Intellij IDEA 2017 通过scala工程运行wordcount
首先是安装scala插件,可以通过idea内置的自动安装方式进行,也可以手动下载可用的插件包之后再通过idea导入。
scala插件安装完成之后,新建scala项目,右侧使用默认的sbt
点击Next,到这一步就开始踩坑了,scala的可选版本比较多,从2.12到2.10都有,我的环境下用wordcount的例子尝试了几种情况:
先贴上测试代码,以下的测试全都是基于这段代码进行的。
package com.hq import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
} val conf = new SparkConf()
val sc = new SparkContext("local","wordcount",conf)
val line = sc.textFile(args(0)) line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop()
}
}
1. scala如果用2.12.4的版本,运行时就会报错。可能跟我写的代码有关,scala 2.12.x使用spark的方式可能不一样,后面再看。不过官网上有说spark-2.2.1只能与scala-2.11.x兼容,所以这个就没有再试了

2. scala如果使用2.11.x的版本,我这边最初按照网上的各种教程,一直在尝试使用spark-assembly-1.6.3-hadoop2.6.0.jar,结果也是报错。

然后想着试一下最新的spark-2.2.1-bin-hadoop2.7,但是里面没有spark-assembly-1.6.3-hadoop2.6.0.jar,就索性把jars目录整个加到工程中,运行也是出错,但明显是能运行了。
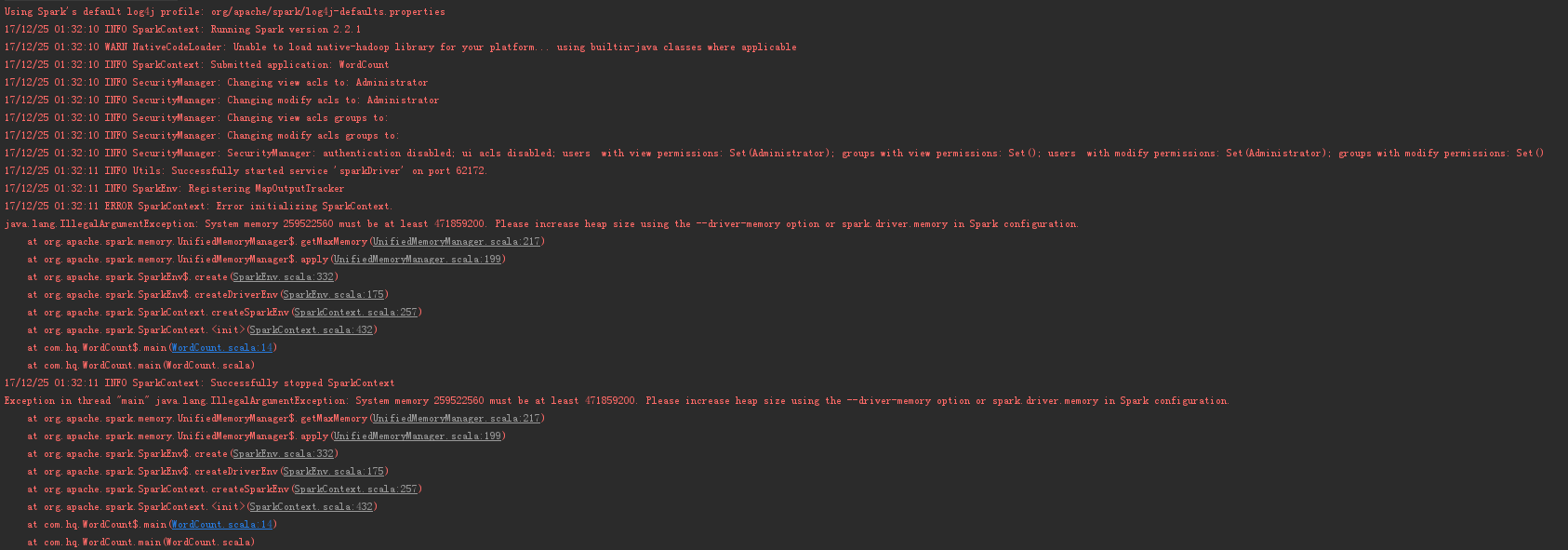
百度之,加上一句设置就可以了
conf.set("spark.testing.memory", "2147480000")
3. scala如果使用2.10.x,根据网上的各种教程,我使用的是2.10.6,只需要在工程中加入spark-assembly-1.6.3-hadoop2.6.0.jar这个包即可,当然,还有内存大小的配置。
另外,在使用2.10.6的时候,idea在下载scala-library, scala-compiler, scala-reflect各种包时都出错,只能手动下载,再放到缓存目录下: "C:\Users\Administrator\.ivy2\cache\org.scala-lang"。
顺便收藏一个网址,也许以后还要用: http://mvnrepository.com/artifact/org.scala-lang/scala-library
待处理的问题:
1. 运行时内存大小的设置,应该可以通过修改idea的配置项来做到,就不用在代码里面加这个
2. idea的缓存目录还需要修改,不然用的时间长了,C盘要崩...
