Synchronized加锁、锁升级和java对象内存结构
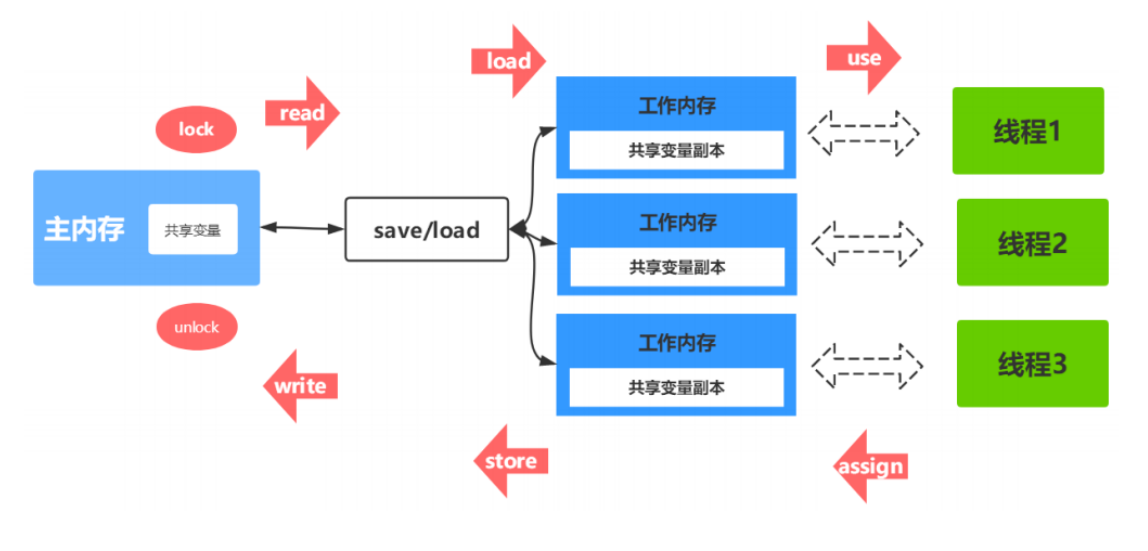
首先了解一下JMM中定义的内存操作:
一个线程操作数据时候都是从主内存(堆内存)读取到自己工作内存(线程私有的数据区域)中再进行操作。对于硬件内存来说,并没有工作内存和主内存的区分,这都是java内存模型划分出来的,它只是一种抽象的概念,是一组规则,并不是实际存在的。Java内存模型中定义了八种同步操作:
1.lock(锁定):作用于主内存的变量,把一个变量标记为一条线程独占状态
2.unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
3.read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
4.load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中
5.use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
6.assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量
7.store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
8.write(写入):作用于工作内存的变量,它把store操作从工作内存中的一个变量的值传送到主内存的变量中
如果要把一个变量从主内存中复制到工作内存中,就需要按顺序地执行read和load操作, 如果把变量从工作内存中同步到主内存中,就需要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
同步规则:
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存 中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load 或者assign)的变量。即就是对一个变量实施use和store操作之前,必须先自行assign和load 操作。
- 一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一线程重复 执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和 unlock必须成对出现。
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变 量之前需要重新执行load或assign操作初始化变量的值。
