小白学习之pytorch框架(2)-动手学深度学习(begin-random.shuffle()、torch.index_select()、nn.Module、nn.Sequential())
在这向大家推荐一本书-花书-动手学深度学习pytorch版,原书用的深度学习框架是MXNet,这个框架经过Gluon重新再封装,使用风格非常接近pytorch,但是由于pytorch越来越火,个人又比较执着,想学pytorch,好,有个大神来了,把《动手学深度学习》整本书用pytorch代码重现了,其GitHub网址为:https://github.com/ShusenTang/Dive-into-DL-PyTorch 原书GitHub网址为:https://github.com/d2l-ai/d2l-zh 看大家爱好,其实客观的说哪个框架都行,只要能实现代码,学会一个框架,另外的就好上手了。菜鸟的见解哈,下面是个人感觉重要的一些
索引(x[:,1])出来和view()改变形状后,结果数据与原数据共享内存,就是修改其中一个,另外一个会跟着修改。类似于数据结构中的链表,指向的地址是同一个
若是想不修改原数据,可以用clone()返回一个副本再修改:x.clone().view(5,3)
item():把一个标量tensor转成python number
梯度
标量out:out.backward() #等价于out.backward(torch.tensor(1))
张量out:调用backward()时需要传入一个和out同形状的权重向量进行加权求和得到一个标量
想要修改tensor的值但又不想被autograd记录(不会影响反向传播),可以通过tensor.data来操作
x = torch.tensor(1.0, requires_grad=True)
print(x.data) # tensor(1.)
print(x.data.requires_grad) # False
y = 2 * x
x.data *= 100
y.backward()
print(x) # tensor(100.,requires_grad=True)
print(x.grad) # tensor(2.) 不是tensor(200.),因为用x.data计算不被记录到计算图内
线性回归实现 参考《动手学深度学习》第三章深度学习基础-线性回归的从零开始实现
这真是一本不错的书,我个人感觉
%matplotlib inline:在开头导入包前加入这个,可以在后面使用matplotlib画图时不用每次都调用pyplot.show()
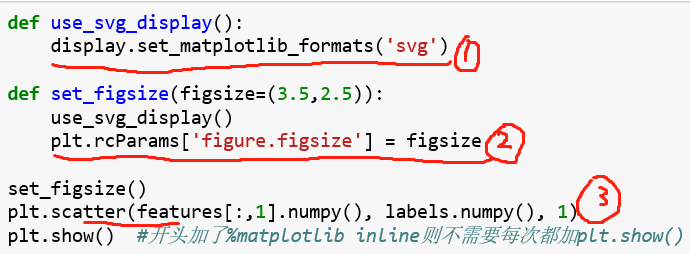
上面的图中,圈1是通过display包设置图像显示的文件格式为svg(可以算是目前最火的图像文件格式)
圈2中的rcParams()函数可以设置图形的各种属性,圈2是设置图像尺寸大小,还有
plt.rcParams['image.interpolation'] = 'nearest' #设置插值
plt.rcParams['image.cmap'] = 'gray' # 设置颜色
plt.rcParams['figure.dpi'] = 300 # 每英寸的点数(图片分辨率)
plt.rcParams['savefig.dpi'] = 300 # 图片像素
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体
plt.rcParams['font.size'] = 10.0 #设置字体大小
plt.rcParams['hist.bins'] = 10 #设置直方图分箱个数
plt.rcParams['lines.linewidth'] = 1.5 #设置线宽
plt.rcParams['text.color'] = 'red' #设置文本颜色
# 还有其他参数可以百度看看
圈3是画散点图,前两个参数是x,y,为点的横纵坐标,第三个是点的大小。其他的参数可百度
记录一下这段读取数据的代码,由于本人太菜了,好不容易查懂不想再重新查
def data_iter(batch_size, features, labels): # 这里batch_size:10 features:(1000,2)的矩阵 labels是经过线性回归公式计算得到的预测值,labels=X*w+b
num_examples = len(features) # features:(1000,2) len(features):1000
indices = list(range(num_examples)) # [0,1,2...,999]
random.shuffle(indices) # 将一个列表中的元素打乱,例子见下面
for i in range(0, num_examples, batch_size): # 0-1000,step=10 [0,10,20,...,999]
