15.DRF-分页
Django rest framework(6)----分页
第一种分页 PageNumberPagination
基本使用
(1)urls.py
urlpatterns = [
re_path('(?P<version>[v1|v2]+)/page1/', Pager1View.as_view(),) #分页1
]
(2)api/utils/serializers/pager.py
# api/utils/serializsers/pager.py
from rest_framework import serializers
from api import models
class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model = models.Role
fields = "__all__"
(3)views.py
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles = models.Role.objects.all()
#创建分页对象
pg = PageNumberPagination()
#获取分页的数据
page_roles = pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles,many=True)
return Response(ser.data)
(4)settings配置
REST_FRAMEWORK = {
#分页
"PAGE_SIZE":2 #每页显示多少个
}

自定义分页类
#自定义分页类
class MyPageNumberPagination(PageNumberPagination):
#每页显示多少个
page_size = 3
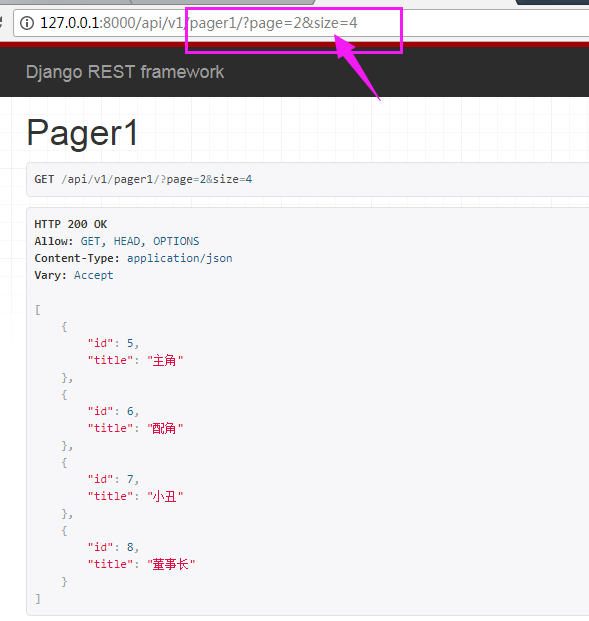
#默认每页显示3个,可以通过传入pager1/?page=2&size=4,改变默认每页显示的个数
page_size_query_param = "size"
#最大页数不超过10
max_page_size = 10
#获取页码数的
page_query_param = "page"
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles = models.Role.objects.all()
#创建分页对象,这里是自定义的MyPageNumberPagination
pg = MyPageNumberPagination()
#获取分页的数据
page_roles = pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles,many=True)
return Response(ser.data)
第二种分页 LimitOffsetPagination
自定义
#自定义分页类2
class MyLimitOffsetPagination(LimitOffsetPagination):
#默认显示的个数
default_limit = 2
#当前的位置
offset_query_param = "offset"
#通过limit改变默认显示的个数
limit_query_param = "limit"
#一页最多显示的个数
max_limit = 10
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles = models.Role.objects.all()
#创建分页对象
pg = MyLimitOffsetPagination()
#获取分页的数据
page_roles = pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles,many=True)
return Response(ser.data)


返回的时候可以用get_paginated_response方法
自带上一页下一页

第三种分页 CursorPagination
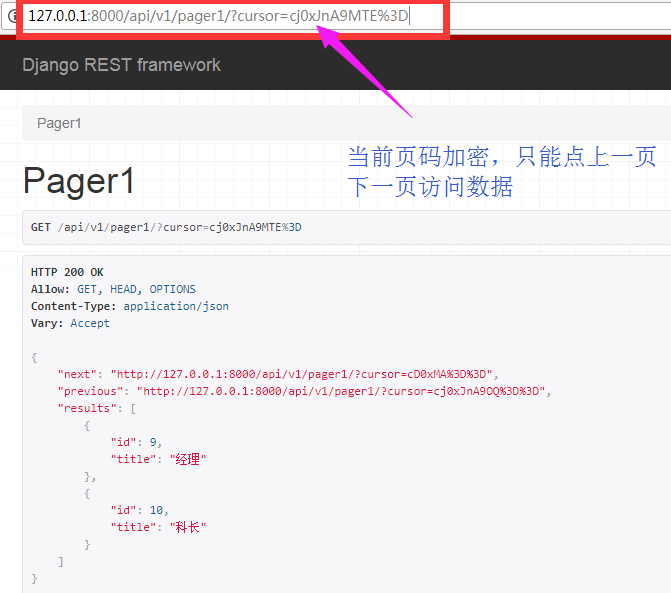
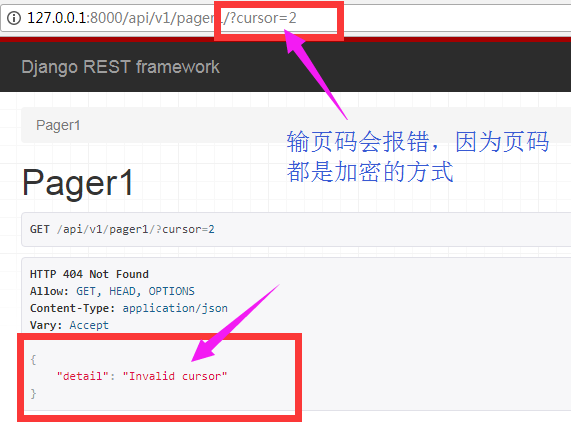
加密分页方式,只能通过点“上一页”和下一页访问数据
#自定义分页类3 (加密分页)
class MyCursorPagination(CursorPagination):
cursor_query_param = "cursor"
page_size = 2 #每页显示2个数据
ordering = 'id' #排序
page_size_query_param = None
max_page_size = None
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles = models.Role.objects.all()
#创建分页对象
pg = MyCursorPagination()
#获取分页的数据
page_roles = pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles,many=True)
# return Response(ser.data)
return pg.get_paginated_response(ser.data)
代码
版本、解析器、序列化和分页
# MyProject2/urls.py
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
#path('admin/', admin.site.urls),
path('api/',include('api.urls') ),
]
# api/urls.py
from django.urls import path,re_path
from .views import UserView,PaserView,RolesView,UserInfoView,GroupView,UserGroupView
from .views import Pager1View
urlpatterns = [
re_path('(?P<version>[v1|v2]+)/users/', UserView.as_view(),name = 'api_user'), #版本
path('paser/', PaserView.as_view(),), #解析
re_path('(?P<version>[v1|v2]+)/roles/', RolesView.as_view()), #序列化
re_path('(?P<version>[v1|v2]+)/info/', UserInfoView.as_view()), #序列化
re_path('(?P<version>[v1|v2]+)/group/(?P<pk>\d+)/', GroupView.as_view(),name = 'gp'), #序列化生成url
re_path('(?P<version>[v1|v2]+)/usergroup/', UserGroupView.as_view(),), #序列化做验证
re_path('(?P<version>[v1|v2]+)/pager1/', Pager1View.as_view(),) #分页1
]
# api/models.py
from django.db import models
class UserInfo(models.Model):
USER_TYPE = (
(1,'普通用户'),
(2,'VIP'),
(3,'SVIP')
)
user_type = models.IntegerField(choices=USER_TYPE)
