Python-王者荣耀自动刷金币+爬取英雄信息+图片
前提:本文主要功能是
1.用python代刷王者荣耀金币
2.爬取英雄信息
3.爬取王者荣耀图片之类的。
(全部免费附加源代码)
思路:第一个功能是在基于去年自动刷跳一跳python代码上面弄的,思路来源陈想大佬,主要是图片识别像素,然后本机运行模拟器即可,第二、三功能是python基本爬虫功能。3个功能整合了一下。
实现效果如下:
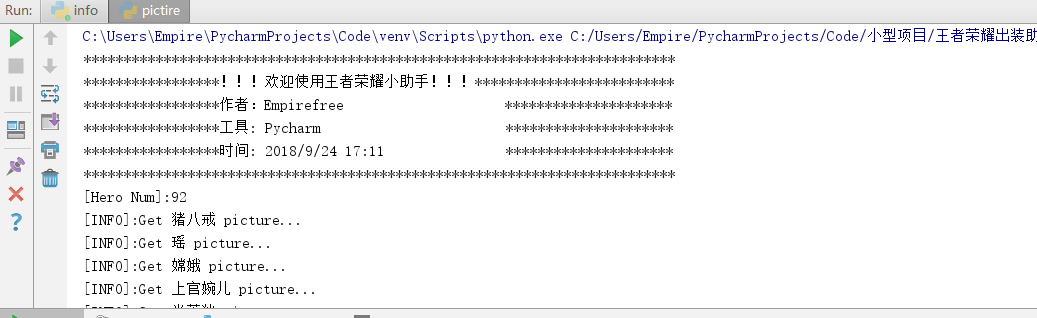

/***************************************************************************************************************************************************************************************************/
1.自动刷王者荣耀金币(主要):
配置环境
adb环境配置: https://www.cnblogs.com/yc8930143/p/8259486.html
i. pip 安装PIL模块
ii. pip安装six模块
iii. pip安装shutil模块
iv. pip安装subprocess模块
v. pip安装numpy模块
vi. pip安装matplotlib模块
模拟器或者手机什么的只要adb device 能识别就行,端口什么的不影响,然后命令行在文件根目录下运行即可。
过程:
基本环境弄好后,代码就是search_jump的像素识别(大小为模拟器或手机界面大小),在一定范围内进行点击,然后循环点击即可,感觉可以用到其他APP上面(比如全名K歌签到领取鲜花等等)或者服务器上装一个windows系统,这样就可以一直跑了.
注意:并不是只有一个automain.py代码,其中涉及到其他文件夹下的函数调用,主要就是模拟点击功能的实现吧。
代码解析:
screent_shot(屏幕截图):screen_way是截图方式,通过pull_screenshot和check_screenshot进行屏幕截图,便于后面图片像素分析(读者也可自己加入选择部分截图功能)
yes_or_no:基本连接手机或模拟器函数,判断电脑是否连接上外设
然后就是search_jump,game_next等基本函数了,感觉还是蛮容易理解的,给出源代码吧
链接: https://pan.baidu.com/s/1PXDPduSEUbAw-pOvrypM4A 提取码: am7s
2.爬取图片和验证码(次要)
识别官网API接口即可,然后简单处理信息,对于爬虫还算一个比较好的入门,给出完整代码
picture.py代码:
核心API接口就是:http://gamehelper.gm825.com/wzry/hero/list?game_id=7622 ,然后用户简单分析一下json数据即可
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/24 17:11
# @Author : Empirefree
# @File : 爬取照片.py
# @Software: PyCharm
import requests
import os
from urllib.request import urlretrieve def download(url):
headers = {
'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'Keep-Alive'
}
res = requests.get(url, headers=headers).json()
hero_num = len(res['list'])
print('[Hero Num]:%d' % hero_num)
for hero in res['list']:
pic_url = hero['cover']
hero_name = hero['name'] + '.jpg'
filename = './images/' + hero_name
if 'images' not in os.listdir():
os.makedirs('images')
urlretrieve(url=pic_url, filename=filename)
print('[INFO]:Get %s picture...' % hero['name']) if __name__ == '__main__':
print('**************************************************************************')
print('*****************!!!欢迎使用王者荣耀小助手!!!*************************')
print('*****************作者:Empirefree *********************')
print('*****************工具: Pycharm *********************')
print('*****************时间: 2018/9/24 17:11 *********************')
print('**************************************************************************')
download("http://gamehelper.gm825.com/wzry/hero/list?game_id=7622")
print('**************************************************************************')
print('照片已下载到您images目录下,请保证有网条件下执行本程序')
print('**************************************************************************')
n = input('回车结束........')
info.py代码
分析:和上述代码差不多,也是接口分析问题: http://gamehelper.gm825.com/wzry/equip/list?game_id=7622 ,个人感觉比较好用的就是网络图片下载的语句
下载图片:urlretrieve()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/24 17:49
# @Author : Empirefree
# @File : info.py
# @Software: PyCharm
import requests
import time class Spider():
def __init__(self):
self.headers = {
'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'Keep-Alive'
}
self.weapon_url = "http://gamehelper.gm825.com/wzry/equip/list?game_id=7622"
self.heros_url = "http://gamehelper.gm825.com/wzry/hero/list?game_id=7622"
self.hero_url = "http://gamehelper.gm825.com/wzry/hero/detail?hero_id={}"
print('*' * 60)
print('[INFO]:王者荣耀助手...')
