二十、oracle通过复合索引优化查询及不走索引的8种情况
1. 理解ROWID
ROWID是由Oracle自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值;你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作;一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
SELECT t.rowid,t.* FROM DM_COMM_PREM_LIST t where LIST_ID= '3106355531';
2. SQL优化器优化方式
1)基于规则的优化器RBO(Rule-Based Optimization)
RBO有严格的使用规则,只要按照这套规则去写SQL语句,无论数据表中的内容怎样,也不会影响到你的执行计划;换句话说,RBO对数据“不敏感”,它要求SQL编写人员必须要了解各项细则;RBO一直沿用至ORACLE 9i,从ORACLE 10g开始,RBO已经彻底被抛弃。
2)基于成本的优化器CBO(Cost-Based Optimization)
CBO是一种比RBO更加合理、可靠的优化器,在ORACLE 10g中完全取代RBO;CBO通过计算各种可能的执行计划的“代价”,即COST,从中选用COST最低的执行方案作为实际运行方案;它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择,也就是对数据“敏感”。
3. 基于SQL优化器创建有效复合索引
3.1)INDEX SKIP SCAN(复合索引之索引跳跃扫描)
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,
这时候就使用的INDEX SKIP SCAN;
3.2)什么时候会触发 INDEX SKIP SCAN
前提条件:表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器模式为CBO时当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;
例如:
假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;因为性别只有 '男' 和 '女' 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('男', ename, job),('女', ename, job)这两个复合索引;当查询 select * from emp where job = 'Programmer' 时该查询发出后: Oracle先进入sex为'男'的入口,这时候使用到了 ('男', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;再进入sex为'女'的入口,这时候使用到了 ('女', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;最后合并查询到的来自两个入口的结果集。
3.3)创建满足索引跳跃扫描条件的复合索引(含日期字段)后,但是查看执行计划却发现并未走复合索引
如:创建索引跳跃扫描 create index IDX_DM_FINISHTIME_ORGANID on DM_COMM_PREM_LIST (FINISH_TIME,ORGAN_ID) ;
查询执行计划如下图,发现未会走复合索引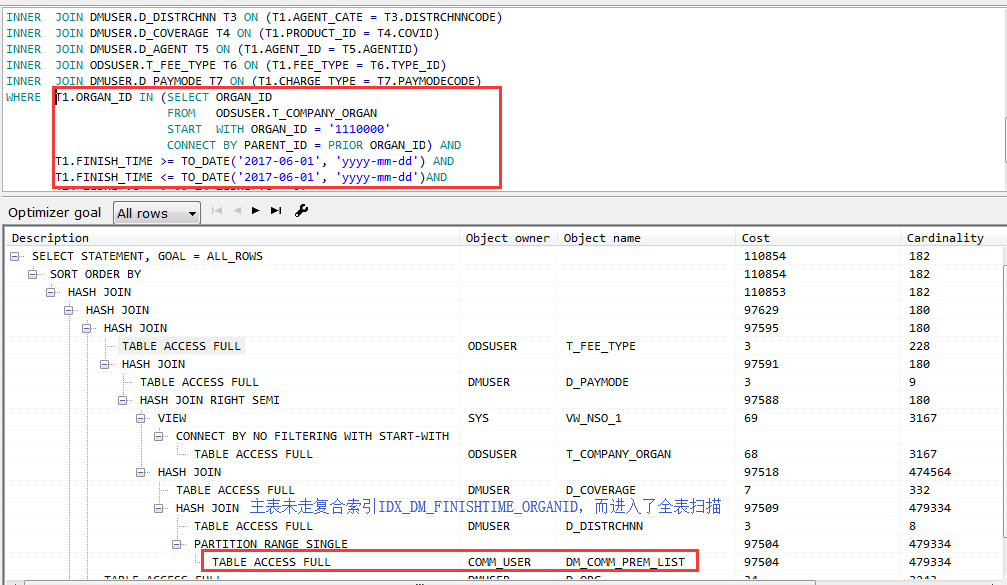
如何解决此问题:修改日期设定的格式T1.FINISH_TIME >= TO_DATE('2017-06-01', 'yyyy-mm-ddhh24miss') AND T1.FINISH_TIME <= TO_DATE('2017-06-23', 'yyyy-mm-ddhh24miss');通过将传入参数格式化成对应yyyy-mm-ddhh24miss格式字符串,这样由Oracle将字符串转成Date类型,就很顺利的走索引区间扫描。效果如下:

参看博文:http://programdolt.iteye.com/blog/1186690
4.不走索引的原因,大概有如下8种:
1)建立组合索引,但查询谓词并未使用组合索引的第一列,此处有一个INDEX SKIP SCAN概念。
2)在包含有null值的table列上建立索引,当时使用select count(*) from table时不会使用索引。
3)在索引列上使用函数时不会使用索引,如果一定要使用索引只能建立函数索引。
如:Where条件中对字段增加处理函数将不使用该列的索引
select * from emp where to_char(hire_date,'yyyymmdd')='20080411' (不使用)
select * from emp where hire_date = to_char('20080411','yyyymmdd') (使用)
4)当被索引的列进行隐式的类型转换时不会使用索引。
示例1:
select * from t where indexed_column = 5,而indexed_column列建立索引但类型是字符型,这时Oracle会产生隐式的类型转换,转换后的语句类似于select * from t where to_number(indexed_column) = 5,此时不走索引的情况类似于case3
示例2:日期转换也有类似问题
select * from t where trunc(date_col) = trunc(sysdate)其中date_col为索引列,这样写不会走索引,可改写成select * from t where date_col >= trunc(sysdate) and date_col < trunc(sysdate+1),此查询会走索引。
5)并不是所有情况使用索引都会加快查询速度,full scan table 有时会更快,尤其是当查询的数据量占整个表的比重较大时,因为full scan table采用的是多块读,
当Oracle优化器没有选择使用索引时不要立即强制使用,要充分证明使用索引确实查询更快时再使用强制索引。
6)<>
7)like’%dd’百分号在前
8)not in ,not exist
oracle中的索引扫描共计5种,本章只介绍INDEX SKIP SCAN(索引跳跃扫描),其他四种索引扫描会在另外章节总结。
INDEX UNIQUE SCAN(索引唯一扫描)
INDEX RANGE SCAN(索引范围扫描)
INDEX FULL SCAN(索引全扫描)
INDEX FAST FULL SCAN(索引快速扫描)
参看博文:
https://www.cnblogs.com/sthinker/p/6080307.html
https://www.cnblogs.com/Dreamer-1/p/6076440.html
二十、oracle通过复合索引优化查询及不走索引的8种情况的更多相关文章
- mysql索引之四:复合索引之最左前缀原理,索引选择性,索引优化策略之前缀索引
高效使用索引的首要条件是知道什么样的查询会使用到索引,这个问题和B+Tree中的“最左前缀原理”有关,下面通过例子说明最左前缀原理. 一.最左前缀索引 这里先说一下联合索引的概念.MySQL中的索引可 ...