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去 unlock一个被其他线程锁定的变量。
对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)
Synchronized:
synchronized是jvm内置的同步锁,它是隐式锁,不需要我们自己手动释放锁。
每一个java对象中都有一个内部对象Monitor。synchronized就是通过内部对象Monitor(监视器锁)实现,基于进入与退出Monitor对象实现方法与代码块同步,监视器锁的实现依赖底层操作系统的Mutex lock(互斥锁)实现,它是一个重量级锁性能较低(jdk1.6之后进行了优化)。
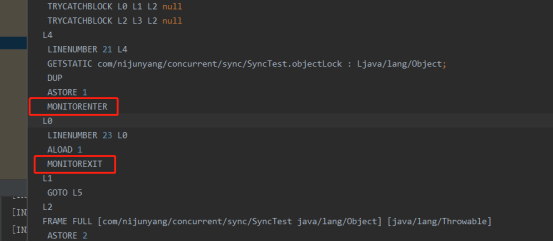
当我们在代码中使用了synchronized之后,可以在字节码文件看到MONITORENTER和MONITOREXIT。Idea中安装了ByteCode Viewer插件就可以查看字节码,选中编译完的class文件
java虚拟机中ObjectMonitor的定义:(虚拟机C++代码片段)

加锁的过程:
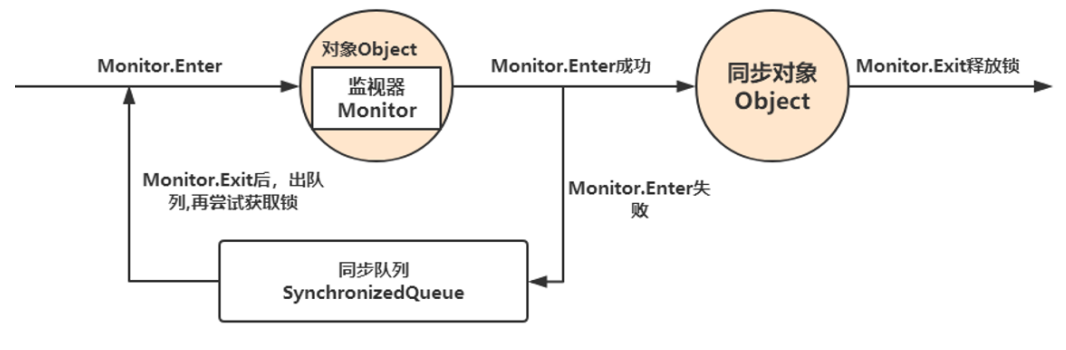
Monitor.Enter和Monitor.Exit就是作用在JMM中定义的内存操作中的lock和unlock上面。然后从上面的同步规则中可以知道一个变量在同一时刻只允许一条线程对其进行lock操作,lock操作的时候会清空工作内存,重新去主内存load最新的数据。Unlock操作则会执行store和write操作将工作内存中的数据写回主内存。这也就是为什么我们用了Synchronized关键字之后就能够实现线程安全。
Java对象内存结构:
对象在内存中存储的结构由三部分组成:对象头,主要是一些标记信息MarkWord,比如hashcode,锁状态这些;实例数据,就是真实的数据;对齐填充,要求对象大小8字节的整数倍,如果不是就填充补齐。
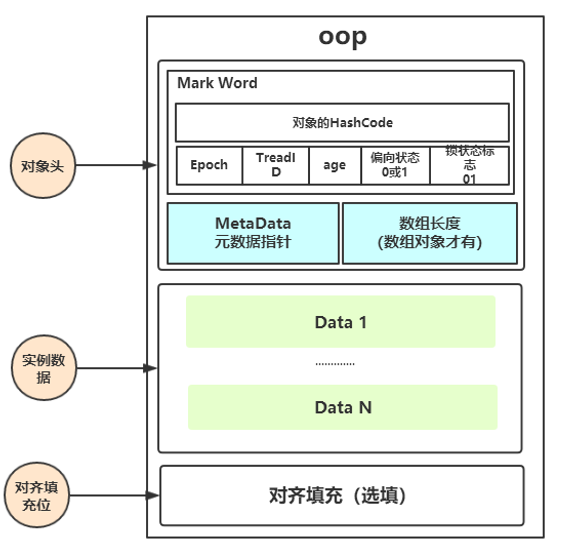
MarkWord:锁状态标记就在这里面,以32位jvm为例,64位也是这些东西,只是占的大小不一样

无锁状态:前25位记录的是hashcode,后四位是对象分代年龄,然后是否是偏向锁标记
偏向锁状态:前23位是偏向的线程ID
轻量级锁:前30位指向线程栈中锁记录的指针
重量级锁:前30位指向重量级锁Monitor的指针
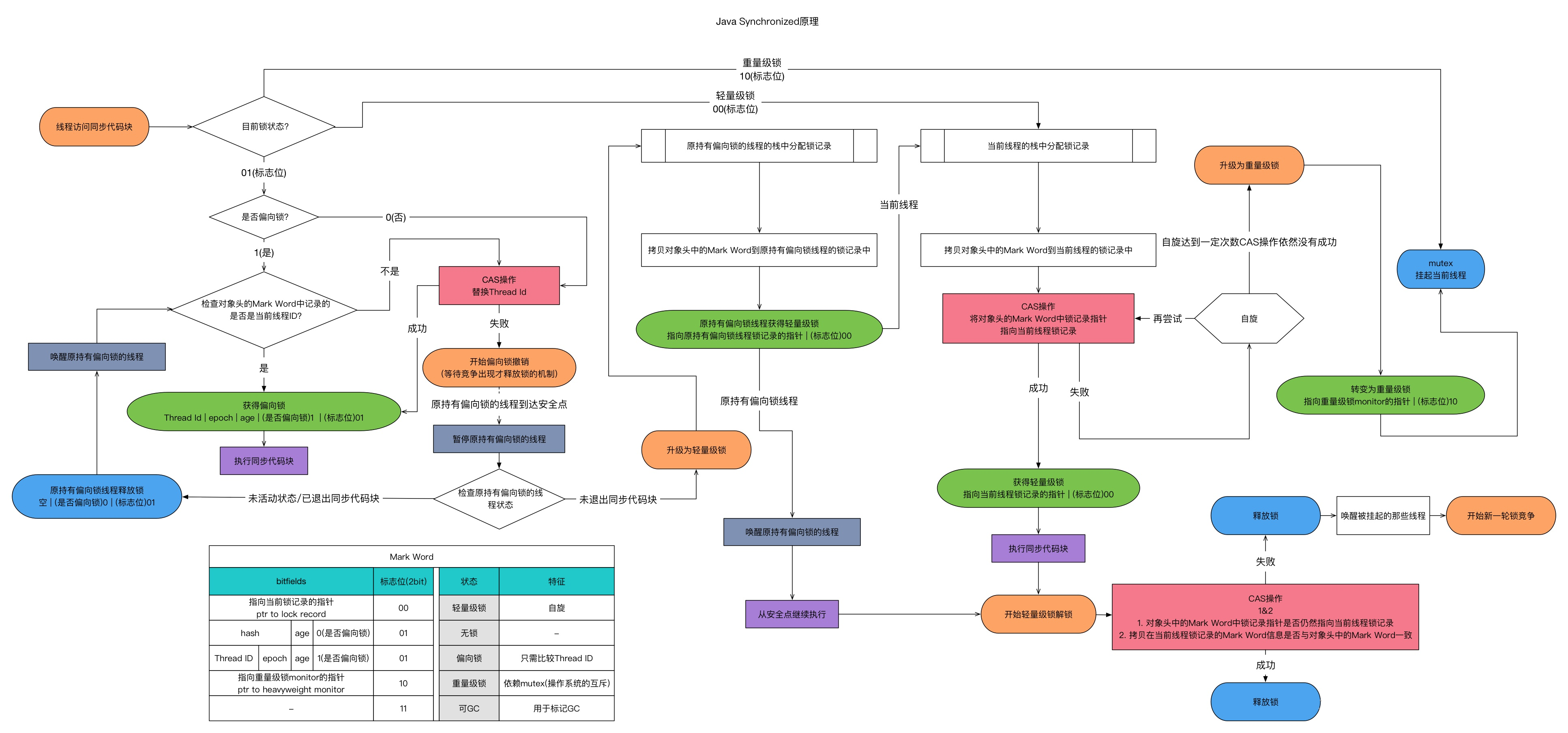
JVM内置锁优化升级
JDK1.6版本之后对synchronized的实现进行了各种优化,自旋锁、偏向锁和轻量级锁
并默认开启偏向锁
开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