3. 虽然wordcount运行成功了,但是会有warning...
Intellij IDEA 2017 通过scala工程运行wordcount的更多相关文章
- IntelliJ IDEA 2017.3 配置Tomcat运行web项目教程(多图)
小白一枚,借鉴了好多人的博客,然后自己总结了一些图,尽量的详细.在配置的过程中,有许多疑问.如果读者看到后能给我解答的,请留言.Idea请各位自己安装好,还需要安装Maven和Tomcat,各自配置好 ...
- Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Intellij IDEA下导出Java工程的可运行JAR包
Intellij IDEA下导出Java工程的可运行JAR包 昨天一直向导出一个Java工程的可运行JAR包,然后查阅网上的资料以及自己一遍一遍的尝试,均以失败告终.可以导出JAR包,但是导出的JAR ...
- 使用IntelliJ IDEA创建Maven聚合工程、创建resources文件夹、ssm框架整合、项目运行一体化
一.创建一个空的项目作为存放整个项目的路径 1.选择 File——>new——>Project ——>Empty Project 2.WorkspaceforTest为项目存放文件夹 ...
- 【转载】使用IntelliJ IDEA创建Maven聚合工程、创建resources文件夹、ssm框架整合、项目运行一体化
一.创建一个空的项目作为存放整个项目的路径 1.选择 File——>new——>Project ——>Empty Project 2.WorkspaceforTest为项目存放文件夹 ...
- 下载安装tomcat和jdk,配置运行环境,与Intellij idea 2017关联
第一篇博客,最近公司要用java和jsp开发新的项目,第一次使用Intellij idea 2017,有很多地方需要一步步配置,有些按照网上的教程很快就配置好了,有的还是琢磨了一会儿,在这里做一个记录 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- Spark学习笔记-如何运行wordcount(使用jar包)
IDE:eclipse Spark:spark-1.1.0-bin-hadoop2.4 scala:2.10.4 创建scala工程,编写wordcount程序如下 package com.luoga ...
- Intellij IDEA 2017 详细图文教程之概述
天天编码 , 版权所有丨本文标题:Intellij IDEA 2017 详细图文教程之概述 转载请保留页面地址:http://www.tiantianbianma.com/intellij-idea- ...
随机推荐
- python3 安装win32api
Python3 中先安装pip install pywin32 但是在调用时任然说找不到该模块,于是查找资料后得出需要使用python -m pip install pypiwin32.
- TensorFlow学习('utf-8' codec can't decode byte 0xff in position 0: invalid start byte)
使用语句: image_raw_data = tf.gfile.GFile("./picture.jpg", "r").read() 读取图像时报错如下: Un ...
- chrome下载离线安装包的方法
https://www.google.com/chrome/browser/desktop/index.html?system=true&standalone=1,一般默认下载稳定版,如果需要 ...
- selenium + python自动化测试unittest框架学习(五)webdriver的二次封装
因为webdriver的api方法很长,再加上大多数的定位方式是以xpath方式定位,更加让代码看起来超级长,为了使整体的代码看起来整洁,对webdriver进行封装,学习资料来源于虫师的<se ...
- istringstream和ostringstream的实现
ostringstream是将数据写入string里边的,istringstream是将从string里边读出数据的: #include <sstream> int main() { st ...
- 想要使用 for循环,就要添加 索引器
- Java8 Stream()关于在所有用户的所有上传记录中,找出每个用户最新上传记录
原创文章:转载请标明出处 https://www.cnblogs.com/yunqing/p/9504196.html 首先分析相当于如下,在所有的猫中,每个名字的猫都保留年龄最小的一个 import ...
- [转]MBTiles 离线地图演示 - 基于 Google Maps JavaScript API v3 + SQLite
MBTiles 是一种地图瓦片存储的数据规范,它使用SQLite数据库,可大大提高海量地图瓦片的读取速度,比通过瓦片文件方式的读取要快很多,适用于Android.IPhone等智能手机的离线地图存储. ...
- "strace -p"非常有用,它减少了很多猜测工作,也不需要重新启动应用。lsof -p process_id +iostat + sar -n DEV 1
linux神器strace - youxin - 博客园https://www.cnblogs.com/youxin/p/8837771.html 某个进程突然占用了很多CPU? 或者某个进程看起来像 ...
- Bootstrap03
一.表单(以下示例 * 代表class) 注意:a.使用表单的关键字form b.所有的提示词使用label包裹 c.所写内容按div分类,使得层次分明 1.基本表单+表单组合+内联表单 *=form ...