print('[Usage]:请输入英雄ID获取英雄信息...')
print('[Author]:Empirefree')
print('*' * 60)
# 外部调用函数
def run(self):
heroId_exist = self._Get_HeroId()
heroId = input('\nEnter the Hero ID:')
if heroId not in heroId_exist:
print('[Error]:HeroId inexistence...')
return
weapon_info = self._Get_WeaponInfo()
self._Get_HeroInfo(weapon_info, heroId)
# 获得英雄ID
def _Get_HeroId(self):
res = requests.get(url=self.heros_url, headers=self.headers)
heros = res.json()['list']
num = 0
heroId_list = []
for hero in heros:
num += 1
print('%sID: %s' % (hero['name'], hero['hero_id']), end='\t\t\t')
heroId_list.append(hero['hero_id'])
if num == 3:
num = 0
print('')
return heroId_list
# 获取武器信息
def _Get_WeaponInfo(self):
res = requests.get(url=self.weapon_url, headers=self.headers)
weapon_info = res.json()['list']
return weapon_info
# 获得出装信息
def _Get_HeroInfo(self, weapon_info, heroId):
def seek_weapon(equip_id, weapon_info):
for weapon in weapon_info:
if weapon['equip_id'] == str(equip_id):
return weapon['name'], weapon['price']
return None
res = requests.get(url=self.hero_url.format(heroId), headers=self.headers).json()
print('[%s History]: %s' % (res['info']['name'], res['info']['history_intro']))
num = 0
for choice in res['info']['equip_choice']:
num += 1
print('\n[%s]:\n %s' % (choice['title'], choice['description']))
total_price = 0
for weapon in choice['list']:
weapon_name, weapon_price = seek_weapon(weapon['equip_id'], weapon_info)
print('[%s Price]: %s' % (weapon_name, weapon_price))
if num == 3:
print('')
num = 0
total_price += int(weapon_price)
print('[Ultimate equipment price]: %d' % total_price) if __name__ == '__main__':
while True:
Spider().run()
time.sleep(5)
到此算是整理完王者荣耀写过的代码了,QAQ。
Python-王者荣耀自动刷金币+爬取英雄信息+图片的更多相关文章
- python协程gevent案例:爬取斗鱼美女图片
分析 分析网站寻找需要的网址 用谷歌浏览器摁F12打开开发者工具,然后打开斗鱼颜值分类的页面,如图: 在里面的请求中,最后发现它是以ajax加载的数据,数据格式为json,如图: 圈住的部分是我们需要 ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- python爬虫---实现项目(一) Requests爬取HTML信息
上面的博客把基本的HTML解析库已经说完了,这次我们来给予几个实战的项目. 这次主要用Requests库+正则表达式来解析HTML. 项目一:爬取猫眼电影TOP100信息 代码地址:https://g ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
随机推荐
- .gitignore文件的配置和生效
1.配置 a)确保.gitignore文件和.git文件夹在同级目录 b)配置语法 # # 此为注释 – 将被 Git 忽略 *.a # 忽略所有 .a 结尾的文件 !lib.a # 但 lib.a ...
- 在Fastreport里使用的CRC函数
如标题, 是在Fastreport的脚本里运行的CRC计算函数, 包括CRC-16/CRC-32 基本是从网上找的代码, 然后改出来的 至于为什么要在FR的脚本里运行....呵呵 不要在意这些细节(找 ...
- 另存了一次网页之后其它word打开格式都变了
解决方案: 视图->页面视图 感觉自己很傻...原来另存word为网页后,默认的打开模式就是网页视图了.只需要把视图改回去即可
- Spring Boot(一):环境搭建,建立简单项目
一.基本环境搭建 1.下载IntelliJ IDEA :http://www.jetbrains.com/idea/ 2.拖到页面最下面下载旗舰版 3.新建项目 4.设置本地Maven 5.删除多于文 ...
- 前端 CSS语法
每个CSS样式由两个组成部分: 1.选择器 2.声明 声明由属性和值组成,每个声明之后用分号结束.
- 【jdbc访问数据库获取执行sql转换json】
Talk is cheap.Show me your code. import java.sql.*; import java.util.HashMap; import java.util.Map; ...
- BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 序
BIML 101 - BIML 快速入门教程 做大数据的项目,最花时间的就是数据清洗. 没有一个相对可靠的数据,数据分析就是无木之舟,无水之源. 如果你已经进了ETL这个坑,而且预算有限,并且有大量的 ...
- mongodb非关系型数据库
mongodb非关系型数据库(对象型数据库): 优势:易扩展:灵活的数据模型:大数据量,高性能(读写) 关系型:(一对多.多对多.一对一)扩展性差,大数据下压力大,表结构更改困难(数据小时使用Mysq ...
- Android -- Glide框架详解(一)
1,使用这个框架快两年了,今天去github上去看了一下,貌似已经从3.X升级到4.X了,想着自己还没有对这个框架在博客上做过总结,所以这里打算出三篇博客来介绍,内容有基本使用.3.X与4.X的不通. ...
- PYTHON装饰器用法及演变
'''开放封闭原则: 软件一旦上线之后就应该满足开放封闭原则 具体就是指对修改是封闭的,对扩展是开放的装饰器:什么是装饰器:装饰就是修饰,器指的是工具装饰器本省可以是任意可调用的对象被装饰的对象也可以 ...