关闭偏向锁:-XX:-UseBiasedLocking
偏向锁
偏向锁是Java 6之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需 再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从 而也就提供程序的性能。所以,对于没有锁竞争的场合,偏向锁有很好的优化效 果,毕竟极有可能连续多次是同一个线程申请相同的锁。但是对于锁竞争比较激 烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相 同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
轻量级锁
倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种 称为轻量级锁的优化手段(1.6之后加入的),此时Mark Word 的结构也变为轻量 级锁的结构。轻量级锁能够提升程序性能的依据是“对绝大部分的锁,在整个同 步周期内都不存在竞争”,注意这是经验数据。需要了解的是,轻量级锁所适应 的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。这个时候也就是上面的Monitor.Enter和Monitor.Exit。锁的升级过程是不可逆的。
自旋锁
虚拟机为了避免线程真实地在操作系统层面挂起,会进行一项称为自旋锁的优化手段。它是一个过渡,每一次升级之前先进行自旋,比如通过一定的自旋之后发现还是偏向锁锁的场景那么就不进行锁的升级。这是基于在大多数情况下,线程持有锁的时间都不会太长,如果直接挂起操作系统层面的线程可能会得不偿失,毕竟操作系统实 现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对 比较长的时间,时间成本相对较高,因此自旋锁会假设在不久将来,当前的线程 可以获得锁,因此虚拟机会让当前想要获取锁的线程做几个空循环(这也是称为 自旋的原因),一般不会太久,可能是50个循环或100循环,在经过若干次循环后,如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作 系统层面挂起,这就是自旋锁的优化方式,这种方式确实也是可以提升效率的。
整个过程如下图
Synchronized加锁、锁升级和java对象内存结构的更多相关文章
- JAVA 对象内存结构
JAVA对象内存结构 HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header).实例数据(Instance Data)和对齐填充(Padding). 对象头 markWo ...
