在AWS中部署OpenShift平台
OpenShift是RedHat出品的PAAS平台。OpenShift做为PAAS平台最大的特点是它是完全容器化的PAAS平台,底层封装了Docker和Kubernetes,上层暴露了对开发者友好的接口来完成对应用程序的集成、部署、弹性伸缩等任务。
Docker提供了对打包和创建基于Linux的轻量级容器的抽象。而Kubernetes提供了多主机集群管理和Docker容器编排。OpenShift基于Docker和Kubernetes加入了新的功能:
- 源代码管理、构建和部署
- 在系统中集成镜像的管理
- 按需扩展的应用程序管理
- 在大型开发者组织中进行团队管理和用户追踪
OpenShift直接提供支持的应用程序镜像有:
OpenShift直接提供支持的数据库镜像有:

除此之外,OpenShift还让你通过一键点击便生成相应的应用,比如几秒之内搭建好一个Jenkins服务。包括以下:

OpenShift架构概览
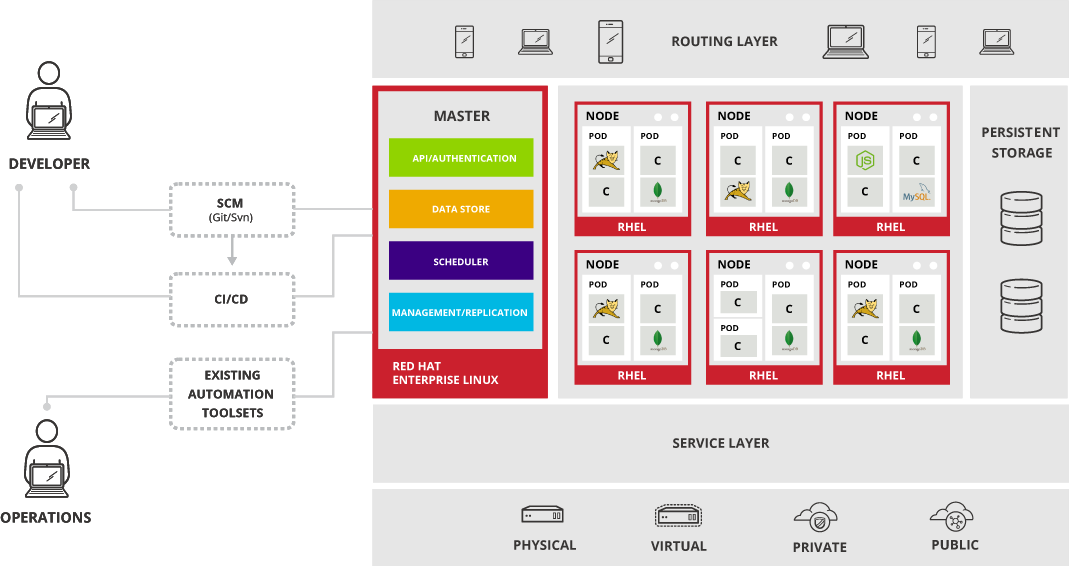
从上图可以看出,OpenShift的典型用户分为两种,开发人员和运维人员。开发人员可以通过现有的代码管理工具和持续集成、交付工具利用OpenShift完成对应用程序的打包、部署、扩容操作。而运维人员可以利用现有的自动化工具实现对OpenShift平台的维护。
OpenShift中的Kubernetes用来管理跨宿主机(或容器)的容器化应用程序,并提供部署、维护和应用程序扩容机制。对于一个Kubernetes集群来说,它包括一个或多个master以及一组node。
Master主机托管了API服务器、controller manager服务器以及etcd实例。Master管理Kubernetes集群中的节点并控制运行在节点上的pod。
Node则提供了容器的运行时环境。Kubernetes节点中的每个node会运行受Master管理的服务,当然也包括Docker、Kubelet及serverice proxy服务。node可以为云机器、物理系统或者虚拟系统。Kubelet用来更新node上的运行的容器状态。Service Proxy用于运行一个简单的网络代理,来反映定义在node的API中的服务,从而使node可以跨后端进行简单的TCP和UDP流转发。
OpenShift架设要求
如果想自己架设OpenShift平台作为商业用途,必须要获取OpenShift Enterprise的付费订阅。目前OpenShift Enterprise的最新版本为3.6版。对于Master和Node节点的系统要求如下。
