Kubernetes 集群日志管理【转】
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理。这是一个 Elasticsearch、Fluentd 和 Kibana 的组合。Elasticsearch 是一个搜索引擎,负责存储日志并提供查询接口;Fluentd 负责从 Kubernetes 搜集日志并发送给 Elasticsearch;Kibana 提供了一个 Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志。

部署
Elasticsearch 附加组件本身会作为 Kubernetes 的应用在集群里运行,其 YAML 配置文件可从 https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch 获取。
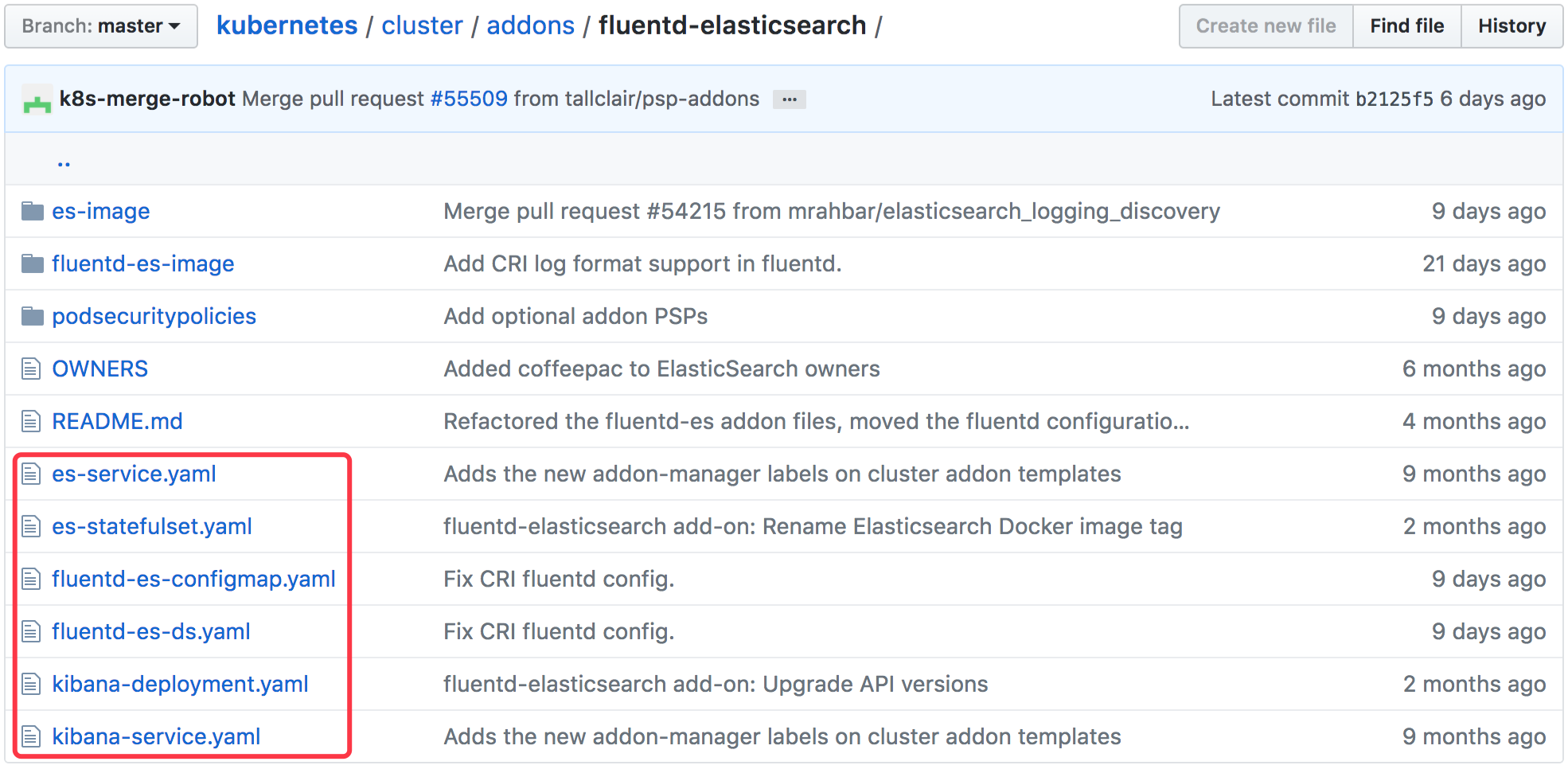
可将这些 YAML 文件下载到本地目录,比如 addons ,通过 kubectl apply -f addons/ 部署。

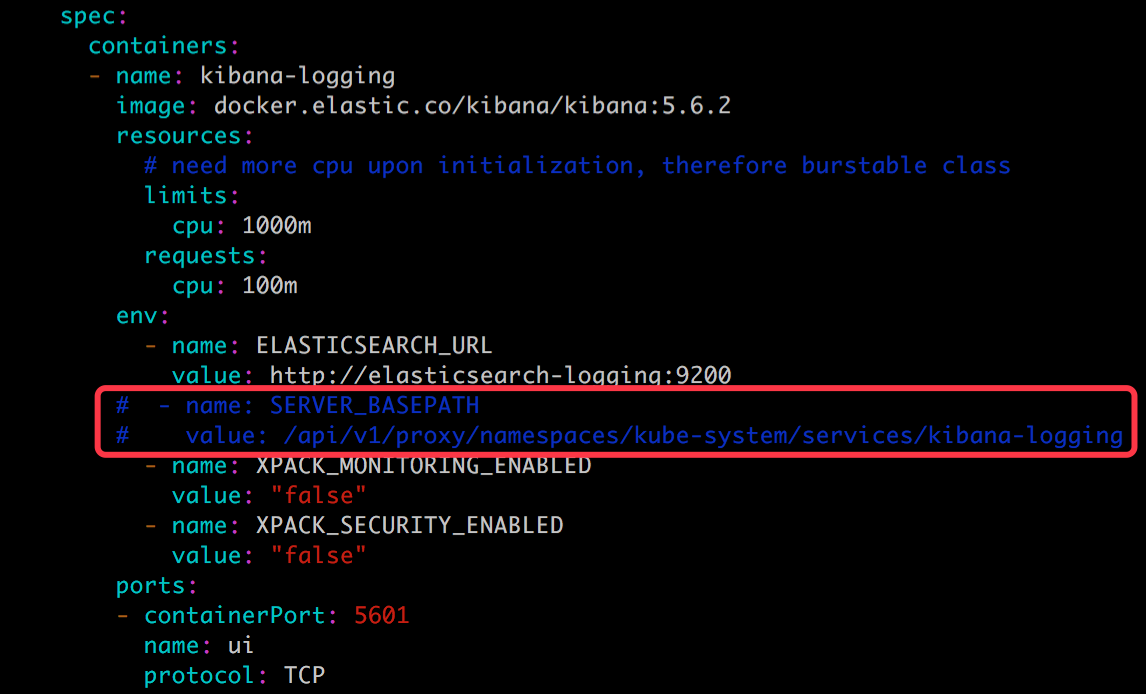
这里有一点需要注意:后面我们会通过 NodePort 访问 Kibana,需要注释掉 kibana-deployment.yaml 中的环境变量 SERVER_BASEPATH,否则无法访问。
所有的资源都部署在 kube-system Namespace 里。
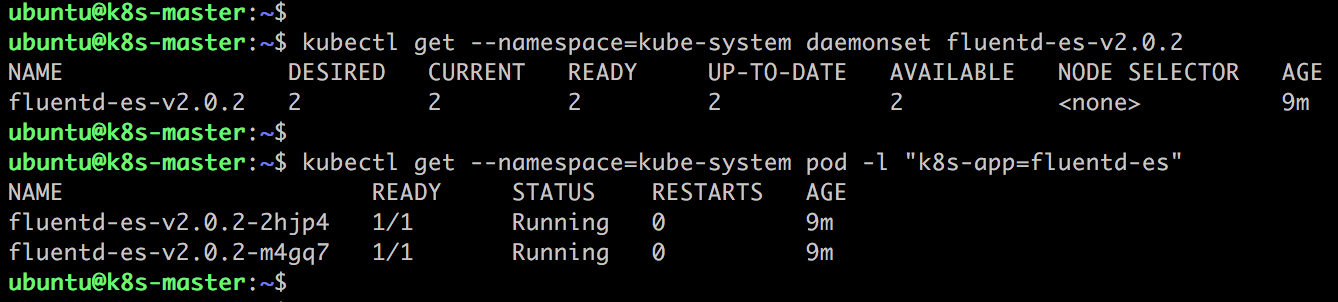