j = torch.LongTensor(indices[i:min(i + batch_size, num_examples)]) # 取indice值,并且返回成一个tensor。最后一次可能不足一个batch故用min函数
yield features.index_select(0, j), labels.index_select(0, j) #
yield的理解请移步,https://blog.csdn.net/mieleizhi0522/article/details/82142856 很好理解的,感谢博主了
random.shuffle() # 将一个数组打乱
li = list(range(5)) # [0,1,2,3,4]
random.shuffle(li) # 作用于li列表,而不是print(random.shuffle(li)),这是输不出来的
print(li) # [3,1,0,4,2]
torch之torch.index_select(x,1,indices) # x即要从其中(tensor x中)选择数据的tensor;1代表列,0代表行;indices筛选时的索引序号
x.index_select(n,index) # n代表从第几维开始,index是筛选时的索引序号。index_select(input,dim,index)沿着指定维度对input切片,取index中指定的对应的项。 可以参考博客,感谢博主 https://www.jb51.net/article/174524.htm
数据特征和标签组合
import torch.utils.data as Data batch_size = 10
dataset = Data.TensorDataset(features,labels) #把训练数据的特征和标签(y值)
data_iter = Data.DataLoader(dataset, batch_size,shuffle=True) #读取批量数据,批量大小为batch_size
for X, y in data_iter: # 这样才能打出
print(X, y)
break
搭建模型:
方法1:使用nn.Module定义
from torch import nn
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__()
self.linear = nn.Linear(n_feature, 1) # 定义前向传播
def forward(self, x):
y = self.linear(x)
return y net = LinearNet(num_inputs)
print(net) #显示网络结构
方法2:使用nn.Sequential# nn.Sequential搭建网络
# 写法1
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# 还可加入其他层
) # 写法2
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module.....
# 写法3
from collections import OrderedDict # python内集合的一个模块,使用dict时无法保持key的顺序,而OrderedDict可以保持key的顺序
net = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
])) print(net)
print(net[0])
小白学习之pytorch框架(2)-动手学深度学习(begin-random.shuffle()、torch.index_select()、nn.Module、nn.Sequential())的更多相关文章
- 对比《动手学深度学习》 PDF代码+《神经网络与深度学习 》PDF
随着AlphaGo与李世石大战的落幕,人工智能成为话题焦点.AlphaGo背后的工作原理"深度学习"也跳入大众的视野.什么是深度学习,什么是神经网络,为何一段程序在精密的围棋大赛中 ...
- 【动手学深度学习】Jupyter notebook中 import mxnet出错
问题描述 打开d2l-zh目录,使用jupyter notebook打开文件运行,import mxnet 出现无法导入mxnet模块的问题, 但是命令行运行是可以导入mxnet模块的. 原因: 激活 ...
- 动手学深度学习14- pytorch Dropout 实现与原理
方法 从零开始实现 定义模型参数 网络 评估函数 优化方法 定义损失函数 数据提取与训练评估 pytorch简洁实现 小结 针对深度学习中的过拟合问题,通常使用丢弃法(dropout),丢弃法有很多的 ...
- 动手学深度学习4-线性回归的pytorch简洁实现
导入同样导入之前的包或者模块 生成数据集 通过pytorch读取数据 定义模型 初始化模型 定义损失函数 定义优化算法 训练模型 小结 本节利用pytorch中的模块,生成一个更加简洁的代码来实现同样 ...