username = models.CharField(max_length=32,unique=True)
password = models.CharField(max_length=64)
group = models.ForeignKey('UserGroup',on_delete=models.CASCADE)
roles = models.ManyToManyField('Role')
class UserToken(models.Model):
user = models.OneToOneField('UserInfo',on_delete=models.CASCADE)
token = models.CharField(max_length=64)
class UserGroup(models.Model):
title = models.CharField(max_length=32)
class Role(models.Model):
title = models.CharField(max_length=32)
# api/views.py
import json
from django.shortcuts import render,HttpResponse
from rest_framework.views import APIView
from rest_framework.request import Request
from rest_framework.versioning import URLPathVersioning
from . import models
##########################################版本和解析器#####################################################
class UserView(APIView):
def get(self,request,*args,**kwargs):
#获取版本
print(request.version)
#获取处理版本的对象
print(request.versioning_scheme)
#获取浏览器访问的url,reverse反向解析
#需要两个参数:viewname就是url中的别名,request=request是url中要传入的参数
#(?P<version>[v1|v2]+)/users/,这里本来需要传version的参数,但是version包含在request里面,所有只需要request=request就可以
url_path = request.versioning_scheme.reverse(viewname='api_user',request=request)
print(url_path)
self.dispatch
return HttpResponse('用户列表')
# from rest_framework.parsers import JSONParser,FormParser
class PaserView(APIView):
'''解析'''
# parser_classes = [JSONParser,FormParser,]
#JSONParser:表示只能解析content-type:application/json的头
#FormParser:表示只能解析content-type:application/x-www-form-urlencoded的头
def post(self,request,*args,**kwargs):
#获取解析后的结果
print(request.data)
return HttpResponse('paser')
###########################################序列化###########################################################
from rest_framework import serializers
#要先写一个序列化的类
class RolesSerializer(serializers.Serializer):
#Role表里面的字段id和title序列化
id = serializers.IntegerField()
title = serializers.CharField()
class RolesView(APIView):
def get(self,request,*args,**kwargs):
# 方式一:对于[obj,obj,obj]
# (Queryset)
# roles = models.Role.objects.all()
# 序列化,两个参数,instance:Queryset 如果有多个值,就需要加 mangy=True
# ser = RolesSerializer(instance=roles,many=True)
# 转成json格式,ensure_ascii=False表示显示中文,默认为True
# ret = json.dumps(ser.data,ensure_ascii=False)
# 方式二:
role = models.Role.objects.all().first()
ser = RolesSerializer(instance=role, many=False)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
# class UserInfoSerializer(serializers.Serializer):
# '''序列化用户的信息'''
# #user_type是choices(1,2,3),显示全称的方法用source
# type = serializers.CharField(source="get_user_type_display")
# username = serializers.CharField()
# password = serializers.CharField()
# #group.title:组的名字
# group = serializers.CharField(source="group.title")
# #SerializerMethodField(),表示自定义显示
# #然后写一个自定义的方法
# rls = serializers.SerializerMethodField()
#
# def get_rls(self,row):
# #获取用户所有的角色
# role_obj_list = row.roles.all()
# ret = []
# #获取角色的id和名字
# #以字典的键值对方式显示
# for item in role_obj_list:
# ret.append({"id":item.id,"title":item.title})
# return ret
# class UserInfoSerializer(serializers.ModelSerializer):
# type = serializers.CharField(source="get_user_type_display")
# group = serializers.CharField(source="group.title")
# rls = serializers.SerializerMethodField()
#
# def get_rls(self, row):
# # 获取用户所有的角色
# role_obj_list = row.roles.all()
# ret = []
# # 获取角色的id和名字
# # 以字典的键值对方式显示
# for item in role_obj_list:
# ret.append({"id": item.id, "title": item.title})
# return ret
#
# class Meta:
# model = models.UserInfo
# fields = ['id','username','password','type','group','rls']
# class UserInfoSerializer(serializers.ModelSerializer):
# class Meta:
# model = models.UserInfo
# #fields = "__all__"
# fields = ['id','username','password','group','roles']
# #表示连表的深度
# depth = 1
class UserInfoSerializer(serializers.ModelSerializer):
