laravel 懒加载
故事背景是什么呢?
目录大家都知道吧,一般有几个层级,根据公司需求,要将目录以树的形式展示出来,为了提高访问速度,这些目录数据要一次性读取出来的。这样的话就涉及到了查询,优化查询次数是一个很关键的事情。否则的话,一个目录查询好几百次,那这个项目就不能用了。

然后数据库中各个目录之间的关联是通过father_id来做的,具体的数据库表设计如下:
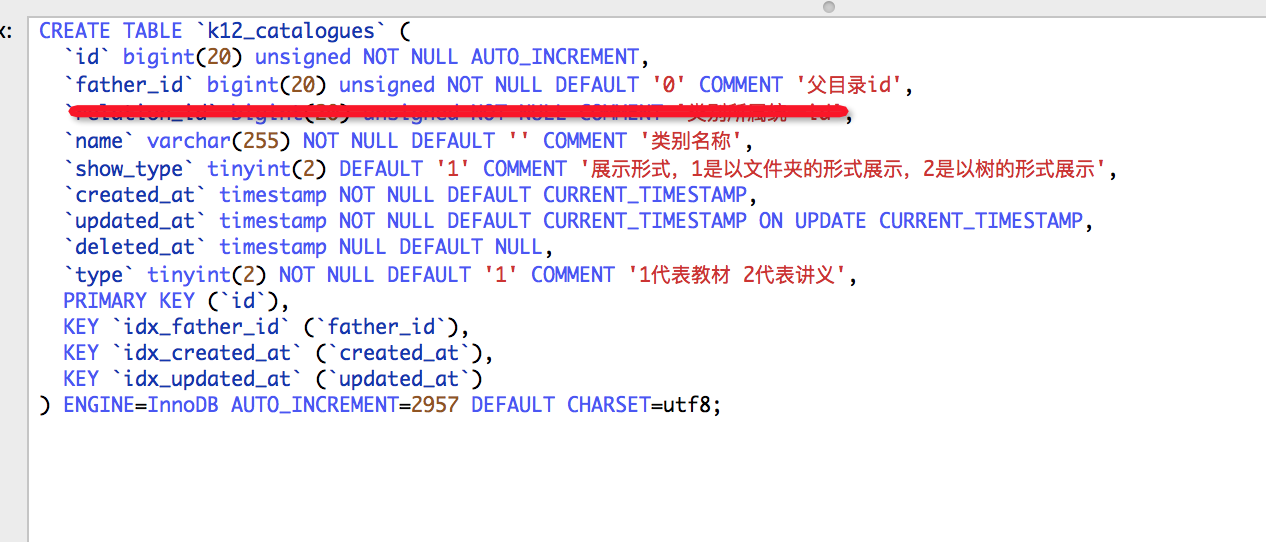
这也就意味着,你需要根据father_id从某个目录开始一次性的把数据全部读出来。目录的层级不确定。这样的话,如果不好好思考查询的话,将会导致查询次数过多,给数据库增加不必要的负担。
能想到的最简单的方法就是用for循环来查询。但for循环查询明显的效率比较低。这个时候就需要用懒加载了。
懒加载是什么意思呢?
两张表,目录表和教材表。多个教材属于一个目录,那么利用懒加载,你就可以通过先把目录读出来,然后把这些与目录有关的教材一下子读出来完。这样进行数据库读取的次数就少了。
所以我从国外的一个网站上搬来了with和load的用法,大家自行领悟吧。
Both accomplish the same end results—eager loading a related model onto the first. In fact, they both run exactly the same two queries. The key difference is that with() eager loads the related model up front, immediately after the initial query (all(), first(), or find(x), for example); when using load(), you run the initial query first, and then eager load the relation at some later point.
“Eager” here means that we’re associating all the related models for a particular result set using just one query, as opposed to having to run n queries, where n is the number of items in the initial set.
Eager loading using with()
If we eager load using with(), for example:
$users = User::with('comments')->get();
if we have 5 users, the following two queries get run immediately:
select * from `users`
select * from `comments` where `comments`.`user_id` in (1, 2, 3, 4, 5)
…and we end up with a collection of models that have the comments attached to the user model, so we can do something like $users->comments->first()->body.