Master:
- 物理或虚拟机,或者运行于公有云或私有云之上的实例
- 基础操作系统为Red Hat企业版Linux(RHEL)7.1,并包含最小的安装选项
- 2核CPU
- 最小8GB内存
- 最小30GB硬盘空间
Node:
- 物理或虚拟机,或者运行于公有云或私有云之上的实例
- 基础操作系统为Red Hat企业版Linux(RHEL)7.1,并包含最小的安装选项
- Docker 1.6.2及以上版本
- 1核CPU
- 最小8GB内存
- 最小15GB硬盘空间
- 另外最小15GB的未分配空间,需要通过docker-storage-setup进行配置
环境要求:
- 需要一个DNS zone来解析OpenShift router的IP地址。比如*.cloudapps.example.com. 300 IN A 192.168.133.2
- Master和Node之间必须要有共享的网络,两者之间可以互相通讯。
- 需要一个Git Server和能够访问该Server的账号。
AWS中部署OpenShift平台
下图是一个在AWS中的OpenShift集群的示例。
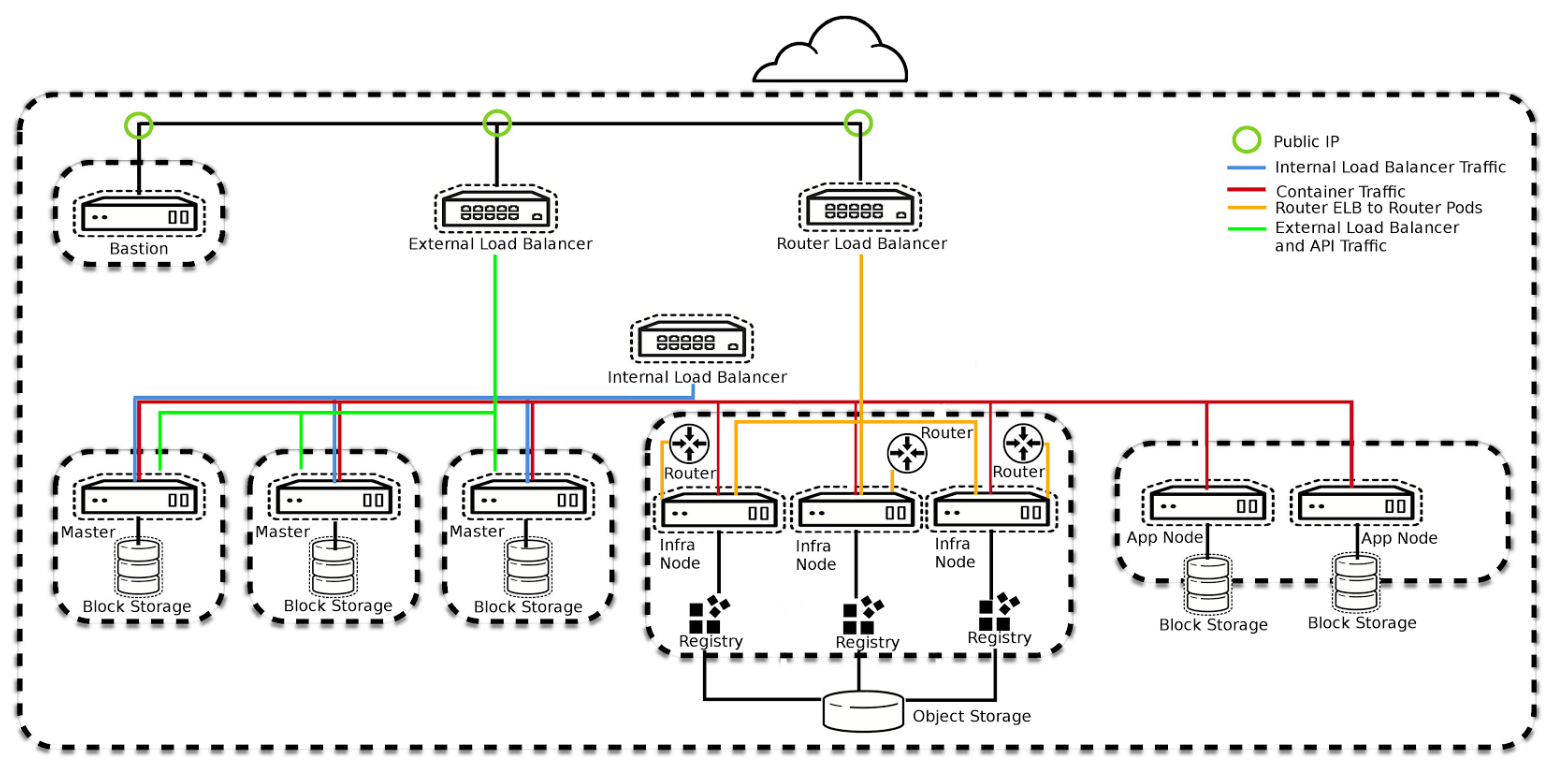
Master节点:包含3个Master实例,实现高可用,上面运行etcd、通过一个external load balancer向外暴露服务。
Infra Node: 由三个实例组成,这三个实例用来运行支撑OpenShift集群服务的一系列容器。
App Node:用于运行应用程序容器的实例,可以按需进行扩展。
Bastion:用于限制对集群中实例的ssh访问,增强安全性。
存储:OpenShift使用EBS作为实例的文件系统并用于持久化容器的存储;另外还使用S3这个对象存储服务作为OpenShift registry的存储。
ELB:总共有三个.一个用来在集群外访问OpenShift API、OpenShift console。一个在集群内访问OpenShift API。另一个用来访问通过route暴露的部署在集群中的应用程序服务。最后通过AWS的Route53来管理DNS。
部署OpenShift集群的三个阶段
在AWS中部署OpenShift集群包括三个阶段:
- 第一阶段:在AWS中设置好基础设施
- 第二阶段: 在AWS上部署OpenShift Container平台
- 第三阶段: 部署后的环境检查
