统计学习方法笔记 -- KNN
K近邻法(K-nearest neighbor,k-NN),这里只讨论基于knn的分类问题,1968年由Cover和Hart提出,属于判别模型
K近邻法不具有显式的学习过程,算法比较简单,每次分类都是根据训练集中k个最近邻,通过多数表决的方式进行预测。所以模型需要保留所有训练集数据,而象感知机这样的模型只需要保存训练后的参数即可,训练集不需要保留
K近邻算法

K近邻法三要素
和其他统计学习方法不同的,K近邻法的三要素是,k值的选择,距离度量和分类决策规则
距离度量
首先如何定义“近”?需要通过距离度量,比如最常见的欧氏距离
下面这个比较清楚,欧氏距离只是p=2的case,也称为L2距离

K值的选择
选取比较小的k值(较复杂的模型),近似误差(approximation error)会减小,而估计误差(estimation error)会增大,因为影响分类的都是比较近的样本,但一旦出现噪点,预测就会出错
选取比较大的k值(较简单的模型),相反,减小噪点的影响,但是较远或不相似的样本也会对结果有影响,极限情况下k=N,考虑所有样本,极简模型
k一般会选取比较小的值,通常采用交叉验证来选取最优的k值
分类决策规则
往往采用多数表决,但是也可以采用其他的策略
kd树
对于knn有个根本问题是,当训练集比较大时,线性的扫描效率是很低的,需要更为高效的方法来找到k近邻,这里介绍的kd数是二叉树,其实就是以二分的方式查找,将复杂度由n变小为logn。
那么关键问题就是,如何能够二分的索引训练点和给定任意一个点如何从kd树中找到最近邻?
构造kd树
基本思路,循环的以k维空间中的每一维对训练数据进行划分
划分标准,往往是使用训练集在该维上的中位数进行划分,具体看下下面的例子
使用中位数可以保证树是平衡的,但不一定效率最优


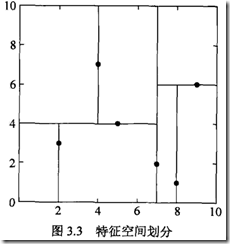
例子,
首先用x维划分,中位数为7,(7,2)放在节点上
(2,3) (4,7) (5,4)划分到左子树,而(8,1) (9,6)划分到右子树
然后用y维进行划分,
对于左边区域,y维的中位数为4,(4,7)放在节点上,(2,3) (5,4)分布划分到两个子树
对于右边区域,y维的中位数为6。。。
然后再用x维进行划分。。。 
搜索kd树
对于搜索k邻近,就是k次搜索最邻近,所以直接看下最邻近的搜索算法
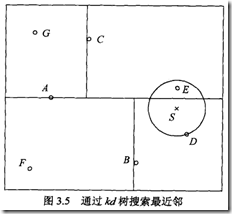
例子学习,
首先找到包含S的那个叶节点,这里是D,那么以SD为半径画个圆,有可能包含更近节点的区域一定会和这个圆相交,相交不一定有,但不相交一定没有
所以下面做的只是往根节点回溯,
首先B,B本身不是更近的节点,而B的另一个子节点F的区域和圆不相交
继续回溯到A,A不是,但A的另一个子节点C的区域是和圆相交的
所以需要checkA的C节点,C本身不是,G的区域不相交,但E的区域相交
并且E到S的距离更近,故E是最邻近节点

