分布式ID生成策略 · fossi
分布式环境下如何保证ID的不重复呢?一般我们可能会想到用UUID来实现嘛。但是UUID一般可以获取当前时间的毫秒数再加点随机数,但是在高并发下仍然可能重复。最重要的是,如果我要用这种UUID来生成分表的唯一ID的话,重复不谈,这种随机的字符串对于我们的innodb存储引擎的插入效率是很低的。所以我们生成的ID如果作为主键,最好有两种特性:分布式唯一和有序。
唯一性就不用说了,有序保证了对索引字段的插入的高效性。我们来具体看看ShardingJDBC的分布式ID生成策略是如何保证。
snowflake算法

sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID)。
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如MySQL的Innodb存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
雪花算法主键的详细结构见下图。
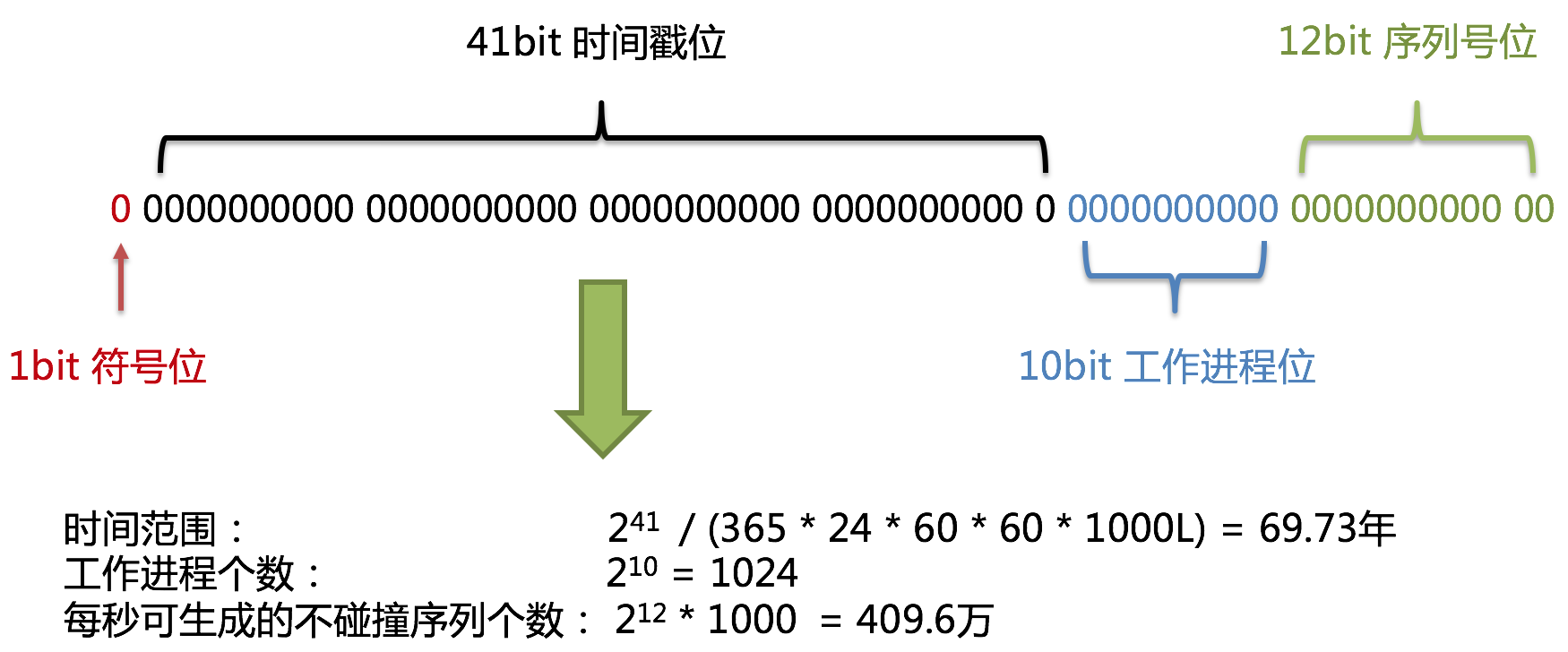
- 符号位(1bit)
预留的符号位,恒为零。
- 时间戳位(41bit)
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
1 |
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); |
结果约等于69.73年。ShardingSphere的雪花算法的时间纪元从2016年11月1日零点开始,可以使用到2086年,相信能满足绝大部分系统的要求。
- 工作进程位(10bit)
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过调用静态方法DefaultKeyGenerator.setWorkerId()设置。
- 序列号位(12bit)
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。
时钟回拨
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为0,可通过调用静态方法DefaultKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds()设置。
分布式ID生成策略 · fossi的更多相关文章
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 分布式ID生成策略之ZK
import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFra ...