- Oracle大数据常见优化查询
[转]http://www.cnblogs.com/myhappylife/p/5006774.html 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的 ...
- mysql千万级数据量根据索引优化查询速度
(一)索引的作用 索引通俗来讲就相当于书的目录,当我们根据条件查询的时候,没有索引,便需要全表扫描,数据量少还可以,一旦数据量超过百万甚至千万,一条查询sql执行往往需要几十秒甚至更多,5秒以上就已经 ...
- oracle 百万行数据优化查询
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- mysql数据库添加索引优化查询效率
项目中如果表中的数据过多的话,会影响查询的效率,那么我们需要想办法优化查询,通常添加索引就是我们的选择之一: 1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `t ...
- mysql之数据库添加索引优化查询效率
项目中如果表中的数据过多的话,会影响查询的效率,那么我们需要想办法优化查询,通常添加索引就是我们的选择之一: 1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `t ...
- mysql 索引优化,索引建立原则和不走索引的原因
第一:选择唯一性索引 唯一性索引的值是唯一的,可以更快捷的通过该索引来确定某条记录. 2.索引的列为where 后面经常作为条件的字段建立索引 如果某个字段经常作为查询条件,而且又有较少的重复列或者是 ...
- SQL语句优化、mysql不走索引的原因、数据库索引的设计原则
SQL语句优化 1 企业SQL优化思路 1.把一个大的不使用索引的SQL语句按照功能进行拆分 2.长的SQL语句无法使用索引,能不能变成2条短的SQL语句让它分别使用上索引. 3.对SQL语句功能的拆 ...
随机推荐
- 15 个优秀开源的 Spring Boot 学习项目
Spring Boot 算是目前 Java 领域最火的技术栈了,松哥年初出版的 <Spring Boot + Vue 全栈开发实战>迄今为止已经加印了 8 次,Spring Boot 的受 ...
- 根据权限显示accordion
前端界面: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Home.asp ...
- UIView的API
- (instancetype)initWithFrame:(CGRect)frame; 使用指定的框架矩形初始化并返回新分配的视图对象. - (instancetype)initWithCoder: ...
- IPSec的链路和设备备份
链路备份的IPSec VPN和设备备份的IPSec VPN:首先实验的是链路备份的 IPSec VPN,下面是实验拓扑: IP地址配置:R1(Branch):Branch(config-if)#ip ...
- Python中的代码块及其缓存机制、深浅copy
一.代码块及其缓存机制 代码块 一个模块.一个函数.一个类.一个文件等都是一个代码块:交互式命令下,一行就是一个代码块. 同一个代码块内的缓存机制(字符串驻留机制) 机制内容:Python在执行同一个 ...
- stm32CubeMx lwip + freeRTOS
MCU: STM32F429IGT6 工具:STM32CubeMx 版本号 5.0.0 Keil uVersion5 目的:使用LWIP 实现简单的网络连通 一 简介 LWIP(Light Wei ...
- Mysql安装 ----> 基于源码包安装
1)基于源码包安装MySQL [root@localhost ~]# rpm -q mysql mysql-server mariadb mairadb-server //检查有没 ...
- 2019年5月6日A股两百点暴跌行情思考
原因:特朗普推特发布贸易战消息 盘面:跳空低开,单边下跌,上证指数最大跌幅200点,收盘千股跌停 操作:开盘加仓,盘中加仓,尾盘满仓 总结: 特大黑天鹅事件爆发引发大盘暴跌时,后续必将迎来一个反弹机会 ...
- 【转】python创建和删除文件
#!/usr/bin/python #-*-coding:utf-8-*- #指定编码格式,python默认unicode编码 import os directory = "./dir&qu ...
- 夯实Java基础(二十三)——Java8新特征之Stream API
1.Stream简介 Java8中除了引入了好用的Lambda表达式.Date API之外,另外还有一大亮点就是Stream API了,也是最值得所有Java开发人员学习的一个知识点,因为它的功能非常 ...