group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='pk')
class Meta:
model = models.UserInfo
#fields = "__all__"
fields = ['id','username','password','group','roles']
#表示连表的深度
depth = 0
class UserInfoView(APIView):
'''用户的信息'''
def get(self,request,*args,**kwargs):
users = models.UserInfo.objects.all()
#这里必须要传参数context={'request':request}
ser = UserInfoSerializer(instance=users,many=True,context={'request':request})
ret = json.dumps(ser.data,ensure_ascii=False)
return HttpResponse(ret)
class GroupSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserGroup
fields = "__all__"
class GroupView(APIView):
def get(self,request,*args,**kwargs):
pk = kwargs.get('pk')
obj = models.UserGroup.objects.filter(pk=pk).first()
ser = GroupSerializer(instance=obj,many=False)
ret = json.dumps(ser.data,ensure_ascii=False)
return HttpResponse(ret)
####################################序列化之用户请求数据验证验证####################################
#自定义验证规则
class GroupValidation(object):
def __init__(self,base):
self.base = base
def __call__(self, value):
if not value.startswith(self.base):
message = "标题必须以%s为开头"%self.base
raise serializers.ValidationError(message)
class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField(validators=[GroupValidation('以我开头'),])
class UserGroupView(APIView):
def post(self,request,*args, **kwargs):
ser = UserGroupSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
else:
print(ser.errors)
return HttpResponse("用户提交数据验证")
##################################################分页###################################################
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
# #自定义分页类1
# class MyPageNumberPagination(PageNumberPagination):
# #每页显示多少个
# page_size = 3
# #默认每页显示3个,可以通过传入pager1/?page=2&size=4,改变默认每页显示的个数
# page_size_query_param = "size"
# #最大页数不超过10
# max_page_size = 10
# #获取页码数的
# page_query_param = "page"
#自定义分页类2
class MyLimitOffsetPagination(LimitOffsetPagination):
#默认显示的个数
default_limit = 2
#当前的位置
offset_query_param = "offset"
#通过limit改变默认显示的个数
limit_query_param = "limit"
#一页最多显示的个数
max_limit = 10
#自定义分页类3 (加密分页)
class MyCursorPagination(CursorPagination):
cursor_query_param = "cursor"
page_size = 2 #每页显示2个数据
ordering = 'id' #排序
page_size_query_param = None
max_page_size = None
class Pager1View(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles = models.Role.objects.all()
#创建分页对象
pg = MyCursorPagination()
#获取分页的数据
page_roles = pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles,many=True)
return Response(ser.data)
# return pg.get_paginated_response(ser.data)
# api/utils/serializsers/pager.py
from rest_framework import serializers
from api import models
class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model = models.Role
fields = "__all__"
api/utils/serializsers/pager.py
15.DRF-分页的更多相关文章
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- laravel基础课程---15、分页及验证码(lavarel分页效果如何实现)
laravel基础课程---15.分页及验证码(lavarel分页效果如何实现) 一.总结 一句话总结: 数据库的paginate方法:$data=\DB::table("user" ...
