Django rest framework(8)---- 视图和渲染器
django rest framework 之视图
序列化器 PagerSerialiser
from rest_framework import serializers
from api import models class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model = models.Role
fields = "__all__"
APIview
ApiAPIView 实现分页的写法如下
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
from api import models class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor'
page_size = 2
ordering = 'id'
page_size_query_param = None
max_page_size = None class Pager1View(APIView): def get(self,request,*args,**kwargs): # 获取所有数据
roles = models.Role.objects.all() # 创建分页对象
# pg = CursorPagination()
pg = MyCursorPagination() # 在数据库中获取分页的数据
pager_roles = pg.paginate_queryset(queryset=roles,request=request,view=self) # 对数据进行序列化
ser = PagerSerialiser(instance=pager_roles, many=True) # return Response(ser.data)
return pg.get_paginated_response(ser.data)
添加路由
urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/pager1/$', views.Pager1View.as_view()),
]
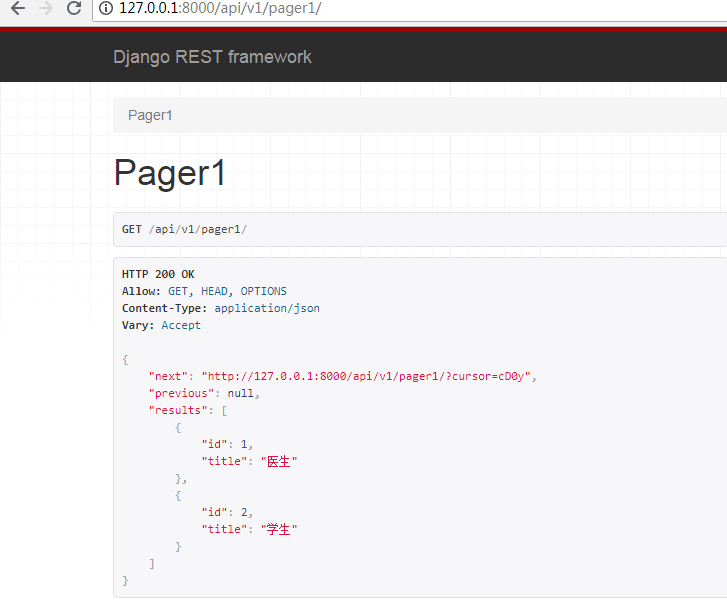
测试结果
http://127.0.0.1:8000/api/v1/pager1/
GenericAPIView 我们一般不用,没有比APIView 简单多少
GenericAPIView 是继承APIView的,所以对APIView 进行了一些功能的封装,同样实现上述功能,代码如下
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.generics import GenericAPIView class View1View(GenericAPIView):
queryset = models.Role.objects.all() # 指定查询的数据
serializer_class = PagerSerialiser # 序列化
pagination_class = PageNumberPagination # 分页
def get(self,request,*args,**kwargs):
# 获取数据
roles = self.get_queryset() # models.Role.objects.all() # [1, 1000,] [1,10]
pager_roles = self.paginate_queryset(roles) # 获取分页后的结果 # 序列化
ser = self.get_serializer(instance=pager_roles,many=True) return Response(ser.data)
源码如下所示
class GenericAPIView(views.APIView):
"""
Base class for all other generic views.
"""
# You'll need to either set these attributes,
# or override `get_queryset()`/`get_serializer_class()`.
# If you are overriding a view method, it is important that you call
# `get_queryset()` instead of accessing the `queryset` property directly,
# as `queryset` will get evaluated only once, and those results are cached
# for all subsequent requests.
queryset = None
serializer_class = None # If you want to use object lookups other than pk, set 'lookup_field'.
# For more complex lookup requirements override `get_object()`.
lookup_field = 'pk'
lookup_url_kwarg = None # The filter backend classes to use for queryset filtering
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS # The style to use for queryset pagination.
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS def get_queryset(self):
"""
Get the list of items for this view.
This must be an iterable, and may be a queryset.
Defaults to using `self.queryset`. This method should always be used rather than accessing `self.queryset`
directly, as `self.queryset` gets evaluated only once, and those results
are cached for all subsequent requests. You may want to override this if you need to provide different
querysets depending on the incoming request. (Eg. return a list of items that is specific to the user)
"""
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
) queryset = self.queryset
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
return queryset def get_object(self):
"""
Returns the object the view is displaying. You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
queryset = self.filter_queryset(self.get_queryset()) # Perform the lookup filtering.
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
) filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
obj = get_object_or_404(queryset, **filter_kwargs) # May raise a permission denied
self.check_object_permissions(self.request, obj) return obj def get_serializer(self, *args, **kwargs):
"""
Return the serializer instance that should be used for validating and
deserializing input, and for serializing output.