- [Java基础] Java对象内存结构
转载地址:http://www.importnew.com/1305.html 原文于2008年11月13日 发表, 2008年12月18日更新:这里还有一篇关于Java的Sizeof运算符的实用库的 ...
- Ehcache计算Java对象内存大小
在EHCache中,可以设置maxBytesLocalHeap.maxBytesLocalOffHeap.maxBytesLocalDisk值,以控制Cache占用的内存.磁盘的大小(注:这里Off ...
- 图文详解Java对象内存布局
作为一名Java程序员,我们在日常工作中使用这款面向对象的编程语言时,做的最频繁的操作大概就是去创建一个个的对象了.对象的创建方式虽然有很多,可以通过new.反射.clone.反序列化等不同方式来创建 ...
- Java对象内存模型
2 Java对象内存模型 在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header). 实例数据(Instance Data)和对齐填充(Padding). 在 JVM ...
- Java对象内存布局
本文转载自Java对象内存布局 导语 首先直接抛出问题 Unsafe.getInt(obj, fieldOffset)中的fieldOffset是什么, 类似还有compareAndSwapX(obj ...
- JVM基础系列第6讲:Java 虚拟机内存结构
看到这里,我相信大家对于一个 Java 源文件是如何变成字节码文件,以及字节码文件的含义已经非常清楚了.那么接下来就是让 Java 虚拟机运行字节码文件,从而得出我们最终想要的结果了.在这个过程中,J ...
- 从一道面试题深入了解java虚拟机内存结构
记得刚大学毕业时,为了应付面试,疯狂的在网上刷JAVA的面试题,很多都靠死记硬背.其中有道面试题,给我的印象非常之深刻,有个大厂的面试官,顺着这道题目,一直往下问,问到java虚拟机的知识,最后把我给 ...
- synchronized与锁升级
1 为什么需要synchronized? 当一个共享资源有可能被多个线程同时访问并修改的时候,需要用锁来保证数据的正确性.请看下图: 线程A和线程B分别往同一个银行账户里面添加货币,A线程从内存中读取 ...
随机推荐
- [算法总结]DFS(深度优先搜索)
目录 一.关于DFS 1. 什么是DFS 2. DFS的搜索方式 二.DFS的具体实现 三.剪枝 1. 顺序性剪枝 2. 重复性剪枝 3. 可行性剪枝 4. 最优性剪枝 5. 记忆化剪枝 四.练习 一 ...
- 选择IT行业的自我心得,希望能帮助到各位!(五)
相信很多小伙伴,在看完之前的一二三四,也是我一路走来,走走停停,走走停停,有快乐,也有伤悲,毕竟这就是人生嘛,人生不起起伏伏怎么才能体验刺激的快感,也让我从一个小男孩净化成清高浮躁的青少年,在从而让我 ...
- three.js中让模型自动居中的代码如下:
//load_Model为需要居中的3D模型 //原理是通过boundingBoxHelper 来计算模型的大小范围 var hex = 0xff0000; var MD_Length,MD_Widt ...
- Python中赋值、浅拷贝和深拷贝的区别
前言文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http: ...
- Teradata 数据库
笔者大学所学计算机专业,读书时接触过Oracle.mysql和SQL SERVER,一度坐井观天觉得数据库应该也就这些了,但自笔者毕业进入数据仓库这个行业,接触的第一个商业数据库即是Teradata, ...
- Codeforces 1340B Nastya and Scoreboard(dp,贪心)
题目链接OvO 题目大意 给你\(n\)串数字,\(1\)代表该位置是亮的,\(0\)代表是灭的.你必须修改\(k\)个数字,使某些\(0\)变为\(1\).注意,只能把原来的\(0\)改成\(1 ...
- 2020最新的web前端体系和路线图,想学web前端又不知道从哪开始的快来瞧一瞧呀
web前端其实是相对于服务器语言是简单的,并且对于初学者是非常友好的,因为在前期学习能够看到很好的效果.但是他的路线 也就是学习体系不成熟,所以导致很多初学者不知道怎么学?下面我就讲讲web前端的体系 ...
- php二维数组的排序
/** * @desc arraySort php二维数组排序 按照指定的key 对数组进行排序 * @param array $arr 将要排序的数组 * @param string $key ...
- udp包最大数据长度是多少
因为udp包头有2个byte用于记录包体长度. 2个byte可表示最大值为: 2^16-1=64K-1=65535 udp包头占8字节, ip包头占20字节, 65535-28 = 65507 ...
- Qt5 escape spaces in path
There are two possible ways. You can either use escaped quotes (inserting the string between quotes) ...