统计学习方法笔记 -- KNN的更多相关文章
- 统计学习方法:KNN
作者:桂. 时间:2017-04-19 21:20:09 链接:http://www.cnblogs.com/xingshansi/p/6736385.html 声明:欢迎被转载,不过记得注明出处哦 ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 统计学习方法笔记(KNN)
k近邻法(k-nearest neighbor,k-NN) 输入:实例的特征向量,对应于特征空间的点:输出:实例的类别,可以取多类. 分类时,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预 ...
- 李航-统计学习方法-笔记-3:KNN
KNN算法 基本模型:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例.这k个实例的多数属于某个类,就把输入实例分为这个类. KNN没有显式的学习过程. KNN使用的模型 ...
- 统计学习方法 三 kNN
KNN (一)KNN概念: K近邻算法是一种回归和分类算法,这主要讨论其分类概念: K近邻模型三要素: 1,距离: 2,K值的选择: K值选择过小:模型过复杂,近似误差减小,估计误差上升,出现过拟合 ...
- 统计学习方法笔记 Logistic regression
logistic distribution 设X是连续随机变量,X服从逻辑斯谛分布是指X具有下列分布函数和密度函数: 式中,μ为位置参数,γ>0为形状参数. 密度函数是脉冲函数 分布函数是一条S ...
- 统计学习方法笔记 -- Boosting方法
AdaBoost算法 基本思想是,对于一个复杂的问题,单独用一个分类算法判断比较困难,那么我们就用一组分类器来进行综合判断,得到结果,"三个臭皮匠顶一个诸葛亮" 专业的说法, 强可 ...
- 《统计学习方法》极简笔记P5:决策树公式推导
<统计学习方法>极简笔记P2:感知机数学推导 <统计学习方法>极简笔记P3:k-NN数学推导 <统计学习方法>极简笔记P4:朴素贝叶斯公式推导
- 《统计学习方法》笔记九 EM算法及其推广
本系列笔记内容参考来源为李航<统计学习方法> EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验概率估计.迭代由 (1)E步:求期望 (2)M步:求极大 组成,称 ...
随机推荐
- matlab保存画框图像去白边
在matlab图像处理中,为了标识出图像的目标区域来,需要利用plot函数或者rectangle函数,这样标识目标后,就保存图像. 一般saves保存的图像存在白边,可以采用imwrite对图像进行保 ...
- 认识rem
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 封装locaostorage
const ls = localStorage export default { setItem(name, value) { ls.setItem(name, JSON.stringify(valu ...
- JAVA-Word转PDF各种版本实现方式
当下做一个项目,就是各种操作office,客户的需求总是各种不按常理,来需求就得搞啊.对JAVA操作office这方面真是头大,弟弟是真滴不懂不会啊.无奈只好试啊试的.网上一大堆好使的,一大堆不好使的 ...
- fromdata上传数据
使用formdata上传数据 $(function() { fileStack=[];//总的上传图片栈 //上传事件 $("#uploadBtn").on("click ...
- hdu6153 扩展kmp求一个字符串的后缀在另一个字符串出现的次数。
/** 题目:hdu6153 链接:http://acm.hdu.edu.cn/showproblem.php?pid=6153 题意:给定两个串,求其中一个串t的每个后缀在另一个串s中出现的次数乘以 ...
- [转]基于Storm的实时数据处理方案
1 文档说明 该文档描述的是以storm为主体的实时处理架构,该架构包括了数据收集部分,实时处理部分,及数据落地部分. 关于不同部分的技术选型与业务需求及个人对相关技术的熟悉度有关,会一一进行分析. ...
- 使用jQuery模拟Google的自动提示效果
注意: 1.本功能使用SqlServler2000中的示例数据库Northwind,请打SP3或SP4补丁:2.请下载jQuery组件,河西FTP中有下载:3.本功能实现类似Google自动提示的效果 ...
- UML概述
UML (Unified Modeling Language)统一建模语言,是描述.构造和文档化系统制品的可视化语言,是一种图形表示法. UML用途:UML是一种工具,主要用在我们对软件用面向对象的方 ...
- Oracle的归档日志
归档模式的特点和要求 在归档模式下,当LGWR后台进程的写操作从一个重做日志组切换到另一个重做日志组后,归档写后台进程(ARCH/ARCRn)就会将原来的重做日志的信息复制到归档日志文件中. 可以把归 ...