关于整个部署活动绝大多数都是可以自动化的。RedHat提供了一个GitHub repo:openshift-ansible-contrib。openshift-ansible-contrib提供了将OpenShift集群部署到不同的Cloud供应商的解决方案,当然也包括了AWS。里面包含了相应的文档、代码以及脚本。RedHat提供了一个叫做openshift-ansible-playbooks的RPM包,openshift-ansible-contrib利用该RPM包来完成阶段1和阶段2,在阶段3中我们可以利用一些现有的脚本工具实现环境检查和认证。
对AWS环境的要求
选择部署的AWS区域需要至少有三个可用区以及2个EIP。该OpenShift平台需要新建三个公共子网和三个私有子网。
由于需要新建一大批的AWS资源,所以必须要提供一个有适当权限的AWS用户,包括创建账号、使用S3、Route53、ELB、EC2等。
六个子网需要在一个VPC中。Ansible脚本会建立一个NAT Gateway用来供内部的EC2实例访问外网。同时也会建立8个Security Groups来限制不同的实例、ELB和外部网络间的访问。
openshift-ansible-contrib提供了部署基础设施、安装和配置OpenShift以及扩展router和registry的功能。运行Ansible的机器必须是RHEL7操作系统。具体的安装过程可参见https://access.redhat.com/documentation/en-us/reference_architectures/2017/html/deploying_openshift_container_platform_3.5_on_amazon_web_services/deploying_openshift%E3%80%82
总结
在AWS上部署OpenShift平台并不是一件轻松的事情,一方面需要对AWS的各种服务了如执掌,一方面也需要对OpenShift的架构和核心概念有所了解。虽然RedHat提供了一些Ansible脚本和RPM包来简化安装,但整个过程也绝非一片坦途。安装完备之后,如何和企业现有的应用程序开发流程、持续交付流水线结合起来无缝过度,也是一件非常考验人的事情。下一篇文章会对这些方面进行揭秘。
在AWS中部署OpenShift平台的更多相关文章
- openshift 平台上部署 gitlab代码仓库服务
背景: 本文档将以在openshift 平台上部署 gitlab 服务来验证集群各个服务组件的可用性以及熟悉openshift的使用方法.服务部署方式可以多种多样,灵活部署.本篇以常见的镜像部署方式来 ...