“Lazy” eager loading using load()
In this approach, we can separate the two queries, first by getting the initial result:
$users = User::all();
which runs:
select * from `users`
And later, if we decide(based on some condition) that we need the related comments for all these users, we can eager load them after the fact:
if($someCondition){
$users = $users->load('comments');
}
which runs the 2nd query:
select * from `comments` where `comments`.`user_id` in (1, 2, 3, 4, 5)
And we end up with the same result, just split into two steps. Again, we can call $users->comments->first()->body to get to the related model for any item.
Conclusion
When to use load() or with()?
load() gives you the option of deciding later, based on some dynamic condition, whether or not you need to run the 2nd query.
If, however, there’s no question that you’ll need to access all the related items, use with().
接下来我就要尝试着去使用with和load:不得不说芳哥写的代码还是叼叼叼啊。
// 查询出节点下的所有目录,经典。
while (true) {
$nextLevelNodes = new Collection();
foreach ($directories as $directory) {
if ($directory->catalogue_empty) {
continue;
}
$nextLevelNodes = $nextLevelNodes->merge($directory->childCatalogues);
}
if (count($nextLevelNodes) === 0) {
break;
}
$allCatalogues = $allCatalogues->merge($nextLevelNodes);
$directories = $nextLevelNodes;
} // 加载文件夹下的文件,还可以。
$allCatalogues->load('childFiles.file'); // 根据父ID来索引,经典
$catalogueMaps = [];
foreach ($allCatalogues as $catalogue) {
$catalogueMaps[$catalogue->father_id][] = $catalogue;
}
public function getCataloguesData($catalogueMaps, $parentId)
{
if (!isset($catalogueMaps[$parentId])) {
return [];
} $result = [];
$directories = $catalogueMaps[$parentId]; foreach ($directories as $directory) {
$treeNode = [
'name' => $directory->name,
'type' => 'tree',
'id' => $directory->id,
'data' => [],
];
if (!$directory->catalogue_empty) {
$treeNode['data'] = $this->getCataloguesData($catalogueMaps, $directory->id);
} elseif (!$directory->is_empty) {
$treeNode['data'] = $this->getLectureNoteData($directory->childFiles);
}
$result[] = $treeNode;
} return $result;
}
后面读取代码,load和with完之后,主要是通过下面的代码获取数据
public function inode()
{
return $this->belongsTo(MaterialFileInodeModel::class, 'inode_id');
}
// 可以使用
public function childFiles()
{
return $this->hasMany(MaterialFileModel::class, 'parent_id');
}
// 可以使用readable_size
public function getReadableSizeAttribute()
{
if ($this->is_dir == self::IS_DIR_YES) {
return '--';
} return StringUtil::formatFileSize($this->file_size);
}
//last_modified
public function getLastModifiedAttribute()
{
$time = strtotime($this->updated_at);
return date('Y-m-d H:i', $time);
}
laravel 懒加载的更多相关文章
- 懒加载session 无法打开 no session or session was closed 解决办法(完美解决)
首先说明一下,hibernate的延迟加载特性(lazy).所谓的延迟加载就是当真正需要查询数据时才执行数据加载操作.因为hibernate当中支持实体对象,外键会与实体对象关联起来.如 ...
- 学习EF之贪懒加载和延迟加载(2)
通过昨天对EF贪婪加载和延迟加载的学习,不难发现,延迟加载还是很好用的,但是问题也就来了,有的时候我们只需要加载一个实体,不需要和他相关的外部实体,这时候我们来看看EF延迟加载时怎么作用的吧 打开pr ...
- 懒加载(getter\setter理解)
为什么要用懒加载 1.首先看一下程序启动过程:(如图) 会有一个mian的设置,程序一启动会加载main.storyboard main.storyboard又会加载箭头所指的控制器 控制器一旦加载, ...
- 懒加载插件- jquery.lazyload.js
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件. 它可以延迟加载长页面中的图片. 在浏览器可视区域外的图片不会被载入, 直到用户将页面滚动到它们所在的位置. 这与图片预 ...
