Spark教程——(5)PySpark入门
启动PySpark:
[root@node1 ~]# pyspark
Python 2.7.5 (default, Nov 6 2016, 00:28:07)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-11)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Python version 2.7.5 (default, Nov 6 2016 00:28:07)
SparkContext available as sc, HiveContext available as sqlContext.
上下文已经包含 sc 和 sqlContext:
SparkContext available as sc, HiveContext available as sqlContext.
执行脚本:
>>> from __future__ import print_function
>>> import os
>>> import sys
>>> from pyspark import SparkContext
>>> from pyspark.sql import SQLContext
>>> from pyspark.sql.types import Row, StructField, StructType, StringType, IntegerType# RDD is created from a list of rows
>>> some_rdd = sc.parallelize([Row(name="John", age=19),Row(name="Smith", age=23),Row(name="Sarah", age=18)])# Infer schema from the first row, create a DataFrame and print the schema
>>> some_df = sqlContext.createDataFrame(some_rdd)
>>> some_df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
# Another RDD is created from a list of tuples
>>> another_rdd = sc.parallelize([("John", 19), ("Smith", 23), ("Sarah", 18)])# Schema with two fields - person_name and person_age
>>> schema = StructType([StructField("person_name", StringType(), False),StructField("person_age", IntegerType(), False)])# Create a DataFrame by applying the schema to the RDD and print the schema
>>> another_df = sqlContext.createDataFrame(another_rdd, schema)
>>> another_df.printSchema()
root
|-- person_name: string (nullable = false)
|-- person_age: integer (nullable = false)
进入Github下载people.json文件:
并上传到HDFS上:
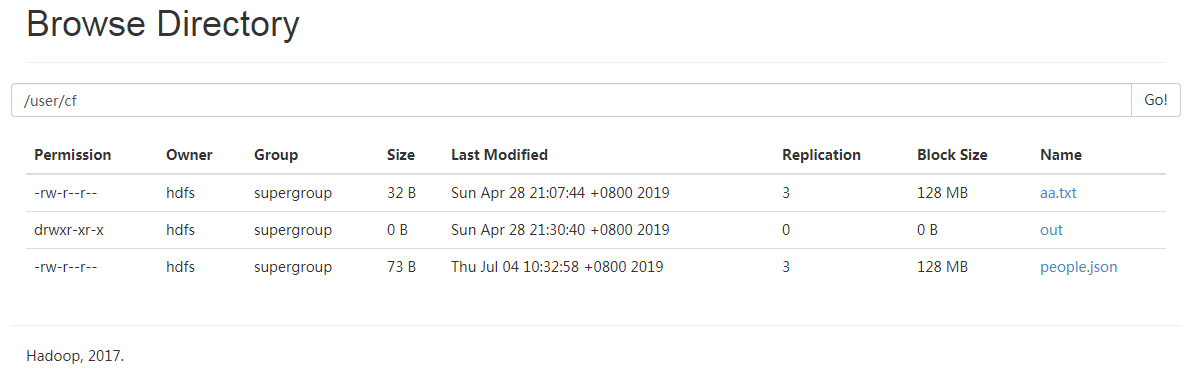
继续执行脚本:
# A JSON dataset is pointed to by path.
# The path can be either a single text file or a directory storing text files.
>>> if len(sys.argv) < 2:
... path = "/user/cf/people.json"
... else:
... path = sys.argv[1]
...
# Create a DataFrame from the file(s) pointed to by path
>>> people = sqlContext.jsonFile(path)
[Stage 5:> (0 + 1) / 2]19/07/04 10:34:33 WARN spark.ExecutorAllocationManager: No stages are running, but numRunningTasks != 0
# The inferred schema can be visualized using the printSchema() method.
>>> people.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
# Register this DataFrame as a table.
>>> people.registerAsTable("people")
/opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/lib/spark/python/pyspark/sql/dataframe.py:142: UserWarning: Use registerTempTable instead of registerAsTable.
warnings.warn("Use registerTempTable instead of registerAsTable.")
# SQL statements can be run by using the sql methods provided by sqlContext
>>> teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
>>> for each in teenagers.collect():
... print(each[0])
...
Justin
执行结束:
>>> sc.stop() >>>
参考程序:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
from __future__ import print_function
import os
import sys
from pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import Row, StructField, StructType, StringType, IntegerType
if __name__ == "__main__":
sc = SparkContext(appName="PythonSQL")
sqlContext = SQLContext(sc)
# RDD is created from a list of rows
some_rdd = sc.parallelize([Row(name="John", age=19),
Row(name="Smith", age=23),
Row(name="Sarah", age=18)])
# Infer schema from the first row, create a DataFrame and print the schema
some_df = sqlContext.createDataFrame(some_rdd)
some_df.printSchema()
# Another RDD is created from a list of tuples
another_rdd = sc.parallelize([("John", 19), ("Smith", 23), ("Sarah", 18)])
# Schema with two fields - person_name and person_age
schema = StructType([StructField("person_name", StringType(), False),
StructField("person_age", IntegerType(), False)])
# Create a DataFrame by applying the schema to the RDD and print the schema
another_df = sqlContext.createDataFrame(another_rdd, schema)
another_df.printSchema()