"""
serializer_class = self.get_serializer_class()
kwargs['context'] = self.get_serializer_context()
return serializer_class(*args, **kwargs) def get_serializer_class(self):
"""
Return the class to use for the serializer.
Defaults to using `self.serializer_class`. You may want to override this if you need to provide different
serializations depending on the incoming request. (Eg. admins get full serialization, others get basic serialization)
"""
assert self.serializer_class is not None, (
"'%s' should either include a `serializer_class` attribute, "
"or override the `get_serializer_class()` method."
% self.__class__.__name__
) return self.serializer_class def get_serializer_context(self):
"""
Extra context provided to the serializer class.
"""
return {
'request': self.request,
'format': self.format_kwarg,
'view': self
} def filter_queryset(self, queryset):
"""
Given a queryset, filter it with whichever filter backend is in use. You are unlikely to want to override this method, although you may need
to call it either from a list view, or from a custom `get_object`
method if you want to apply the configured filtering backend to the
default queryset.
"""
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset @property
def paginator(self):
"""
The paginator instance associated with the view, or `None`.
"""
if not hasattr(self, '_paginator'):
if self.pagination_class is None:
self._paginator = None
else:
self._paginator = self.pagination_class()
return self._paginator def paginate_queryset(self, queryset):
"""
Return a single page of results, or `None` if pagination is disabled.
"""
if self.paginator is None:
return None
return self.paginator.paginate_queryset(queryset, self.request, view=self) def get_paginated_response(self, data):
"""
Return a paginated style `Response` object for the given output data.
"""
assert self.paginator is not None
return self.paginator.get_paginated_response(data)
添加路由
urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/pager1/$', views.Pager1View.as_view()),
# url(r'^(?P<version>[v1|v2]+)/v1/$', views.View1View.as_view()), ]
测试结果如下
http://127.0.0.1:8000/api/v1/v1/

GenericViewSet
它继承的是

它在 GenericAPIView 的基础上增加了路由和视图函数的限制关系,在url中指定的方法类视图中必须对应
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.viewsets import GenericViewSet class View1View(GenericViewSet):
queryset = models.Role.objects.all()
serializer_class = PagerSerialiser
pagination_class = PageNumberPagination def list(self, request, *args, **kwargs):
# 获取数据
roles = self.get_queryset() # models.Role.objects.all() # [1, 1000,] [1,10]
pager_roles = self.paginate_queryset(roles) # 序列化
ser = self.get_serializer(instance=pager_roles, many=True) return Response(ser.data)
添加路由
urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/pager1/$', views.Pager1View.as_view()),
# url(r'^(?P<version>[v1|v2]+)/v1/$', views.View1View.as_view()),
url(r'^(?P<version>[v1|v2]+)/v1/$', views.View1View.as_view({'get': 'list'})), ]
测试结果如下
ModelViewSet
它继承的类如下,它实现的功能比较强大,只需简单的配置,就不需要我们去写增删改查和局部更新,在这里可以解决我们这样的一个问题,当我们查询所有数据的时候直接会去用list方法,查询一个通过url/1 会执行 retrieve 方法 ,省去我们的判断

继承的其中一个类的源代码如下,我们可以看到只要继承了这个方法,我们就不需要写list 查询全部数据的方法
class ListModelMixin(object):
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset()) page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data) serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
通过继承modelViewSet实现分页的功能如下
from api.utils.serializsers.pager import PagerSerialiser
from rest_framework.viewsets import GenericViewSet,ModelViewSet class View1View(ModelViewSet):
queryset = models.Role.objects.all()
serializer_class = PagerSerialiser
pagination_class = PageNumberPagination
配置路由
urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/pager1/$', views.Pager1View.as_view()),
# url(r'^(?P<version>[v1|v2]+)/v1/$', views.View1View.as_view()),
# url(r'^(?P<version>[v1|v2]+)/v1/$', views.View1View.as_view({'get': 'list'})),
url(r'^(?P<version>[v1|v2]+)/v1/(?P<pk>\d+)/$', views.View1View.as_view({'get': 'retrieve','delete':'destroy','put':'update','patch':'partial_update'})), ]
测试结果如下
http://127.0.0.1:8000/api/v1/v1/1/

在上面我们可以看到,我们可以对这一条数据,进行增删改查的操作
django rest framework 之渲染器
通过渲染器可以指定数据返回的格式
注册 rest_framework
全局配置
REST_FRAMEWORK = {
"DEFAULT_RENDERER_CLASSES":[
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
]
}
局部配置
class TestView(APIView):
# renderer_classes = [JSONRenderer,BrowsableAPIRenderer]
def get(self, request, *args, **kwargs):
# 获取所有数据
roles = models.Role.objects.all() # 创建分页对象
# pg = CursorPagination()
pg = MyCursorPagination() # 在数据库中获取分页的数据
pager_roles = pg.paginate_queryset(queryset=roles, request=request, view=self) # 对数据进行序列化
ser = PagerSerialiser(instance=pager_roles, many=True) return Response(ser.data)
Django rest framework(8)---- 视图和渲染器的更多相关文章
- Django Rest framework 之 视图
RESTful 规范 django rest framework 之 认证(一) django rest framework 之 权限(二) django rest framework 之 节流(三) ...
