Zookeeper3.4.9分布式集群安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
二、文件准备
2.1 文件名称
zookeeper-3.4.9.tar.gz
2.2 下载地址
http://apache.fayea.com/zookeeper/
三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
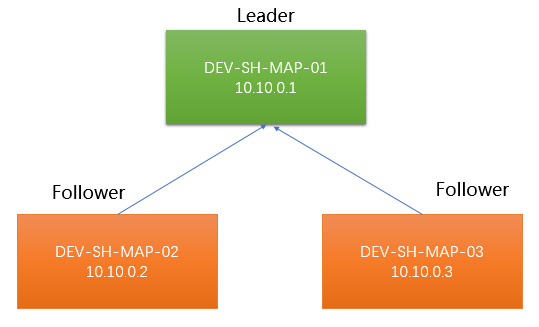
四、部署图
五、Zookeeper安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Zookeeper安装文件上传到Leader及两个Follower的/usr目录下
5.2 通过Xshell连接到虚拟机,在Leader及两个Follower上,执行如下命令,解压文件:
# tar zxvf zookeeper-3.4.9.tar.gz
5.3 在Leader上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Zookeeper Env
export ZOOKEEPER_HOME=/usr/zookeeper-3.4.9
export PATH=$PATH:$ZOOKEEPER_HOME/bin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Follower节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Follower节点上执行# source /etc/profile使其立即生效
六、Zookeeper配置
以下操作均在Leader节点,配置完后,使用scp命令,将配置文件拷贝到两个Follower节点即可。
6.1 zoo.cfg配置文件
切换到/usr/zookeeper-3.4.9/conf/目录下
将zoo_sample.cfg重命名为zoo.cfg
#mv zoo_sample.cfg zoo.cfg
使用vi编辑器,打开zoo.cfg,主要设置数据文件夹、日志文件夹以及通信、选举配置,如下红字所示:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/zookeeper-3.4.9/data
dataLogDir=/usr/zookeeper-3.4.9/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=DEV-SH-MAP-01:2888:3888
server.2=DEV-SH-MAP-02:2888:3888
server.3=DEV-SH-MAP-03:2888:3888
其中:
1)server.1 中的“1”可以是其他的数字或字符, 用来标识服务器,这个标识要写到前面设置的目录文件夹下的myid文件里
2)2888为Leader服务端口,3888为选举时所用的端口
拷贝配置文件到两个Follower节点:
在Leader节点,执行如下命令:
# scp zoo.cfg root@DEV-SH-MAP-02:/usr/zookeeper-3.4.9/conf/
# scp zoo.cfg root@DEV-SH-MAP-03:/usr/zookeeper-3.4.9/conf/
6.2 myid文件
切换到/usr/zookeeper-3.4.9/data目录下
执行命令:echo "1" > myid
注:如果是在Follower上执行,需要执行命令:
echo "2" > myid
或
echo "3" > myid
这里的2和3就是前面配置文件中设置的数字
七、Zookeeper使用
7.1 启动Zookeeper集群
分别在Leader及两个Follower上执行命令:
zkServer.sh start
7.2 查看Zookeeper状态
执行如下命令:
zkServer.sh status
7.3 停止Zookeeper
zkServer.sh stop
7.4 重启Zookeeper
zkServer.sh restart
Zookeeper3.4.9分布式集群安装的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- kafka2.9.2的伪分布式集群安装和demo(java api)测试
目录: 一.什么是kafka? 二.kafka的官方网站在哪里? 三.在哪里下载?需要哪些组件的支持? 四.如何安装? 五.FAQ 六.扩展阅读 一.什么是kafka? kafka是LinkedI ...
- Solr5.2.1+Zookeeper3.4.8分布式集群搭建
1.选取三台服务器 由于机器比较少,现将zookeeper和solr都部署在以下三台机器上.(以下操作都是在172.16.20.101主节点上进行的哦) 172.16.20.101 主节点 172.1 ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
随机推荐
- JAVA设计模式:装饰模式
前面我们学习了代理模式: 代理模式主要使用了java的多态,干活的是被代理类,代理类主要是接活,你让我干活,好,我交给幕后的类去干,你满意就成,那怎么知道被代理类能不能干呢?同根就成,大家知根知底,你 ...
- Pangolin的使用
Pangolin 是一个可用于SLAM可视化的openGL库.目前有很多SLAM系统都用它作为可视化的工具.它的编译与安装过程问题不大,依赖也比较少.但最近我在单独使用它的时候,碰到了很奇怪的现象:我 ...
- 【Scala】Scala之Methods
一.前言 前面学习了Scala的Class,下面接着学习Method(方法). 二.Method Scala的方法与Java的方法类似,都是添加至类中的行为,但是在具体的实现细节上差异很大,下面展示一 ...
- 关于input只能输入数字的两种小方法
第一种: 直接给input标签 name赋值如下 <input name="start_price" id="start_price" type=&quo ...
- 算法笔记_066:Kruskal算法详解(Java)
目录 1 问题描述 2 解决方案 2.1 构造最小生成树示例 2.2 伪码及时间效率分析 2.3 具体编码(最佳时间效率) 1 问题描述 何为Kruskal算法? 该算法功能:求取加权连通图的最小 ...
- 《Shell脚本学习指南》学习笔记之变量、判断和流程控制
变量 定义变量 可以使用export和readonly来设置变量,export用于修改或打印环境变量,readonly则使得变量不得修改.语法: export name[=word] ... read ...
- java 使用Stack来判断Valid Parentheses
假如定义形如"{}[]()"或者"{[()]}"的模式为valid,"[{]"或者"(("的模式为invalid,那么我 ...
- Macaca 自动化框架 [Python 系列]
介绍 Macaca是一套完整的自动化测试解决方案,基于node.js开发.由阿里巴巴公司开源: 地址:http://macacajs.github.io/macaca/ 特点: 同时支持PC端和移动端 ...
- 给 Qt 添加模块
添加 Qt 模块 QtCanvas3D 由于需要使用 Qt Quick 进行 3D 绘图,因此在网上找了一些资料. JS 绘制 3D 的有 ThreeJS 库,应该可以用于 QML.继续搜索,发现Qt ...
- 【SF】开源的.NET CORE 基础管理系统 - 安装篇
[SF]开源的.NET CORE 基础管理系统 -系列导航 1.开发必备工具 IDE:VS2017 运行环境:netcoreapp1.1 数据库:SQL Server 2012+ 2.获取最新源代码 ...