# root
# |-- age: integer (nullable = true)
# |-- name: string (nullable = true)
# A JSON dataset is pointed to by path.
# The path can be either a single text file or a directory storing text files.
if len(sys.argv) < 2:
path = "file://" + \
os.path.join(os.environ['SPARK_HOME'], "examples/src/main/resources/people.json")
else:
path = sys.argv[1]
# Create a DataFrame from the file(s) pointed to by path
people = sqlContext.jsonFile(path)
# root
# |-- person_name: string (nullable = false)
# |-- person_age: integer (nullable = false)
# The inferred schema can be visualized using the printSchema() method.
people.printSchema()
# root
# |-- age: IntegerType
# |-- name: StringType
# Register this DataFrame as a table.
people.registerAsTable("people")
# SQL statements can be run by using the sql methods provided by sqlContext
teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
for each in teenagers.collect():
print(each[0])
sc.stop()
Spark教程——(5)PySpark入门的更多相关文章
- Spark教程——(11)Spark程序local模式执行、cluster模式执行以及Oozie/Hue执行的设置方式
本地执行Spark SQL程序: package com.fc //import common.util.{phoenixConnectMode, timeUtil} import org.apach ...
- Spring_MVC_教程_快速入门_深入分析
Spring MVC 教程,快速入门,深入分析 博客分类: SPRING Spring MVC 教程快速入门 资源下载: Spring_MVC_教程_快速入门_深入分析V1.1.pdf Spring ...
- AFNnetworking快速教程,官方入门教程译
AFNnetworking快速教程,官方入门教程译 分类: IOS2013-12-15 20:29 12489人阅读 评论(5) 收藏 举报 afnetworkingjsonios入门教程快速教程 A ...
- 【译】ASP.NET MVC 5 教程 - 1:入门
原文:[译]ASP.NET MVC 5 教程 - 1:入门 本教程将教你使用Visual Studio 2013 预览版构建 ASP.NET MVC 5 Web 应用程序 的基础知识.本主题还附带了一 ...
- Nginx教程(一) Nginx入门教程
Nginx教程(一) Nginx入门教程 1 Nginx入门教程 Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like协议下发行.由 ...
- spark教程
某大神总结的spark教程, 地址 http://litaotao.github.io/introduction-to-spark?s=inner
- Android基础-系统架构分析,环境搭建,下载Android Studio,AndroidDevTools,Git使用教程,Github入门,界面设计介绍
系统架构分析 Android体系结构 安卓结构有四大层,五个部分,Android分四层为: 应用层(Applications),应用框架层(Application Framework),系统运行层(L ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- spark教程(七)-文件读取案例
sparkSession 读取 csv 1. 利用 sparkSession 作为 spark 切入点 2. 读取 单个 csv 和 多个 csv from pyspark.sql import Sp ...
- spark教程(六)-Python 编程与 spark-submit 命令
hadoop 是 java 开发的,原生支持 java:spark 是 scala 开发的,原生支持 scala: spark 还支持 java.python.R,本文只介绍 python spark ...
随机推荐
- pandas read excel or csv
import pandas as pd """pandas doc:df.dtypes 查看数据每column 数据类型 id int64x0 float64df.rei ...
- pikachu-搜索型注入 #手工注入
1.搜索型注入漏洞产生的原因: 在搭建网站的时候为了方便用户搜索该网站中的资源,程序员在写网站脚本的时候加入了搜索功能,但是忽略了对搜索变量的过滤,造成了搜索型注入漏洞,又称文本框注入. 2.搜索型注 ...
- C语言函数不能返回数组,但可以返回结构体
为什么C语言函数可以返回结构体,却不可以返回数组?有这样的问题并不奇怪,因为C语言数组和结构体本质上都是管理一块内存,那为何编译器要区别对待二者呢? C语言函数为什么不能返回数组? 在C语言程序开发中 ...
- Java面向对象编程 -4
声明static属性 static 是一个关键字,这个关键字主要是用来定义属性和方法. static内存分析 在正常开发之中每一个对象都要保存有各自的属性 所以此时程序没有问题 但是如果country ...
- PostgreSQL数据库-分页sql--offset
select * from users order by score desc limit 3;--取成绩的前3名=====select * from users order by score des ...
- Spring MVC 解读——@Autowired、@Controller、@Service从原理层面来分析
目录(?)[+] Spring MVC 解读Autowired 一Autowired 二BeanPostProcessor 三磨刀砍柴 四Bean 工厂 五实例化与装配 六执行装配 七一切的开始 ...
- C++11常用特性介绍——array容器
std::array是具有固定大小的数组,支持快速随机访问,不能添加或删除元素,定义于头文件<array>中. 一.概要 array是C++11新引入的容器类型,与内置数组相比,array ...
- [理解] C++ 中的 源文件 和 头文件
我是学 C井 的, 现在在工作中主要使用的编程语言是 Java, 还记得当初在第一次接触到 Cpp 的时候, 听到的第一个概念就是 Cpp 的头文件和源文件, 当初理解了好久, 死活都弄不明白, 现在 ...
- CAN数据格式-BLF
欢迎关注<汽车软件技术>公众号,回复关键字获取资料. Vector工具录制的数据,一般有ASC和BLF两种格式,本文介绍ASC. 1.BLF定义 BLF(binary logging fo ...
- SpringBoot与Jpa入门
一.JPA简介 目前JPA主要实现由hibernate和openJPA等. Spring Data JPA 是Spring Data 的一个子项目,它通过提供基于JPA的Repository极大了减少 ...