- 动手学深度学习11- 多层感知机pytorch简洁实现
多层感知机的简洁实现 定义模型 读取数据并训练数据 损失函数 定义优化算法 小结 多层感知机的简洁实现 import torch from torch import nn from torch.nn ...
- 动手学深度学习9-多层感知机pytorch
多层感知机 隐藏层 激活函数 小结 多层感知机 之前已经介绍过了线性回归和softmax回归在内的单层神经网络,然后深度学习主要学习多层模型,后续将以多层感知机(multilayer percetro ...
- 动手学深度学习8-softmax分类pytorch简洁实现
定义和初始化模型 softamx和交叉熵损失函数 定义优化算法 训练模型 import torch from torch import nn from torch.nn import init imp ...
- 动手学深度学习6-认识Fashion_MNIST图像数据集
获取数据集 读取小批量样本 小结 本节将使用torchvision包,它是服务于pytorch深度学习框架的,主要用来构建计算机视觉模型. torchvision主要由以下几个部分构成: torchv ...
- 《动手学深度学习》系列笔记—— 1.2 Softmax回归与分类模型
目录 softmax的基本概念 交叉熵损失函数 模型训练和预测 获取Fashion-MNIST训练集和读取数据 get dataset softmax从零开始的实现 获取训练集数据和测试集数据 模型参 ...
随机推荐
- RabbitMQ系列文章
详解 RabbitMQ 管理界面解析框架 (一) RabbitMQ系列(二)深入了解RabbitMQ工作原理及简单使用 RabbitMQ windows安装步骤 RabbitMQ管理页面各种属性详解 ...
- Django 异常处理
我们新建一个py文件 # 在restful中导入exception_handler from rest_framework.views import exception_handler from dj ...
- Docker每次启动容器,IP及hosts指定
原文链接:https://blog.csdn.net/u012834750/article/details/80508464 前言 每次在使用Docker启动Hadoop集群的时候,都需要重新绑定下网 ...
- 读书笔记 - js高级程序设计 - 第十章 DOM
文档元素 是文档的最外层元素,在Html页面中,文档元素始终都是<html>元素 在xml中,任何元素都可以是文档元素 Node类型 Node.ELEMENT_NODE 元素 Node ...
- MFC中隐藏和显示光标的切换
函数原型:int ShowCursor(BOOL bShow): 参数: bShow:确定内部的显示计数器是增加还是减少,如果bShow为TRUE,则显示计数器增加1,如果bShow为FALSE,则计 ...
- Codeforces 442A Borya and Hanabi
有五种花色 外加 五种点数 共25张牌,每次有n张牌,主人知道这n张牌中有哪些牌,并且哪种牌有几张,但是不知道具体是哪张牌,他可以问某种花色,然后知道了哪几张是该花色,也可以问点数,然后就知道了哪几张 ...
- [CISCN2019 总决赛 Day1 Web4]Laravel1
0x00 知识点 这个题核心就是找POP链,看了一下网上的WP,难顶啊.. 先贴上思路和poc,之后等熟练了再来做吧 https://glotozz.github.io/2019/11/05/buuc ...
- Dlib笔记二:matrix或array2d与cv::Mat的互转
因为经常习惯的用OpenCV来做图像处理,所以难免希望将其他库的图像数据与OpenCV互转,所以今天就记录下这种互转的方法. 1.dlib::matrix/dlib::array2d转cv::Mat ...
- arp攻击 (可查看同一局域网他人手机照片)
国家法律一定要遵守,知识要用在对的地方. 本贴只为了和大家交流学习,请勿用在其他地方,损害任何人的利益. 今天我,来说一下arp攻击的原理和教程 原理什么的还是自行百度好,因为专业的说明是严谨而又经得 ...
- CTF -bugku-web-web基础 矛盾
---恢复内容开始--- 以GET方式获取参数 is_numeric()函数是判断是否为数字或者数字字符串 所以不能是数字或者数字字符串,但是下面$num == 1 有要求为数字1 所以构造1+任意字 ...