pandas中数据框的一些常见用法
1、创建数据框或读取外部csv文件
- 创建数据框数据
""" 设计数据 """
import pandas as pd
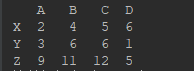
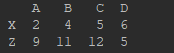
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
print(df)
- 读取外部csv文件(关于“header=None”设定的问题参照 pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结)
""" 读取数据 """
import pandas as pd
df = pd.read_csv("data/data.csv", header=None)
2、重置索引
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 重置索引,从0开始计数 """
# 获取行数
nrow = df.shape[0]
# 获取列数
ncol = df.shape[1]
print("该数据框有%d行, %d列" %(nrow,ncol))
# 重置行索引
df.index = range(nrow)
# df.index = [1,2,3] # 也可以使用自定义手动方式
# 重置列索引
df.columns = range(ncol)
print(df)

3、行列读取
- 读取列
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 读取数据框 """
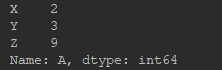
# 读取列
a = df.ix[:, 0] # 读取单列——第0列
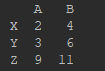
b = df.ix[:, 0:2] # 读取连续列——第0,1,2列
c = df.ix[:, [0,2]] # 读取指定某些列——第0,2列
print(a)
print(b)
print(c)

- 读取行(同理)
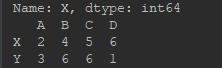
# 读取行
d = df.ix[0, :] # 读取单行——第0行
e = df.ix[0:2, :] # 读取连续行——第0,1,2行
f = df.ix[[0,2], :] # 读取指定某些行——第0,2行
print(d)
print(e)
print(f)

4、数据合并
""" 数据合并 """
import pandas as pd
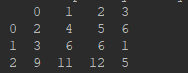
data1 = {"0": [2,3,9], "1": [4,6,11], "2": [5,6,12], "3": [6,1,5]}
index = [0,1,2]
df1 = pd.DataFrame(data=data1, index=index)
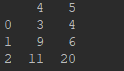
data2 = {"4": [3,9,11], "5": [4,6,20]}
df2 = pd.DataFrame(data=data2, index=index)
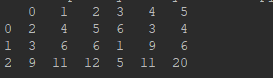
# 合并数据框(合并前需要确保数据是DataFrame格式), 其中,如果axis=1,ignore_index将改变的是列上的索引(属性名)
df = pd.concat([pd.DataFrame(df1), pd.DataFrame(df2)], axis=1) # axis=1 表示横向合并(左右);axis=0 表示纵向合并(上下)
print(df)
df1:
df2:
df:
pandas中数据框的一些常见用法的更多相关文章
- pandas中数据框DataFrame获取每一列最大值或最小值
1.python中数据框求每列的最大值和最小值 df.min() df.max()
- Scala中_(下划线)的常见用法
Scala中_(下划线)的常见用法 地址:https://www.jianshu.com/p/0497583ec538
- Pandas中数据的处理
有两种丢失数据 ——None ——np.nan(NaN) None是python自带的,其类型为python object.因此,None不能参与到任何计算中 Object类型的运算比int类型的运算 ...
- pandas中数据聚合【重点】
数据聚合 数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值. 数据分类处理: 分组:先把数据分为几组 用函数处理:为不同组的数据应用不同的函数以转换数据 合并:把不同组得到的结果合 ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句SQL基本用法
本文展示三种在Hibernate中使用SQL语句进行数据查询基本用法 1.基本查询 2.条件查询 3.分页查询 package com.Gary.dao; import java.util.List; ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句Criteria基本用法
Criteria进行数据查询与HQL和SQL的区别是Criteria完全是面向对象的方式在进行数据查询,将不再看到有sql语句的痕迹,使用Criteria 查询数据包括以下步骤: 1. 通过sessi ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句HQL基本用法
HQL(Hibernate Query Language) 是面向对象的查询语言, 它和 SQL 查询语言有些相似. 在 Hibernate 提供的各种检索方式中, HQL 是使用最广的一种检索方式. ...
- Python3中IO文件操作的常见用法
首先创建一个文件操作对象: f = open(file, mode, encoding) file指定文件的路径,可以是绝对路径,也可以是相对路径 文件的常见mode: mode = “r” # ...
- JAVA中数组Arrays类的常见用法
import java.util.Arrays; int[] array1={7,8,3,2,12,6,5,4}; 1. //克隆clone int[] array2=array1.clone() ...
随机推荐
- intellJ IDE 15 生成 serialVersionUID
这个Inspections的位置不好找,建议搜索Serialization issues 然后勾选两项 serialzable class without "serialVersionUID ...
- ssh的配置[待写]
开机自启:/etc/rc.local /etc/init.d/ssh start 将 /etc/ssh/sshd_confg中PermitRootLogin no 改为yes,重新启动ssh服务.
- struts2 和 js 标签取值
struts标签是在服务器上替换成html代码的,js是在用户浏览器执行的,这个顺序如果没搞清楚你是搞不好web开发的
- SPOJ - AMR11J ——(BFS)
The wizards and witches of Hogwarts School of Witchcraft found Prof. Binn's History of Magic lesson ...
- [linux] 查看SATA速度和具体设备
查看SATA速度和具体设备 SATA 速度确认 方法一 dmesg |grep SATA 输出 [ 2.977661] ahci 0000:00:17.0: AHCI 0001.0301 32 slo ...
- 什么是C#?什么是.NET Framework?
1.什么是C#: 解1:C#就是一门开发语言,是由C及C++演变而来的,有朋友戏称之为"C四个+",这里的"#"号,不读"井",而读做&qu ...
- 在Linux安装ASP.Net Core的运行时(Runtime)
在部署的时候,如果您不想在您的Linux服务器上安装.Net Core SDK,您可以只安装Runtime,接下来我们看看该如何安装运行时Runtime. 下载运行时文件 下载页面:https://w ...
- C# 获取唯一数字
/// <summary> /// 如果你想生成一个数字序列而不是字符串,你将会获得一个19位长的序列.下面的方法会把GUID转换为Int64的数字序列. /// </summary ...
- Django Query
Making Qeries 一旦创建了数据模型,Django就会自动为您提供一个数据库抽象API,允许您创建.检索.更新和删除对象.本文档解释了如何使用这个API. The models 一个clas ...
- [转载] C++异常处理机制
原地址:http://blog.csdn.net/daheiantian/article/details/6530318 一.什么是异常处理 一句话:异常处理就是处理程序中的错误. 二.为什么需要异常 ...