面试- 阿里-. 大数据题目- 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
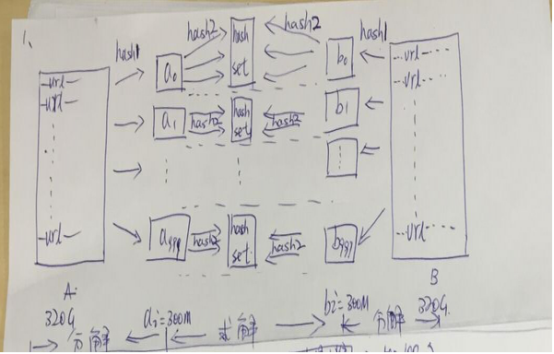
假如每个url大小为10bytes,那么可以估计每个文件的大小为50G×64=320G,远远大于内存限制的4G,所以不可能将其完全加载到内存中处理,可以采用分治的思想来解决。
Step1:遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999,每个小文件约300M);
Step2:遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,...,b999);
巧妙之处:这样处理后,所有可能相同的url都被保存在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出这个1000对小文件中相同的url即可。
Step3:求每对小文件ai和bi中相同的url时,可以把ai的url存储到hash_set/hash_map中。然后遍历bi的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
草图如下(左边分解A,右边分解B,中间求解相同url):
2.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
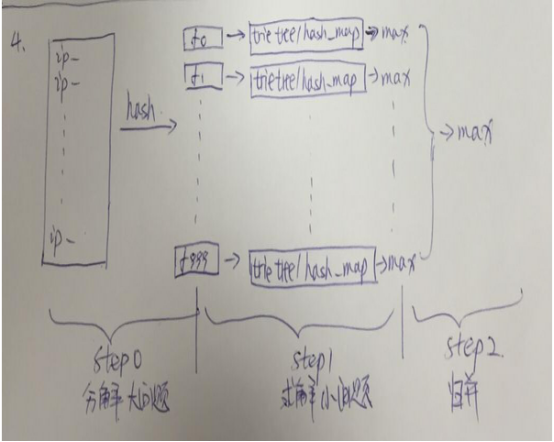
Step1:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为f0,f1,...,f4999)中,这样每个文件大概是200k左右,如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
Step2:对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件;
Step3:把这5000个文件进行归并(类似与归并排序);
草图如下(分割大问题,求解小问题,归并):
草图如下(分割大问题,求解小问题,归并):
3.现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
Step1:从这一天的日志数据中把访问百度的IP取出来,逐个写入到一个大文件中;
Step2:注意到IP是32位的,最多有2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件;
Step3:找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率;
Step4:在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
草图如下:
面试- 阿里-. 大数据题目- 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?的更多相关文章
- 给定a、b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如何找出a、b文件共同的url?
给定a.b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如何找出a.b文件共同的url? 可以估计每个文件的大小为5G*64=300G,远大于4G.所以不可能将其完全加载到 ...
- java面试(2)--大数据相关
第一部分.十道海量数据处理面试题 1.海量日志数据,提取出某日访问百度次数最多的那个IP. 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^ ...
- 阿里大数据竞赛season1 总结
关于样本测试集和训练集数量上,一般是选择训练集数量不小于测试集,也就是说训练集选取6k可能还不够,大家可以多尝试得到更好的效果: 2. 有人提出归一化方面可能有问题,大家可以查查其他的归一化方法,但是 ...
- "大中台、小前台”新架构下,阿里大数据接下来怎么玩? (2016-01-05 11:39:50)
"大中台.小前台”新架构下,阿里大数据接下来怎么玩?_炬鼎力_新浪博客 http://blog.sina.com.cn/s/blog_1427354e00102vzyq.html " ...
- 阿里大数据产品Dataphin上线公共云,将助力更多企业构建数据中台
日前,由阿里数据打造的智能数据构建与管理Dataphin,重磅上线阿里云-公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客户高效自动化 ...
- 阿里大数据比赛sesson2_RF&GBRT(下)
-----------__-----------接上文---------__---------- 2.Xlab RF上手 2.1.训练特征表准备 训练的特征表gbrt_offline_section_ ...
- 【剑指Offer面试编程题】题目1509:树中两个结点的最低公共祖先--九度OJ
题目描述: 给定一棵树,同时给出树中的两个结点,求它们的最低公共祖先. 输入: 输入可能包含多个测试样例. 对于每个测试案例,输入的第一行为一个数n(0<n<1000),代表测试样例的个数 ...
- 【剑指Offer面试编程题】题目1519:合并两个排序的链表--九度OJ
题目描述: 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. (hint: 请务必使用链表.) 输入: 输入可能包含多个测试样例,输入以EOF结束. 对于每 ...
- 【剑指Offer面试编程题】题目1512:用两个栈实现队列--九度OJ
题目描述: 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 输入: 每个输入文件包含一个测试样例. 对于每个测试样例,第一行输入一个n(1<=n<=1 ...
随机推荐
- 梯度下降、随机梯度下降、方差减小的梯度下降(matlab实现)
梯度下降代码: function [ theta, J_history ] = GradinentDecent( X, y, theta, alpha, num_iter ) m = length(y ...
- Java基础——JVM内存结构
推荐阅读:https://www.cnblogs.com/wangjzh/p/5258254.html 一.内存结构图 先导知识: 一个 Java 源程序文件,会被编译为字节码文件(以 class 为 ...
- 20155316 2015-2017-2 《Java程序设计》第4周学习总结
教材学习内容总结 继承 多态 重新定义 java.lang.object 垃圾收集机制 接口与多态 接口枚举常数 学习笔记存放(部分) 标准类 继承 static与权限修饰 [请勿转载,谢谢] 教材学 ...
- 修改cmd为utf-8编码:
1.组合键WIN+R键,组合键后就会弹出窗口,然后输入CMD,回车: 2.要修改成UTF8编码,输入命令CHCP 65001(设置为65001): 3.鼠标放在命令窗口的标题部分右键,在弹出的右键菜单 ...
- Centos安装man功能
CentOS接触很久了,但是一直作为服务器端使用.这次之所以安装man,是由于开始学习Nginx了. 言归正传,安装man,首先得下载包.由于我们天朝的原因,代码包几乎下不到的.首先你得FQ,再下载, ...
- vmware因为软件出过一次复制的错误导致不能复制到主机的解决方法
只需要把vmware的虚拟机进程全部结束掉,然后重置(先设置不勾选复制等,然后保存后在勾选上并保存)一次虚拟机隔离设置(需要在关闭虚拟机的情况下设置,否则就是灰色不允许操作),然后再开启虚拟机,就能正 ...
- java IO操作:FileInputStream,FileOutputStream,FileReader,FileWriter实例
FileInputStream <span style="font-family:Verdana;">import java.io.File; import java. ...
- Phaser3让超级玛丽实现轻跳、高跳及加上对应的跳跃声音
mario jumper 在线测试地址:http://www.ifiero.com/uploads/phaserjs3/jumper/ 空格键:轻按:跳低 ,长按:跳高键盘:--> 向右 , ...
- Siki_Unity_3-8_Lua编程(未完)
Unity 3-8 Lua编程 任务1&2&3:前言 课程内容: Lua从入门到掌握 为之后的xLua和其他热更新方案打下基础 任务4:Lua简介 Lua是轻量小巧的脚本语言--无需编 ...
- Java线程Run和Start的区别
先上结论:run只是Thread里面的一个普通方法,start是启动线程的方法.何以见得呢?可以执行下面的代码看看run和start的区别: package com.basic.thread; /** ...