DaemonSet fluentd-es 从每个节点收集日志,然后发送给 Elasticsearch。

Elasticsearch 以 StatefulSet 资源运行,并通过 Service elasticsearch-logging 对外提供接口。这里已经将 Service 的类型通过 kubectl edit 修改为 NodePort。
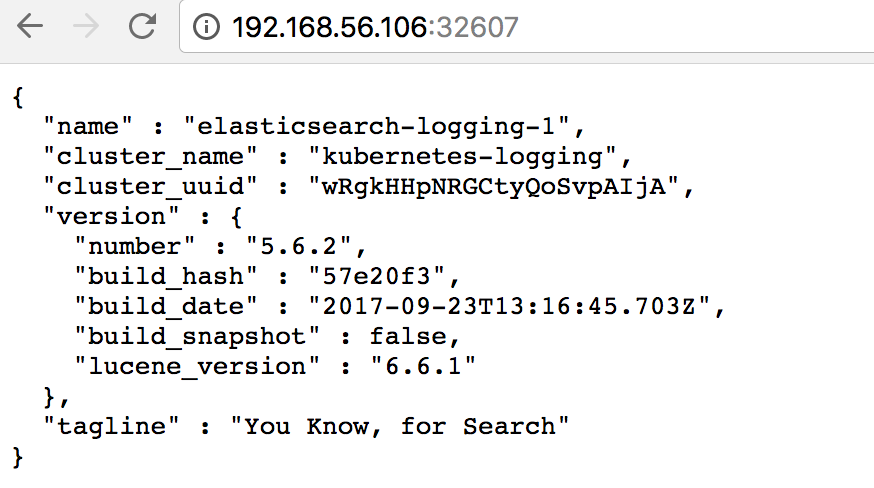
可通过 http://192.168.56.106:32607/ 验证 Elasticsearch 已正常工作。
Kibana 以 Deployment 资源运行,用户可通过 Service kibana-logging 访问其 Web GUI。这里已经将 Service 的类型修改为 NodePort。