- Disruptor分布式id生成策略
需要的pom文件: <!-- 顺序UUID --> <dependency> <groupId>com.fasterxml.uuid</groupId> ...
- 分布式ID生成策略
策略一.UUID 策略二.数据库自增序列 策略三.snowflake算法 策略四.基于redis自增 思路:利用增长计数API,业务系统在自增长的基础上,配合其他信息组装成为一个唯一ID. redis ...
- 业务ID 生成策略
业务ID 生成策略,从技术上说,基本要借助一个集中式的引擎来帮忙实现. 为了扩大业务ID生成策略的并发问题,还有更为技巧性的提升. 先来介绍普遍的分布式ID生成策略: 1. 利用DB的自增主键 这里又 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- 架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里 一.全局ID简介 在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理.比如常见的: 订单:order ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
随机推荐
- ZJNU 1269 - 灯塔——高级
根据题目输入可以得到一个有向图 信号可以根据有向图的传递性传递,因此可以说是找到这个有向图的所有父亲即可 但又要考虑可能会出现环这类情况 所以跑一遍强连通分量模板,再根据分块后的图找到入度为0的块,把 ...
- Linux-父进程wait回收子进程
1.wait工作原理 (1).子进程结束时,系统向其父进程发送SIGCHILD信号 (2).父进程调用wait函数后阻塞 (3).父进程被SIGCHILD信号唤醒然后去回收僵尸子进程 (4).父子进程 ...
- cf1172E Nauuo and ODT(LCT)
首先可以转化问题,变为对每种颜色分别考虑不含该颜色的简单路径条数.然后把不是当前颜色的点视为白色,是当前颜色的点视为黑色,显然路径数量是每个白色连通块大小的平方和,然后题目变为:黑白两色的树,单点翻转 ...
- Python笔记_第一篇_面向过程_第一部分_5.Python数据类型之字典类型(dict)
字典!在Python中字典是另一种可变容器模型,可以存储任意类型的对象.是Python存储数据类型的最高级(maybe). 特点:1. 字典的存储方式和其他类型数据略有不同,是通过键(key)和值(v ...
- [前端] VUE基础 (6) (v-router插件、获取原生DOM)
一.v-router插件 1.v-router插件介绍 v-router是vue的一个核心插件,vue+vue-router主要用来做SPA(单页面应用)的. 什么是SPA:就是在一个页面中,有多个页 ...
- c语言中fflush的运用为什么没有效果呢,测试平台linux
/************************************************************************* > File Name: clearing. ...
- mysql琐碎操作杂记
1.索引相关 查看表索引 show index from `user` 查看sql的执行计划 explain select * from where user 2.存储过程相关 查看存储过程 show ...
- jmeter 配置csv 登陆网站 报错
0 环境 系统环境:win7 1 正文 1 问题 创建csv 格式为utf-8后 jmeter csv配置好后 post请求登陆报错 2 解决 查看了一下报告 post请求里用户名乱码了 仔细一看网站 ...
- 26)PHP,数据库表格中项的数据类型
类型展示: tinyint-----1个字节 smallint----2个字节 mediumint--3个字节 int------4个字节 bigint---8个字节 字符串类型 最基本最重要的2个: ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...