Hadoop集群环境搭建(一)
1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
本集群搭建案例,以3节点为例进行搭建,角色分配如下:
hdp-node- NameNode SecondaryNameNode ResourceManager
hdp-node- DataNode NodeManager
hdp-node- DataNode NodeManager
2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
▨ Vmware 12.0
▨ Centos 7.0 64bit
3网络环境准备
▨ 采用NAT方式联网
▨ 网关地址:192.168.33.1
▨ 3个服务器节点IP地址:192.168.33.101、192.168.33.102、192.168.33.103
▨ 子网掩码:255.255.255.0
4服务器系统设置
▨ 添加HADOOP用户
▨ 为HADOOP用户分配sudoer权限
▨ 同步时间
▨ 设置主机名
◈ hdp-node-01
◈ hdp-node-02
◈ hdp-node-03
▨ 配置内网域名映射:
◈ 192.168.33.101 hdp-node-01
◈ 192.168.33.102 hdp-node-02
◈ 192.168.33.103 hdp-node-03
▨ 配置ssh免密登陆
▨ 配置防火墙
5JDK环境安装
▨ 上传jdk安装包
▨ 规划安装目录 /home/hadoop/apps/jdk_1.7.65
▨ 解压安装包
▨ 配置环境变量 /etc/profile
6HADOOP安装部署
▨ 上传HADOOP安装包
▨ 规划安装目录 /home/hadoop/apps/hadoop-2.6.5
▨ 解压安装包 tar –zxvf hadoop-2.6.5 –C apps/
▨ 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1..0_45
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-node-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/HADOOP/apps/hadoop-2.6.5/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp-node-01:50090</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi salves
hdp-node-02
hdp-node-03
7启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
查看集群状态
jps
bin/hdfs dfsadmin -report
8测试——运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.5.jar wordcount /wordcount/input /wordcount/output
9HDFS使用
1、查看集群状态
命令: hdfs dfsadmin –report
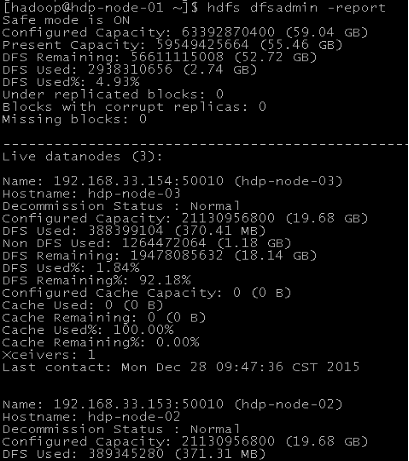
可以看出,集群共有3个datanode可用
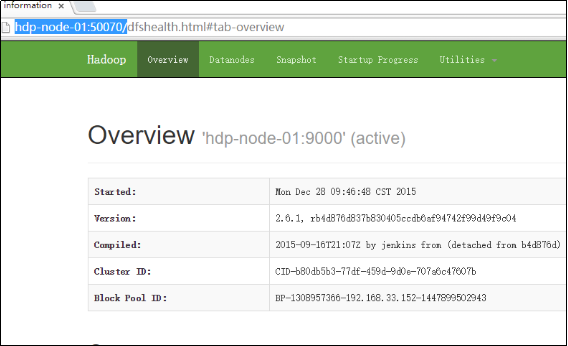
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node-01:50070/
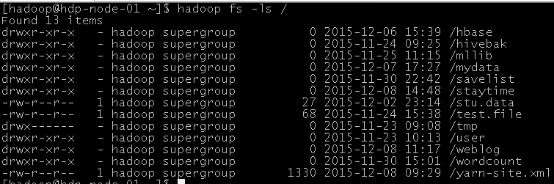
2、上传文件到HDFS
▣ 查看HDFS中的目录信息
命令: hadoop fs –ls /
▣ 上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /

出处:http://www.cnblogs.com/jerehedu/
版权声明:本文版权归烟台杰瑞教育科技有限公司和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
技术咨询:

Hadoop集群环境搭建(一)的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Hadoop(4)-Hadoop集群环境搭建
准备工作 开启全部三台虚拟机,确保hadoop100的机器已经配置完成 分发脚本 操作hadoop100 新建一个xsync的脚本文件,将下面的脚本复制进去 vim xsync #这个脚本使用的是rs ...
随机推荐
- BufferedWriterTest
public class BufferedWriterTest { public static void main(String[] args) { try { //创建一个FileWriter 对象 ...
- c#编程-线程同步
线程同步 上一篇介绍了如何开启线程,线程间相互传递参数,及线程中本地变量和全局共享变量区别. 本篇主要说明线程同步. 如果有多个线程同时访问共享数据的时候,就必须要用线程同步,防止共享数据被破坏.如果 ...
- DotNetCore跨平台~服务总线_事件总线的重新设计
理论闲话 之前在.netFramework平台用的好好的,可升级到.net core平台之后,由于不再需要二进制序列化,导致咱们的事件机制遇到了问题,之前大叔的事件一直是将处理程序序列化后进行存储的, ...
- Java电器商场小系统--简单的java逻辑
//商场类public class Goods { int no; //编号 String name; //商品名称 double price; //商品价格 int number; //商品数量 / ...
- 一个move_uploaded_file()引起的PHP异常与错误的深入理解
背景:我在公司开发一个产品Excel导入到数据库的功能,写起来挺快的,用phpexcel几下就写好了,本地测试挺顺的,git push上去,项目负责人部署到测试环境,就出现问题了.具体问题一句话不好说 ...
- Python 批量翻译 使用有道api;
妹子是做翻译相关的,遇到个问题,要求得到句子中的所有单词的 音标; 有道翻译只能对单个单词翻译音标,不能对多个单词或者句子段落翻译音标; 手工一个一个翻的话那就要累死人了.....于是就让我写个翻译音 ...
- [编辑器]vim常用操作
我是ide的用户,对于vim一只停留在:打开.看.写.关闭基本操作,因为现在更多的接触linux服务器,所以为了提高 效率,用好vim是必备技能!下面罗列一些vim的常用操作,用做备忘(不断更新): ...
- MySQL日志文件之错误日志和慢查询日志详解
今天天气又开始变得很热了,虽然很热很浮躁,但是不能不学习,我在北京向各位问好.今天给大家分享一点关于数据库日志方面的东西,因为日志不仅讨厌而且还很重要,在开发中时常免不了与它的亲密接触,就在前几天公司 ...
- (转)eclipse安装jetty
背景:在项目开发的过程中,一个老的项目使用的是jetty启动,在用tomcat启动的过程中出现了启动不了的异常,浪费了好多时间.因为项目一直是用jetty启动的,为了不浪费时间,也只好改变思路选择je ...
- log4go的日志滚动处理——适应生产环境的需要
日志处理有三类使用环境,开发环境DE,测试环境TE,生产环境PE. 前两类可以看成是一类,重要的是屏幕显示--termlog.生产环境中主要用的是socklog 和 filelog,即网络传输日志和文 ...