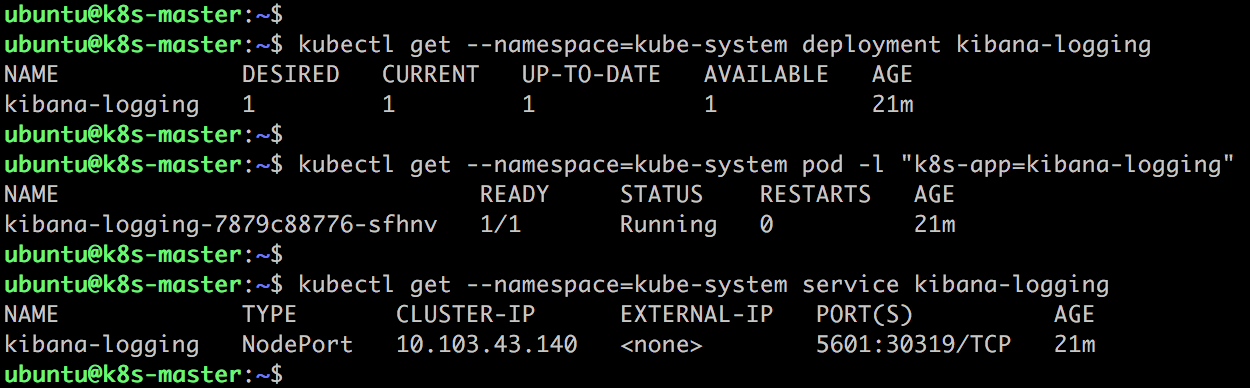
通过 http://192.168.56.106:30319/ 访问 Kibana。
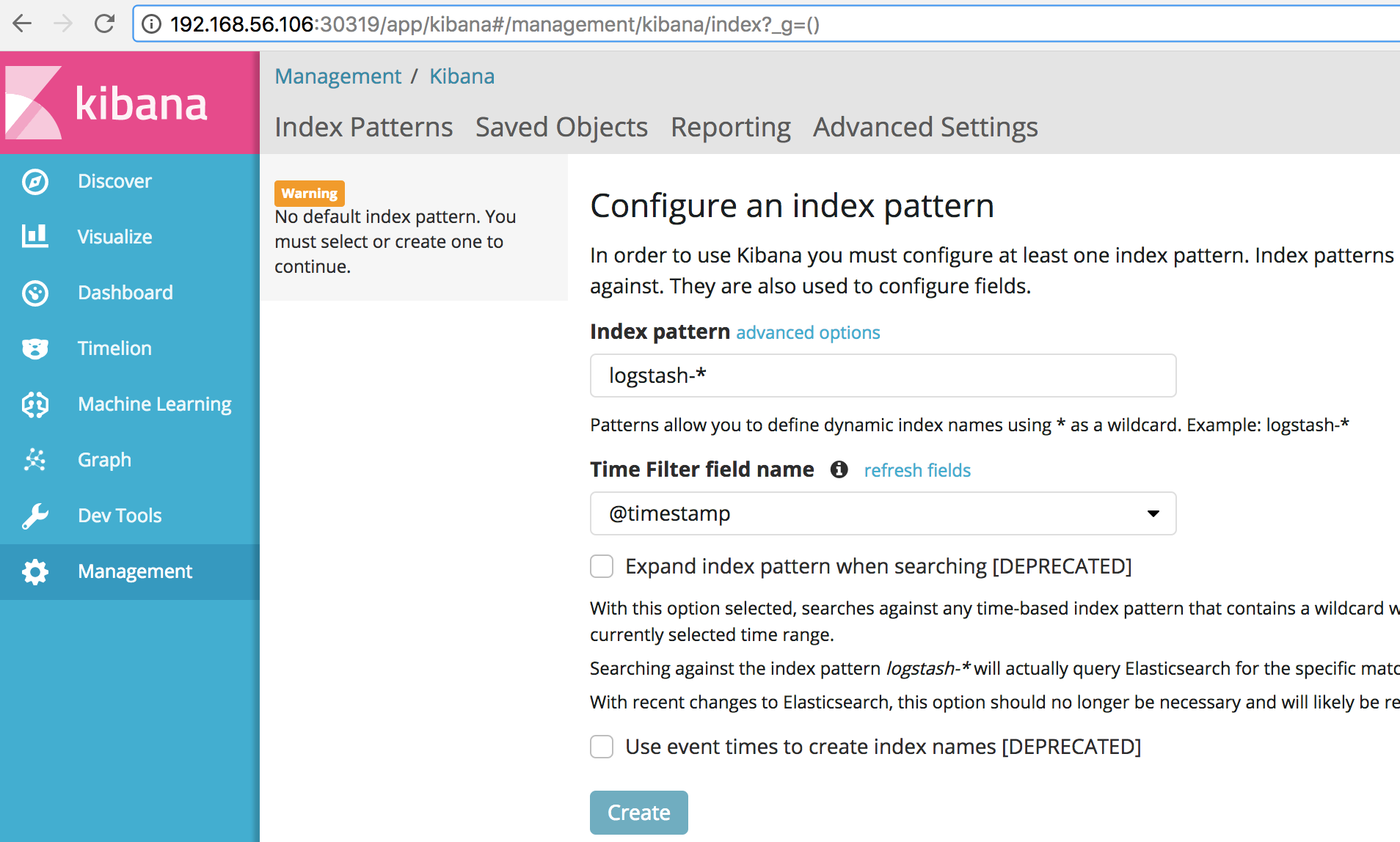
Kibana 会显示 Index Pattern 创建页面。直接点击 Create,Kibana 会自动完成后续配置。
这时,点击左上角的 Discover 就可以查看和检索 Kubernetes 日志了。
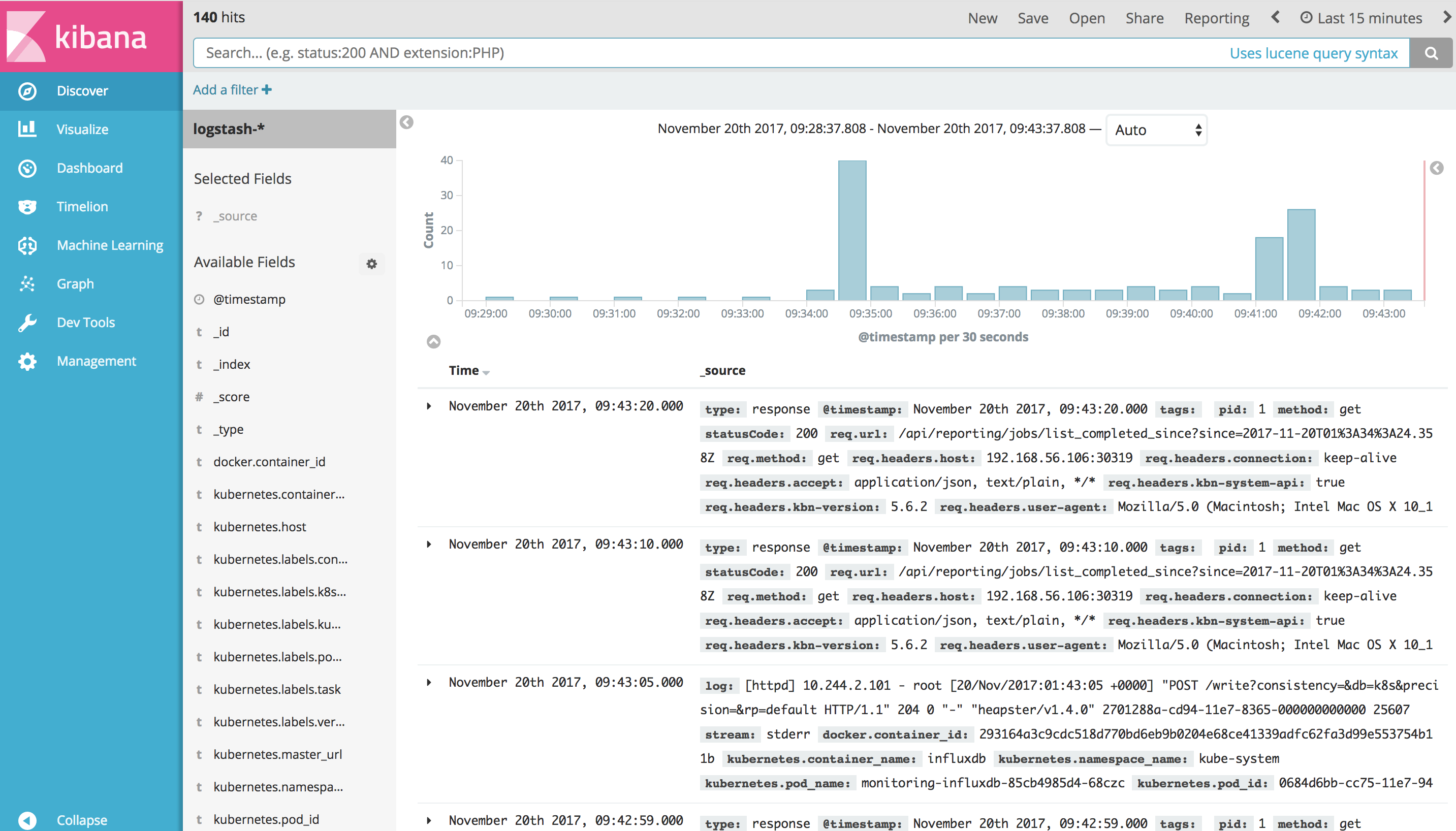
Kubernetes 日志管理系统已经就绪,用户可以根据需要创建自己的 Dashboard,具体方法可参考 Kibana 官方文档。
小结
Elasticsearch 附加组件本身会作为 Kubernetes 的应用在集群里运行,以实现集群的日志管理。它是一个 Elasticsearch、Fluentd 和 Kibana 的组合。
Elasticsearch 是一个搜索引擎,负责存储日志并提供查询接口。
Fluentd 负责从 Kubernetes 搜集日志并发送给 Elasticsearch。
Kibana 提供了一个 Web GUI,用户可以浏览和搜索存储在 Elasticsearch 中的日志。
Kubernetes 集群日志管理【转】的更多相关文章
- Kubernetes 集群日志管理 - 每天5分钟玩转 Docker 容器技术(180)
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elasticsearch ...