- drf 分页,获取fk,choise,m2m等字段数据(序列化)
1.什么是restful规范 是一套规则,用于程序之间进行数据交换的约定. 他规定了一些协议,对我们感受最直接的的是,以前写增删改查需要写4个接口,restful规范的就是1个接口,根据method的 ...
- Django DRF 分页
Django DRF 分页 分页在DRF当中可以一共有三种,可以通过setttings设置,也可也通过自定义设置 PageNumberPagination 使用URL http://127.0.0.1 ...
- DRF 分页组件
Django Rest Framework 分页组件 DRF的分页 为什么要使用分页 其实这个不说大家都知道,大家写项目的时候也是一定会用的, 我们数据库有几千万条数据,这些数据需要展示,我们不可能直 ...
- DRF分页组件
为什么要使用分页 其实这个不说大家都知道,大家写项目的时候也是一定会用的, 我们数据库有几千万条数据,这些数据需要展示,我们不可能直接从数据库把数据全部读取出来, 这样会给内存造成特别大的压力,有可能 ...
- 【DRF分页】
目录 第一种 PageNumberPagination 查第n页,每页显示n条数据 第二种 LimitOffsetPagination 在第n个位置,向后查n条数据 第三种 CursorPaginat ...
- 15.DRF学习以及相关源码阅读
1.http请求协议 代码很枯燥,结果和奇妙. 1.cbv django.vuews import View classs LoginView(View): def get(self,requset) ...
- drf分页组件补充
drf偏移分页组件 pahenations.py from rest_framework.pagination import LimitOffsetPagination class MyLimitOf ...
- drf分页功能
什么是restful规范 是一套规则,用于程序之间进行数据交换的约定. 他规定了一些协议,对我们感受最直接的的是,以前写增删改查需要写4个接口,restful规范的就是1 个接口,根据method的不 ...
随机推荐
- C# 7.0 新增功能&结合微软简化理解
C# 7.0更新时间为2019.2左右 C# 7.0 ~ 7.3 分别需要VS2017 与 .NET Core 1.0. .NET Core 2.0 SDK..NET Core 2.1 SDK,需要在 ...
- 基于 kubeadm 搭建高可用的kubernetes 1.18.2 (k8s)集群一 环境准备
本k8s集群参考了 Michael 的 https://gitee.com/pa/kubernetes-ha-kubeadm-private 这个项目,再此表示感谢! Michael的项目k8s版本为 ...
- Car的旅行路线 luogu P1027 (Floyd玄学Bug有点毒瘤)
luogu题目传送门! Car的旅行路线 问题描述 又到暑假了,住在城市A的Car想和朋友一起去城市B旅游.她知道每个城市都有四个飞机场,分别位于一个矩形的四个顶点上,同一个城市中两个机场之间有一 ...
- html css javascript实现弹弹球
效果如图: 原创代码: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> & ...
- api.versioning 版本控制 自动识别最高版本
Microsoft.AspNetCore.Mvc.Versioning //引入程序集 .net core 下面api的版本控制作用不需要多说,可以查阅https://www.cnblogs.com/ ...
- Java实现 第十一届 蓝桥杯 (本科组)省内模拟赛
有错误的或者有问题的欢迎评论 计算机存储中有多少字节 合法括号序列 无向连通图最少包含多少条边 字母重新排列 凯撒密码加密 反倍数 正整数的摆动序列 螺旋矩阵 小明植树 户户通电 计算机存储中有多少字 ...
- (Java实现) 零件分组
零件分组(Stick)-动态规划-中高级 Case Time Limit:1000MS Time Limit: 3000MS Memory Limit: 65536K Total Submission ...
- Java实现 蓝桥杯 算法训练 大小写转换
算法训练 大小写转换 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 编写一个程序,输入一个字符串(长度不超过20),然后把这个字符串内的每一个字符进行大小写变换,即将大写字母变成小 ...
- Java实现 蓝桥杯 历届试题 小计算器
历届试题 小计算器 时间限制:1.0s 内存限制:256.0MB 问题描述 模拟程序型计算器,依次输入指令,可能包含的指令有 1. 数字:'NUM X',X为一个只包含大写字母和数字的字符串,表示一个 ...
- CSDN如何获得2020技术圈认证(新徽章哦)
打开CSDN APP 然后登陆上就可以了 把这些看完了就可以了