- 【转】实现ViewPager懒加载的三种方法
方法一 在Fragment可见时请求数据.此方案仍预加载了前后的页面,但是没有请求数据,只有进入到当前Framgent时才请求数据. 优点:实现了数据的懒加载缺点:一次仍是三个Framgment对象, ...
- 前端实现图片懒加载(lazyload)的两种方式
在实际的项目开发中,我们通常会遇见这样的场景:一个页面有很多图片,而首屏出现的图片大概就一两张,那么我们还要一次性把所有图片都加载出来吗?显然这是愚蠢的,不仅影响页面渲染速度,还浪费带宽.这也就是们通 ...
- 懒加载lazyload
什么是懒加载 懒加载就是当你做滚动到页面某个位置,然后再显示当前位置的图片,这样做可以减少页面请求. 懒加载:主要目的是作为服务器前端的优化,减少请求数或延迟请求数,一些图片非常多的网站中非常有用,在 ...
- 【Android】Fragment懒加载和ViewPager的坑
效果 老规矩,先来看看效果 ANDROID和福利两个Fragment是设置的Fragment可见时加载数据,也就是懒加载.圆形的旋转加载图标只有一个,所以,如果当前Fragment正处于加载状态,在离 ...
- iOS之weak和strong、懒加载及循环引用
一.weak和strong 1.理解 刚开始学UI的时候,对于weak和strong的描述看得最多的就是“由ARC引入,weak相当于OC中的assign,但是weak用于修饰对象,但是他们都不会造成 ...
随机推荐
- linux基础命令---mswap
mkswap 在Linux设备或者文件中创建交换分区,创建完成之后必须使用swapon来使用它.一般在“/etc/fstab”中有一个交换分区列表,这样开机的时候就可以使用它. 此命令的适用范围:Re ...
- Js基础知识4-函数的三种创建、四种调用(及关于new function()的解释)
在js中,函数本身属于对象的一种,因此可以定义.赋值,作为对象的属性或者成为其他函数的参数.函数名只是函数这个对象类的引用. 函数定义 // 函数的三种创建方法(定义方式) function one( ...
- Ubuntu去掉命令行前用户名和主机名方法
Ubuntu去掉命令行前用户名和主机名方法 $ vi ~/.bashrc 按a或i进入编辑模式 PS1='${debian_chroot:+(debian_chroot)}\w\$ ' 默认为 PS1 ...
- API和正则表达式
第一章 String & StringBuilderString类用类final修饰,不能被继承,String字符串被创建后永远无法被改变,但字符串引用可以重新赋值,改变引用的指向java字符 ...
- P4009 汽车加油行驶问题
P4009 汽车加油行驶问题 最短路 清一色的spfa....送上一个堆优化Dijkstra吧(貌似代码还挺短) 顺便说一句,堆优化Dj跑分层图灰常好写 #include<iostream> ...
- 2018-2019-1 20189218《Linux内核原理与分析》第七周作业
task_struck数据结构 在Linux内核中,通过task_struct这个结构体对进程进行管理,我们可以叫他PCB或者进程描述符.这个结构体定义在include/linux/sched.h中. ...
- topcoder srm 620 div1
problem1 link 分别计算可以得到(a,b)的有哪些二元组,以及可以得到(c,d)的有哪些二元组.然后在公共的二元组中找到和最大的即可. problem2 link 设最后的排序为$r=[2 ...
- P3709 大爷的字符串题
题意 询问区间众数出现的次数 思路 唯有水题快人心 离散化+莫队 莫队一定要先加后减,有事会出错的 莫队维护区间众数: 维护两个数组,一个数组记录权值为x的出现次数,一个记录出现次数为x的数的个数 a ...
- ubuntu 安转redis
一 ,redis 安装配置 在 Ubuntu 系统安装 Redis 可以使用以下命令: sudo apt-get update sudo apt-get install redis-server 这样 ...
- 【TCP/IP协议 卷一:协议】第三章 IP:网际协议
3.1 引言 unreliable不可靠的意思是它并不能保证IP数据报能成功的到达目的地.IP只提供尽力而为的传输服务. conectionless无连接的意思是IP并不维护任何关于后续数据报的状态信 ...