互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
上篇博文中,我们介绍了做互联网级监控系统的必备-Influxdb的关键特性、数据读写、应用场景:
本文中,我们介绍Influxdb数据库集群的搭建,同时分享一下我们使用集群遇到的坑!
一、环境准备
- 同一网段内,3个CentOS 节点,相互可以ping通
- 3个节点CentOS配置Hosts文件,相互可以解析主机名
- Azure 虚拟机启用root用户
- influxdb-0.10.3-1.x86_64.rpm
- 设置端口8083 8086 8088 8091例外
二、一步一步搭建Influxdb集群
1. 在各个节点的主机上配置Hosts文件,这样可以保证每个节点直接的互相通讯

2. 各个节点主机安装InfluxDB rpm,只是安装不启动Influxdb

3. 三个节点主机上依次 编辑Influxdb.conf文件(.etc/influxdb/influxdb.conf)
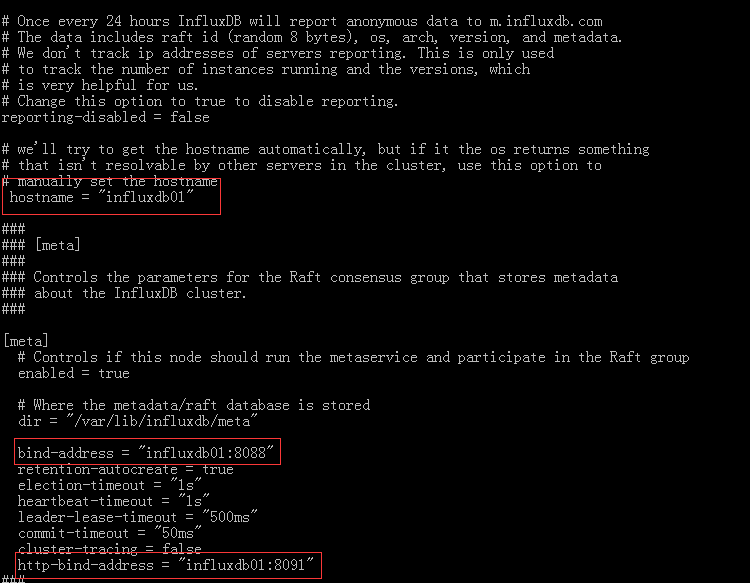
主要修改HostName、bind-address、http-bind-address三个选项
依次修改三个主机节点的配置文件
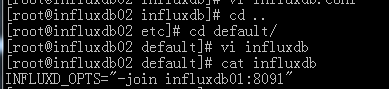
4. InfluxDB01机器上启动Influxdb



互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑的更多相关文章
- 互联网级监控系统必备-时序数据库之Influxdb
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- 互联网级监控系统必备-时序数据库之Influxdb技术
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级 Web 系统搭建:单机到分布式集群
本文内容 Web 负载均衡 HTTP 重定向 反向代理 IP 负载均衡 DNS 负载均衡 Web 系统缓存机制的建立和优化 MySQL 数据库内部缓存 搭建多台 MySQL 数据库 MySQL 数据库 ...
- 互联网企业级监控系统 OpenFalcon
Open-Falcon 人性化的互联网企业级监控系统,Open-Falcon 整体可以分为两部分,即绘图组件.告警组件.其中: 安装绘图组件 负责数据的采集.收集.存储.归档.采样.查询.展示(Das ...
- 认识Influxdb时序数据库及Influxdb基础命令操作
认识Influxdb时序数据库及Influxdb基础命令操作 一.什么是Influxdb,什么又是时序数据库 Influxdb是一个用于存储时间序列,事件和指标的开源数据库,由Go语言编写而成,无需外 ...
- Linux系统下安装Redis和Redis集群配置
Linux系统下安装Redis和Redis集群配置 一. 下载.安装.配置环境: 1.1.>官网下载地址: https://redis.io/download (本人下载的是3.2.8版本:re ...
随机推荐
- 开涛spring3(5.4) - Spring表达式语言 之 5.4在Bean定义中使用EL
5.4.1 xml风格的配置 SpEL支持在Bean定义时注入,默认使用“#{SpEL表达式}”表示,其中“#root”根对象默认可以认为是 ApplicationContext,只有Applica ...
- 开涛spring3(3.4) - DI 之 3.4 Bean的作用域
3.4 Bean的作用域 什么是作用域呢?即“scope”,在面向对象程序设计中一般指对象或变量之间的可见范围.而在Spring容器中是指其创建的Bean对象相对于其他Bean对象的请求可见范围. ...
- Virtualbox让kali虚拟机共享主机的无线网络连接
今天在测试虚拟机下安装kali系统时,遇到一个问题,默认安装完kali系统后,虚拟机不能上网.虚拟机网络配置使用的是默认的网络地址转换(NAT)选项. 网上查了很多,都说使用NAT模式时虚拟机不用做任 ...
- Java IO流之打印流与标准流
一.打印流 1.1打印流特点与构造方法 1)PrintStream和PrintWriter类都提供了一系列重载的print和println方法来输出各种类型的数据. 2)PrintStream和Pri ...
- 一位菜鸟的java 最基础笔记
java的特性 简单性(Simple). 结构体系中立(Architecture Neutral). 面向对象(Object Oriented). 易于移植(Portable). 分布式(Distri ...
- Linux获取UUID
Linux内核提供有UUID生成接口: cat /proc/sys/kernel/random/uuid Linux上一切皆文件,不管什么程序,读取文件就能获取一个UUID.
- java基础(二章)
java基础(二章) 一,变量 1.变量是内存中的一个标识符号,用于存储数据 2.变量命名规则 l 必须以字母.下划线 _ .美元符号 $ 开头 l 变量中,可以包括数字 l 变量中,不能出现特 ...
- awk内引用shell变量【自己手动加精】
题目 [root@localhost ~]# cat 1.txt iii sss ddd 执行命令 [root@localhost ~]# A=0 [root@localhost ~]# awk '{ ...
- 搭建rtmp直播流服务之3:java开发ffmpeg实现rtsp转rtmp并实现ffmpeg命令的接口化管理架构设计及代码实现
上一篇文章简单介绍了java如何调用ffmpeg的命令:http://blog.csdn.net/eguid_1/article/details/51777716 上上一篇介绍了nginx-rtmp服 ...
- jQuery之stop()
开启第一篇原创博客,内容朴实,但绝对属实. 先来看看w3c的定义和语法: 定义:stop() 方法停止当前正在运行的动画. 语法:$(selector).stop(stopAll,goToEnd) 参 ...