pandas中数据框的一些常见用法
1、创建数据框或读取外部csv文件
- 创建数据框数据
""" 设计数据 """
import pandas as pd
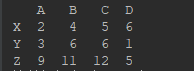
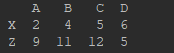
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
print(df)
- 读取外部csv文件(关于“header=None”设定的问题参照 pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结)
""" 读取数据 """
import pandas as pd
df = pd.read_csv("data/data.csv", header=None)
2、重置索引
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 重置索引,从0开始计数 """
# 获取行数
nrow = df.shape[0]
# 获取列数
ncol = df.shape[1]
print("该数据框有%d行, %d列" %(nrow,ncol))
# 重置行索引
df.index = range(nrow)
# df.index = [1,2,3] # 也可以使用自定义手动方式
# 重置列索引
df.columns = range(ncol)
print(df)

3、行列读取
- 读取列
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 读取数据框 """
# 读取列
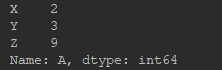
a = df.ix[:, 0] # 读取单列——第0列
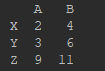
b = df.ix[:, 0:2] # 读取连续列——第0,1,2列
c = df.ix[:, [0,2]] # 读取指定某些列——第0,2列
print(a)
print(b)
print(c)

- 读取行(同理)
# 读取行
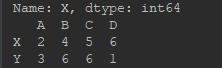
d = df.ix[0, :] # 读取单行——第0行
e = df.ix[0:2, :] # 读取连续行——第0,1,2行
f = df.ix[[0,2], :] # 读取指定某些行——第0,2行
print(d)
print(e)
print(f)

4、数据合并
""" 数据合并 """
import pandas as pd
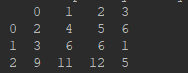
data1 = {"0": [2,3,9], "1": [4,6,11], "2": [5,6,12], "3": [6,1,5]}
index = [0,1,2]
df1 = pd.DataFrame(data=data1, index=index)
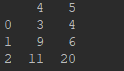
data2 = {"4": [3,9,11], "5": [4,6,20]}
df2 = pd.DataFrame(data=data2, index=index)
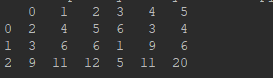
# 合并数据框(合并前需要确保数据是DataFrame格式), 其中,如果axis=1,ignore_index将改变的是列上的索引(属性名)
df = pd.concat([pd.DataFrame(df1), pd.DataFrame(df2)], axis=1) # axis=1 表示横向合并(左右);axis=0 表示纵向合并(上下)
print(df)
df1:
df2:
df:
pandas中数据框的一些常见用法的更多相关文章
- pandas中数据框DataFrame获取每一列最大值或最小值
1.python中数据框求每列的最大值和最小值 df.min() df.max()
- Scala中_(下划线)的常见用法
Scala中_(下划线)的常见用法 地址:https://www.jianshu.com/p/0497583ec538
- Pandas中数据的处理
有两种丢失数据 ——None ——np.nan(NaN) None是python自带的,其类型为python object.因此,None不能参与到任何计算中 Object类型的运算比int类型的运算 ...
- pandas中数据聚合【重点】
数据聚合 数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值. 数据分类处理: 分组:先把数据分为几组 用函数处理:为不同组的数据应用不同的函数以转换数据 合并:把不同组得到的结果合 ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句SQL基本用法
本文展示三种在Hibernate中使用SQL语句进行数据查询基本用法 1.基本查询 2.条件查询 3.分页查询 package com.Gary.dao; import java.util.List; ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句Criteria基本用法
Criteria进行数据查询与HQL和SQL的区别是Criteria完全是面向对象的方式在进行数据查询,将不再看到有sql语句的痕迹,使用Criteria 查询数据包括以下步骤: 1. 通过sessi ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句HQL基本用法
HQL(Hibernate Query Language) 是面向对象的查询语言, 它和 SQL 查询语言有些相似. 在 Hibernate 提供的各种检索方式中, HQL 是使用最广的一种检索方式. ...
- Python3中IO文件操作的常见用法
首先创建一个文件操作对象: f = open(file, mode, encoding) file指定文件的路径,可以是绝对路径,也可以是相对路径 文件的常见mode: mode = “r” # ...
- JAVA中数组Arrays类的常见用法
import java.util.Arrays; int[] array1={7,8,3,2,12,6,5,4}; 1. //克隆clone int[] array2=array1.clone() ...
随机推荐
- thinkphp5网站中集成使用支付宝手机支付接口
今天以thinkphp5中使用支付宝的手机支付接口为例. 一.创建基本页面pay/alipay_wap_submit.php(开始创建订单) <!DOCTYPE html> <htm ...
- a 标签 name 属性 页面定位 (一)
a(§b) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
- 编写高质量代码改善C#程序的157个建议——建议101:使用扩展方法,向现有类型“添加”方法
建议101:使用扩展方法,向现有类型“添加”方法 考虑如何让一个sealed类型具备新的行为.以往我们会创建一个包装器类,然后为其添加方法,而这看上去一点儿也不优雅.我们也许会考虑修改设计,直接修改s ...
- pig配置
下载Apache Pig 首先,从以下网站下载最新版本的Apache Pig:https://pig.apache.org/ 步骤1 打开Apache Pig网站的主页.在News部分下,点击链接re ...
- XJOI3602 邓哲也的矩阵(优先队列优化DP)
题目描述: 有一个 n×m的矩阵,现在准备对矩阵进行k次操作,每次操作可以二选一 1: 选择一行,给这一行的每一个数减去p,这种操作会得到的快乐值等于操作之前这一行的和 2: 选择一列,给这一列的每一 ...
- Centos配置多个tomcat服务器,并用nginx实现负载均衡
centos配置tomcat请参见上一篇博文 :http://www.cnblogs.com/nanyangzp/p/4897655.html 一:多tomcat利用不同端口开启服务器 多个tomca ...
- linux命令の ./configure --prefix
源码的安装一般由3个步骤组成:配置(configure).编译(make).安装(make install). Configure是一个可执行脚本,它有很多选项,在待安装的源码路径下使用命令./con ...
- [Erlang01] 使用catch与try catch避免嵌套nest_case
catch 如此好用,为什么官方还是推荐用try catch? 1. catch 的用法非常简单: catch case do_check(Test) of {ok,Result} -> do_ ...
- EF修改model自动更新数据库
最近用MVC+EF学习时遇到修改model后而数据库没更新报错,就在网上找关于数据迁移自动更新数据库的,折腾了大半天终于弄了出来 第一步:在程序包管理器控制台里: Enable-Migrations ...
- python学习之路 四 :文件处理
本节重点 掌握文件的读.写.修改方法 掌握文件的处理模式的区别 一.文件读取 1.读取全部内容 # 一次性读取文件 f = open("test.txt",'r',en ...