- Kubernetes 集群日志管理
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elasticsearch ...
- Kubernetes 集群日志管理 Elasticsearch + fluentd(二十)
目录 一.安装部署 Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elas ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- 阿里云上万个 Kubernetes 集群大规模管理实践
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 汤志敏,阿里 ...
- ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一.ELK搜索引擎原理介绍 在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果.但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果. 搜索引擎的组 ...
- 使用 Elastic 技术栈构建 K8S 全栈监控 -3: 使用 Filebeat 采集 Kubernetes 集群日志
文章转载自:https://www.qikqiak.com/post/k8s-monitor-use-elastic-stack-3/ 操作步骤 filebeat连接es使用上一步创建的secret: ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 解决项目迁移至Kubernetes集群中的代理问题
解决项目迁移至Kubernetes集群中的代理问题 随着Kubernetes技术的日益成熟,越来越多的企业选择用Kubernetes集群来管理项目.新项目还好,可以选择合适的集群规模从零开始构建项目: ...
随机推荐
- 同一台服务器lnmpa环境下配置ip或域名访问不同站点
1.配置域名访问 (1)添加虚拟主机 (2)nginx配置 cd /usr/local/nginx/conf/vhost vim zkadmin.zouke.com.conf (3)apache配置 ...
- java集合体系结构总结
好,首先我们根据这张集合体系图来慢慢分析.大到顶层接口,小到具体实现类. 首先,我想说为什么要用集合?简单的说:数组长度固定,且是同种数据类型.不能满足需求.所以我们引入集合(容器)来存储任意数据类型 ...
- 基于Goolgle最新NavigationDrawer实现全屏水平平移
常见实现App 上面侧边栏菜单之前使用SlidingMenu,现在发现Goolgle原生NavigationDrawer也挺好用.但是细心的开发者们发现NavigationDrawer没有类似Slid ...
- idna与utf-8编码漏洞
来自Black hat 2019 原理什么是IDN?国际化域名(Internationalized Domain Name,IDN)又名特殊字符域名,是指部分或完全使用特殊文字或字母组成的互联网域名, ...
- Python中.npz文件的读取
有时候从网上下载的数据集扩展名(后缀名)是npz,我们需要对数据进行加载(读取):例如:识别猫狗图片的二分类,下的数据集分别为cat.npz和dog.npz import numpy as npcat ...
- Struts笔记二:栈值的内存区域及标签和拦截器
值栈和ognl表达式 1.只要是一个MVC框架,必须解决数据的存和取的问题 2.struts2利用值栈来存数据,所以值栈是一个存储数据的内存结构 1. ValueStack是一个接口,在struts ...
- Caffe2 玩玩回归(Toy Regression)[5]
前言 这一节将讲述如何使用Caffe2的特征进行简单的线性回归学习.主要分为以下几步: - 生成随机数据作为模型的输入 - 用这些数据创建网络 - 自动训练模型 - 查看梯度递减的结果和学习过程中网络 ...
- Maven 项目中使用 logback
添加依赖 <dependency> <groupId>net.logstash.logback</groupId> <artifactId>logsta ...
- 牛客挑战赛36 G Nim游戏(分治FWT)
https://ac.nowcoder.com/acm/contest/3782/G 题解: 分治FWT裸题. 每个都相当于\((1+b[i]x^{a[i]})\),求这玩意的异或卷积. 先把a[i] ...
- spring boot ApplicationRunner使用
spring boot ApplicationRunner使用 它的使用比较简单,实现ApplicationRunner的run方法 package com.hikvision.pbg.jc.conf ...