jieba库的使用和好玩的词云
1、jieba库基本介绍
(1)、jieba库概述
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
(2)、jieba分词的原理
Jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
2、jieba库使用说明
(1)、jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
(2)、jieba库常用函数
| 函数 | 描述 |
| jieba.lcut(s) | 精确模式,返回一个列表类型的分词结果 >>>jieba.lcut("中国是一个伟大的国家") ['中国', '是', '一个', '伟大', '的', '国家'] |
| jieba.lcut(s, cut_all=True) |
全模式,返回一个列表类型的分词结果,存在冗余 >>>jieba.lcut("中国是一个伟大的国家",cut_all=True) ['中国', '国是', '一个', '伟大', '的', '国家'] |
| 函数 | 描述 |
| jieba.lcut_for_sear ch(s) |
搜索引擎模式,返回一个列表类型的分词结果,存在冗余 >>>jieba.lcut_for_search(“中华人民共和国是伟大的") ['中华', '华人', '人民', '共和', '共和国', '中华人民共 和国', '是', '伟大', '的'] |
| jieba.add_word(w) | 向分词词典增加新词w >>>jieba.add_word("蟒蛇语言") |
3.应用:对文本中出现的文字频率进行统计
首先我们需要找到一篇文章,将其弄成txt格式的文件,且需将txt文件与编写程序的文件放置在同一文件夹中。我实践用的是一篇我在大一写的专业概论作业。
代码如下:
import jieba
txt = open("专业概论作业.txt", "r").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(5):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
4.结果展示:
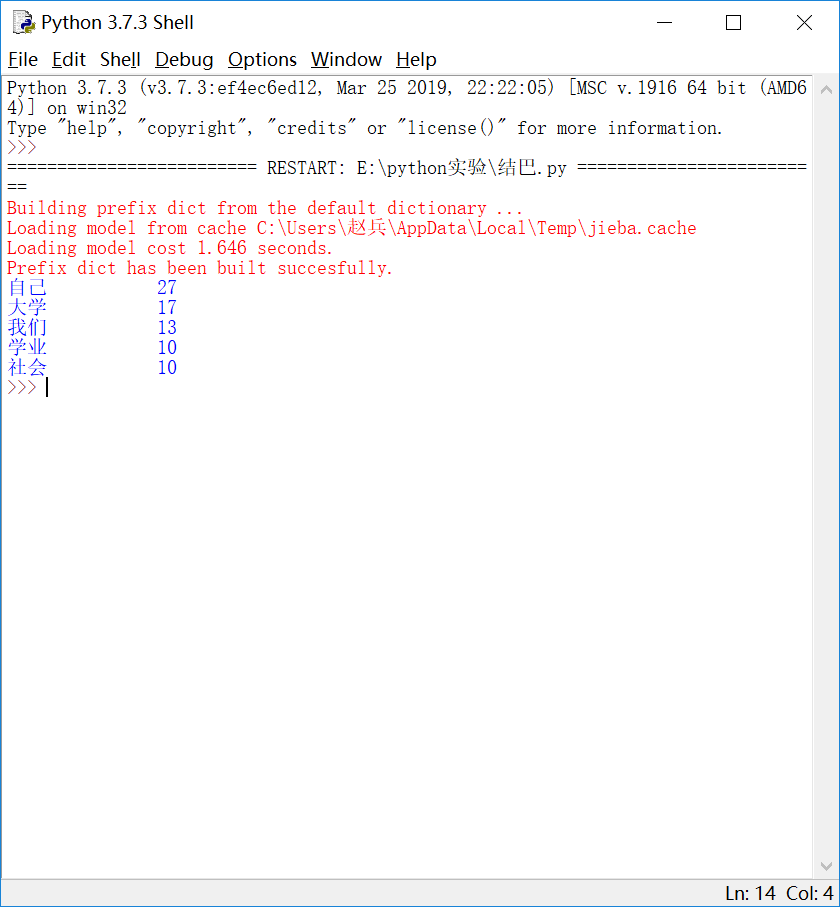
5.词云代码:
from wordcloud import WordCloud
import matplotlib.pyplot as plt #绘制图像的模块
import jieba #jieba分词 path_txt='专业概论作业.txt'
f = open(path_txt,'r').read() # 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(f)) wordcloud = WordCloud(
#设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1920,height=1080).generate(cut_text) plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
6.结果展示:
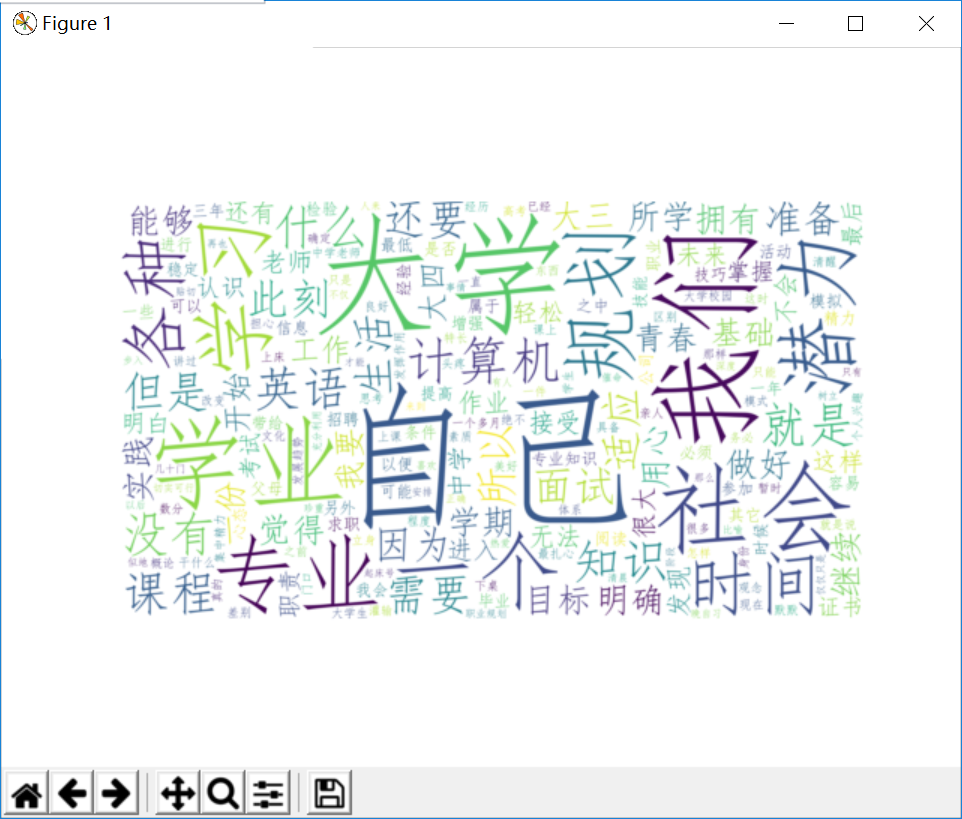
jieba库的使用和好玩的词云的更多相关文章
