ELK之elasticsearch5.6的安装和head插件的安装
这里选择的elasticsearch为5.6的新版本,根据官方文档有几种暗装方式:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
这里选择rpm包安装https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
1、wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.1.rpm
2、查看有哪些配置文件
[root@node1 ~]# cd /etc/elasticsearch/
[root@node1 elasticsearch]# ll
总用量 20
-rw-rw----. 1 root elasticsearch 3024 9月 19 14:00 elasticsearch.yml
-rw-rw----. 1 root elasticsearch 3123 9月 18 10:38 jvm.options
-rw-rw----. 1 root elasticsearch 4456 9月 7 11:12 log4j2.properties
drwxr-x---. 2 root elasticsearch 4096 9月 7 11:12 scripts
elasticsearch常用配置在elasticsearch.yml文件中,关于jvm的一些配置在jvm.options文件中,日志的配置在log4j2.properties文件中
[root@node1 elasticsearch]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elastic
node.name: node1
network.host: 0.0.0.0
http.port: 9200
简单配置之后然后启动服务:/etc/init.d/elasticsearch start
默认日志文件为/var/log/elasticsearch/目录下,启动有报错都可以根据报错解决
这里将一些遇到的报错及解决方法列一些出来:
[root@node1 elasticsearch]# cat /etc/security/limits.d/90-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning. * soft nproc 2048
root soft nproc unlimited
[root@node1 elasticsearch]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elastic
node.name: node1
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
重新启动elasticsearch服务,查看日志是否报错,如没有报错,浏览器进行访问是否有效:
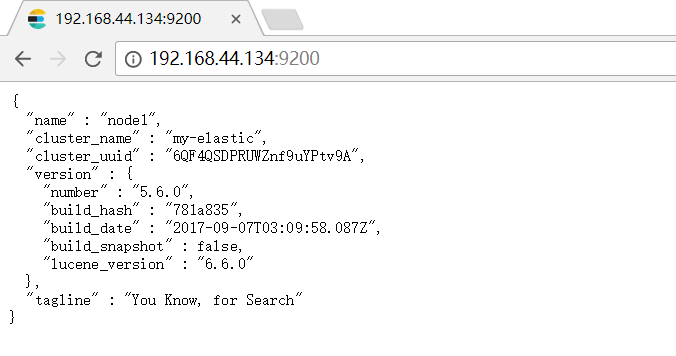
现在为elasticsearch安装上插件head,利用github找到head插件:

https://github.com/mobz/elasticsearch-head,根据文中说明:
There are multiple ways of running elasticsearch-head.
Running with built in server
git clone git://github.com/mobz/elasticsearch-head.gitcd elasticsearch-headnpm installnpm run start
This will start a local webserver running on port 9100 serving elasticsearch-head
Running as a plugin of Elasticsearch (deprecated)
- for Elasticsearch 5.x: site plugins are not supported. Run as a standalone server
elasticsearch5.x以上需要安装head插件需要作为一个单独的服务,步骤如上,于是开始安装:
如果没有npm命令需要首先安装上:
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
默认监听在0.0.0.0,不需要修改监听地址
这里有两种启动方式:
1、npm run start(仓库拉取下来的elasticsearch-head目录下执行)
2、[root@node1 elasticsearch-head]# ./node_modules/grunt/bin/grunt server
启动后都是如下效果:
[root@node1 elasticsearch-head]# ./node_modules/grunt/bin/grunt server
Loading "watch.js" tasks...ERROR
>> Error: Cannot find module 'http-parser-js' Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
查看日志:
[2017-09-19T13:50:36,288][INFO ][o.e.p.PluginsService ] [node1] no plugins loaded
[2017-09-19T13:50:38,401][INFO ][o.e.d.DiscoveryModule ] [node1] using discovery type [zen]
[2017-09-19T13:50:39,079][INFO ][o.e.n.Node ] [node1] initialized
[2017-09-19T13:50:39,079][INFO ][o.e.n.Node ] [node1] starting ...
[2017-09-19T13:50:39,239][INFO ][o.e.t.TransportService ] [node1] publish_address {192.168.44.134:9300}, bound_addresses {[::]:9300}
9100端口已经监听了,访问浏览器http://192.168.44.134:9100却依然连接不到集群,然后谷歌到需要进行设置:
check http.cors.enabled and http.cors.allow-origin are set in config/elasticsearch.yml in order to enable cors.
Reference : https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-http.html
然后配置elastic,具体配置如下:
[root@node1 elasticsearch]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elastic
node.name: node1
bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 0.0.0.0
http.port: 9200
重启服务之后,浏览器访问
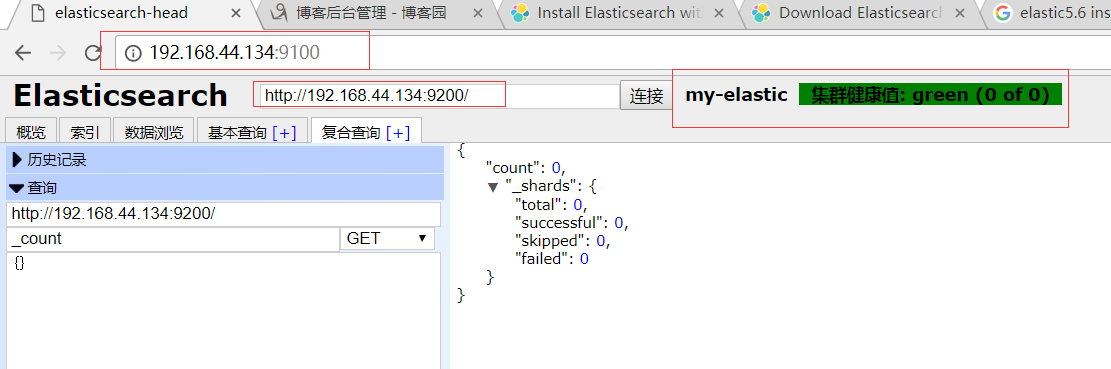
至此elasticsearch5.6版本安装head插件成功!!!
插件head的一些配置,如果node1不是监听在0.0.0.0而是ip:

还有一个配置文件:(我这里没有hostname这个选项)

ELK之elasticsearch5.6的安装和head插件的安装的更多相关文章
- elasticsearch5.0以上版本及head插件的安装
本文转载至:https://www.cnblogs.com/hts-technology/p/8477258.html(针对5.0以上版本) 对于es5.0以下的版本可以参考:https://www. ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- 转:ElasticSearch的安装和相关插件的安装
原文来自于:http://blog.csdn.net/whxaing2011/article/details/18237733 本文主要介绍如下内容: 1.ElasticSearch ...
- ElasticSearch 5.2.2 安装及 head 插件的安装
ElasticSearch 是一个基于 Lucene 的高度可扩展的开源全文搜索和分析引擎.它能够做到可以快速.实时地存储.搜索和分析大量数据.它通常作为底层引擎/技术,为具有复杂搜索功能和要求的应用 ...
- Ubuntu16.04下安装googlechrome flash 插件和安装网易云音乐
一.ubuntu 16.04 下安装完后发现 flash无法播放没有安装flash插件因为 Adobe Flash 不再支持 linux Google 便开发了PepperFlashPlayer来替代 ...
- eclipse安装反编译插件
1. 进入http://jadclipse.sourceforge.net/wiki/index.php/Main_Page#Download 下载 net.sf.jadclipse ...
- 解决WordPress无法上传媒体文件以及无法下载和安装主题与插件的问题
前言: 我的个人博客网站荒原之梦在安装成功WordPress之后本来是可以上传媒体文件,安装主题和插件的,但是后来不知道怎么回事就出了问题:不能上传媒体文件也不能安装主题和插件了.出现这个问题后我尝试 ...
- 04 sublime text 3在线安装package control插件,之后安装主题插件和ConvertToUTF8 插件
前提:需要@@科学@@上网 在线安装包通常都需要@@科学@@上网 安装package control插件 在线安装package control插件 按ctrl+shift+p 输入install,选 ...
- elasticsearch5.0集群+kibana5.0+head插件插件的安装
elasticsearch5.0集群+kibana5.0+head插件插件的安装 es集群的规划: 两台16核64G内存的服务器: yunva_etl_es1 ip:1.1.1.1 u04es01. ...
随机推荐
- 160314、MVC设计模式
MVC的由来 精彩内容 MVC模式最早由Trygve Reenskaug在1978年提出 ,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件设 ...
- SaltStack数据系统-Grains
上一篇:SaltStack配置管理 granis:谷粒 pillar:柱子 grains是salt的一个组件,存放minion启动时候收集的信息(状态信息) 查看 salt '*' grains.it ...
- HDU 5701 中位数计数 百度之星初赛
中位数计数 Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total Sub ...
- Program terminated with signal SIGABRT, Aborted.
linux C++ 程序 启动后就奔溃 #0 0x00007f01ee4c21f7 in raise () from /lib64/libc.so.6 #1 0x00007f01ee4c38e8 in ...
- 拼团商品列表页 分析 js代码行位置对执行的影响和window.onload的原理 setTimeout传参
w TypeError : Cannot set property 'innerHTML' of nullTypeError : Cannot set property 'value' of null ...
- Python中的Numpy
引用Numpy import numpy as np 生成随机数据 # 200支股票 stock_cnt = 200 # 504个交易日 view_days = 504 # 生成服从正态分布:均值期望 ...
- BitTrex行情查看与技术指标系统
上个月的时候,向TradingView申请K线图行情插件,填了各种资料,被问了N多问题,结果却仍是不愿意提供插件给我们. 于是,我们自己开发了一个BitTre行情查看与技术指标系统, 这套系统被国内多 ...
- centos7虚拟机克隆
第一步:克隆 打开VMware,确认已经完成安装配置的centos7虚拟机在关闭状态. 右键点击虚拟机,选择“管理”-“克隆” 原始虚拟机名称为“master”,IP地址为“192.168.80.10 ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- 类的super
我们经常在类的继承当中使用super(), 来调用父类中的方法.例如下面: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 class A: def func(self): ...