- Django rest framework(5)----解析器
目录 Django rest framework(1)----认证 Django rest framework(2)----权限 Django rest framework(3)----节流 Djan ...
- Django-RestFrameWork之分页 视图 路由 渲染器
目录 一.分页 二.视图 三.路由 四.渲染器 一.分页 试问如果当数据量特别大的时候,你是怎么解决分页的? 方式a.记录当前访问页数的数据id 方式b.最多显示120页等 方式c.只显示上一页,下一 ...
- Django rest framework (视图类详解)
官网:https://www.django-rest-framework.org/api-guide/viewsets/ 在django rest framework 视图中一共有N个类 第一类:AP ...
- DRF Django REST framework 之 视图组件(四)
引言 在我们有几十上百的视图类,都有get,post等方法,在功能类似时,会导致大量的重复代码出现,显然还有很多可以优化的地方.这也就有了视图组件,它的功能非常强大,能很好的优化接口逻辑. 视图组件 ...
- Django基础之给视图加装饰器
1. 使用装饰器装饰FBV FBV本身就是一个函数,所以和给普通的函数加装饰器无差: def wrapper(func): def inner(*args, **kwargs): start_time ...
- Django REST framework 中的视图
1.Request REST framework传入视图的request对象不再是Django默认的Httprequest对象,而是DRF提供的扩展类的Request类的对象 常用属性 request ...
- Django Rest framework 之 解析器
RESTful 规范 django rest framework 之 认证(一) django rest framework 之 权限(二) django rest framework 之 节流(三) ...
- django rest framework renderer
渲染器 REST framework 包含许多内置的渲染器类,允许您使用各种 media type 返回响应.同时也支持自定义渲染器. 视图的渲染器集合始终被定义为类列表.当调用视图时,REST fr ...
随机推荐
- VisualStudio移动开发(C#、VB.NET)Smobiler开发平台——AlbumView相册控件的使用方式
AlbumView控件 一. 样式一 我们要实现上图中的效果,需要如下的操作: 从工具栏上的“Smobiler Components”拖动一个AlbumView控件到窗体界面上 修改 ...
- FastReport 循环打印表格数据
1,在UI上拖放一个表格控件 2.设置表格头部信息,需要显示的数据以及边框颜色 3.选中表格控件设置事件代码: private void Table1_ManualBuild(object sende ...
- python学习笔记(五)、抽象
不知不觉已经快毕业一年了,想想2018年过的可真舒适!!!社会就像一锅水,不同地方温度不同,2018年的我就身处温水中,没有一丝想要进取之心. 1 抽象 抽象在程序中可谓是神来之笔,辣么什么是抽象呢? ...
- 3. 基于优先级的Queue(PriorityBlockingQueue)
package com.gf.conn013; import java.util.Iterator; import java.util.concurrent.PriorityBlockingQueue ...
- 【JVM】问题排查
jetty的调用场景是:为了支持Servlet规范中的注解方式(使得不再需要在web.xml文件中进行Servlet的部署描述,简化开发流程),jetty在启动时会扫描class.lib包,将使用注解 ...
- Web 性能优化: 图片优化让网站大小减少 62%
摘要: 压缩各种格式的图片. 原文:Web 性能优化: 图片优化让网站大小减少 62% 作者:前端小智 Fundebug经授权转载,版权归原作者所有. 这是 Web 性能优化的第二篇,上一篇在下面看点 ...
- Ext.define(override)
Ext.define(override)作用是:定义类的补丁(扩展或重写) 有3中使用方法,见附件 Ext.define(override).zip
- Dynamics 365 POA表记录的查询
微软动态CRM专家罗勇 ,回复313或者20190311可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . PrincipalO ...
- swiper 自定义分页器的使用
网上关于swiper 自定义分页器的方法比较多,但是已经不适合使用.它的API又比较坑爹,什么都是点到为止,不说清楚.因为要做一个产品颜色切换的效果,有黑与白两种颜色,因此尝试使用Swiper的自定义 ...
- 这么小的key-val数据库居然也支持事务——与短跑名将同名的数据库Bolt
传送门: 柏链项目学院 什么是Bolt? Bolt是一个纯净的基于go语言编写的key-val数据库,该项目受到LMDB项目的启发,目标是提供一个不需要完整服务器的简单.快速.可靠的数据库. ...