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- jirba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- Jieba库使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- 从CentOS安装完成到生成词云python学习日记
欢迎访问我的个人博客:原文链接 前言 人生苦短,我用python.学习python怎么能不搞一下词云呢是不是(ง •̀_•́)ง 于是便有了这篇边实践边记录的笔记. 环境:VMware 12pro + ...
- NLP实现文本分词+在线词云实现工具
实现文本分词+在线词云实现工具 词云是NLP中比较简单而且效果较好的一种表达方式,说到可视化,R语言当仍不让,可见R语言︱文本挖掘——词云wordcloud2包 当然用代码写词云还是比较费劲的,网上也 ...
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
随机推荐
- RDD弹性分布式数据集的基本操作
RDD的中文解释是弹性分布式数据集.构造的数据集的时候用的是List(链表)或者Array数组类型/* 使用makeRDD创建RDD */ /* List */ val rdd01 = sc.make ...
- window安装pycharm Django
pycharm 安装Pycharm 直接在官网下载就可以,这里说一下如何破解注册码的问题: 修改电脑中hosts文件(地址: C:\Windows\System32\drivers\etc ),改变 ...
- logback日志丢失的情况之一
在游戏服务器上线之后,会记录很多统计日志,这些日志是第三方需要的数据,通过linux 的 rsync方式同步给第三方.日志规则 每十分钟会创建一个日志文件.然后后台有一个rsync进程,每隔十分钟向第 ...
- 关于babel官网的学习
提起babel,前端er大概都不陌生.但是为什么要有babel呢?解决了什么问题?怎么使用babel呢?注意点在哪?以下就从这几个方面总结一下我关于babel学习的结果吧. 为什么要有babel呢? ...
- windows 共享文件
- shell编辑器vi的常用命令
一:翻页 ctrl+u向上翻半页 ctrl+f向上翻一页 ctrl+d 向下翻半页 ctrl+b 向下翻一页 二:移动光标指令 0: 光标移至当前行首 $: 光标移至当前行尾 三:常用插入.删除指令 ...
- vmware中centos6.7系统图形化安装Oracle-无法打开RUNINSTALLER
如果解压正确 unzip linux……1/2 unzip linux……2/2 给了权限 chown -R Oracle:oinstall /home/database/ 在oracle用户下,运行 ...
- 流程控制语句(if switch)
一.if语句 if(条件){ 代码块1 } else if (条件2) { 代码块2 } else if (条件3) { 代码块3 else { 代码块4 } 当代码执行到这里的时候,先判断条件1的值 ...
- SQL*Plus命令
简介set命令 一般使用SQL PLUS导出数据时一般使用以下参数就可以了. set echo off; -- 不显示脚本中的每个sql命令(缺省为on)set feedback off; -- 禁止 ...
- 各种CSS样式设置细线边框
基础知识回顾 : cellspacing:单元格与单元格之间的边距:cellpadding:单元格内的内容与单元格边沿的边距 简单实用的样式,设置所有的单元格为细线效果 <style type= ...