 1.对于一个没有被载入或者想要动态载入的界面, 都需要使用inflate来载入. 2.对于一个已经载入的Activity, 就可以使用实现了这个Activiyt的的findViewById方法 ...
- python实例[判断操作系统类型]
参考文献:http://bbs.chinaunix.net/thread-1848086-1-1.html 经常地我们需要编写跨平台的脚本,但是由于不同的平台的差异性,我们不得不获得当前所工作的平台( ...
- 内核调试神器SystemTap 转摘
http://blog.csdn.net/zhangskd/article/details/25708441 https://sourceware.org/systemtap/wiki/WarStor ...
- HDU 4081 Qin Shi Huang's National Road System(最小生成树/次小生成树)
题目链接:传送门 题意: 有n坐城市,知道每坐城市的坐标和人口.如今要在全部城市之间修路,保证每一个城市都能相连,而且保证A/B 最大.全部路径的花费和最小,A是某条路i两端城市人口的和,B表示除路i ...
- AutoMapper在MVC中的运用06-一次性定义映射、复杂类型属性映射
本篇AutoMapper使用场景: ※ 当源和目标具有同名的复杂类型属性.集合类型属性,这2种属性对应的类间也需建立映射 ※ 一次性定义好源和目标的所有映射 ※ 一次性定义好源和目标的所有映射,目标中 ...
- C#高级编程小结
小结 这几章主要介绍了如何使用新的dynamic类型,还讨论了编译器在遇到dynamic类型时会做什么.还讨论了DLP,可以把它包含在简单的应用程序中.并通过Pythin使用DLR,执行Python脚 ...
- 漏洞风险评估:CVSS介绍及计算
CVSS 通用弱点评价体系(CVSS)是由NIAC开发.FIRST维护的一个开放并且能够被产品厂商免费采用的标准.利用该标准,可以对弱点进行评分,进而帮助我们判断修复不同弱点的优先等级. CVSS : ...
- Linux学习19-gitlab配置邮箱postfix(新用户激活邮件)
前言 gitlab新增新用户有两种方式,第一种可以用户主动注册(自己设置密码):第二种也可以通过root管理员用户直接添加用户,发个邮件到用户的邮箱里,收到邮件后激活. 如果是第二种方式添加新用户的话 ...
- 一篇linux的通讯文章
今年的linux内核开发大会上,google的开发人员也上台做了名为“how google use linux”的演讲.我斗胆翻译注解一番――括号内为注解,欢迎读者斧正. 原文链接参见:http:// ...