- 概念验证:在Kubernetes中部署ABAP
对于将SAP ABAP应用服务器组件容器化和在Kubernetes中部署它们,我们在SPA LinuxLab中做了概念验证(PoC),本文将介绍一些我们的发现和经验.本文会也会指出这项工作的一些潜在的 ...
- 在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练
在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练 自动驾驶汽车的深度神经网络(DNN)开发是一项艰巨的工作.本文验证了DGX多节点,多GPU,分布式训练在DXC机器 ...
- 基于Kubernetes在AWS上部署Kafka时遇到的一些问题
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 交代一下背景:我们的后台系统是一套使用Kafka消息队列的数据处理管线 ...
- openstack(liberty):部署实验平台(一,基础网络环境搭建)
openstack项目的研究,到今天,算是要进入真实环境了,要部署实验平台了.不再用devstack了.也就是说,要独立controller,compute,storage和network了.要做这个 ...
- China Azure中部署Kubernetes(K8S)集群
目前China Azure还不支持容器服务(ACS),使用名称"az acs create --orchestrator-type Kubernetes -g zymtest -n kube ...
- AWS中,如果使用了ELB,出现outofservice
平台:亚马逊AWS EC2 出现状况: 我创建了弹性平衡负载,也注册了实例,但是实例的状态一直是outofservice.为什么? 为什么会出现这个问题呢? 1:实例有问题: 2:负载平衡器创建的有问 ...
- 微服务架构 - 离线部署k8s平台并部署测试实例
一般在公司部署或者真实环境部署k8s平台,很有可能是内网环境,也即意味着是无法连接互联网的环境,这时就需要离线部署k8s平台.在此整理离线部署k8s的步骤,分享给大家,有什么不足之处,欢迎指正. 1. ...
- 怎样在win7 IIS中部署网站
怎样在win7 IIS中部署网站? IIS作为微软web服务器的平台,可以轻松的部署网站,让网站轻而易举的搭建成功,那么如何在IIS中部署一个网站呢,下面就跟小编一起学习一下吧. 第一步:发布IIS文 ...
随机推荐
- requirejs 加载其它js
基本代码: require.config({ // baseUrl : '/js/' paths: { jquery: '/js/jquery-1.11.3.min', validate: '/js/ ...
- 【转载】CANoe 入门 Step by step系列(一)基础应用
来源:http://www.cnblogs.com/dongdonghuihui/archive/2012/09/26/2704611.html CANoe是Vector公司的针对汽车电子行业的总线分 ...
- Java之异常处理,日期处理
Java异常处理 异常:异常就是Java程序在运行过程中出现的错误. 异常由来:问题也是现实生活中一个具体事务,也可以通过java 的类的形式进行描述,并封装成对象.其实就是Java对不正常情况进行描 ...
- jenkins2 -pipeline 常用groovy脚本
jenkins2的核心是pipeline,pipeline的核心是groovy. 那有一些基础的groovy是必须经常使用的,如变量赋值,变量引用,打印变量,输出字符,任务调用,循环判断等. Groo ...
- (转)如何将 Excel 文件导入到 Navicat for MySQL 数据库
场景:工作中需要统计一段时间的加班时长,人工统计太过麻烦,就想到使用程序实现来统计 1 如何将 Excel 文件导入到 Navicat for MySQL 数据库 Navicat for MySQL ...
- C语言基础 - 输出1-100万之间的素数
其实这个很简单 代码 网上也一大堆... //判断素数 BOOL isPrime(int num) { for (int i = 2; i <= sqrt(num); i++) { //能整除则 ...
- Object-C 里面的animation动画效果,核心动画
#import "CoreAnimationViewController.h" @interface CoreAnimationViewController ()@property ...
- EF 数据库迁移(Migration)
Update-Database -ConnectionStringName "MyConnectionString"
- Docker网络——单host网络
前言 前面总结了Docker基础以及Docker存储相关知识,今天来总结一下Docker单主机网络的相关知识.毋庸置疑,网络绝对是任何系统的核心,他在Docker中也占有重要的作用.同样本文基于Clo ...
- 简易 HTTP Server 实现(JAVA)
该简易的J2EE WEB容器缺失很多功能,却可以提供给大家学习HTTP容器大致流程. 注:容器功能很少,只供学习. 1. 支持静态内容与Servlet,不支持JSP 2. 仅支持304/404 3. ...