redis 一般性使用概述
最近一段时间与redis接触比较频繁。发现有些东西还是工作中经常会用到的,自己也花了点时间巩固下。本篇文章主要是以总结性的方式梳理,因为redis的主题很大,任何一个技术点展开都是几篇文章的量。也可以说这篇文章是个概览。
1.redis基本数据结构与短结构压缩
了解redis的数据结构有助于了解每种数据结构的优劣势,方便设计合理的cache结构。
1.1.redis提供5种数据结构
1.STRING:可以存储字符串、浮点型、整型,如果是字符串可以执行字符串操作,如果是浮点型、整型也可以执行加减操作。redis会识别出它的具体类型。
2.LIST:链表,链表中的每个NODE包含一个字符串。可以对链表进行两端推入、弹出操作。
3.SET:无序集合,不会存在相同的集合元素,集合的交集、并集、差集运算。
4.HASH:键值对的无需散列,增、删、获取键值。
5.ZSET:有序集合,根据一个浮点数分值来排序。
这几种数据类型用起来场景还是比较明显的,遇到复杂的cache场景我们需要结合这几种数据结构一起来设计。
比如,购物车场景,我们首先需要两个HASH来存储,第一个HASH是用户与购物车之间的关系,第二个HASH是购物车中的商品列表。
先通过userId获取到shoppingCartId,然后再通过shoppingCartId就可以获取到用户购物车的ProductIds。然后再通过ProductIds就可以异步读取用户购物车的商品信息。
通过userId获取shoppingCartId,再通过shoppingCartId获取ProductIds,这看似两个步骤可以在一个redis command中执行完成。(借助redis的pipeline管道。)
图1:
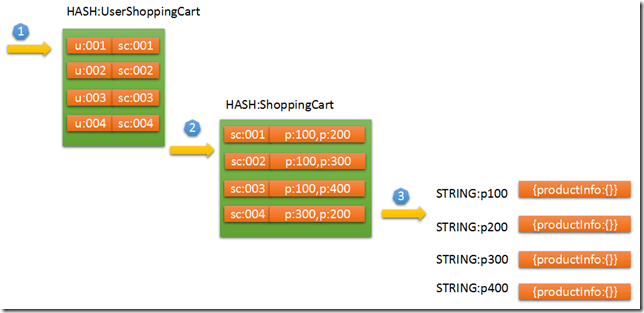
设计cache的时候,可以稍微综合的考虑下这几种结构,如果没有理想的结构再扩展下,将这几种结构混搭下可以满足复杂的cache结构。有一个平衡点就是过期时间的把握,集合没有办法设置具体item的过期时间,所以具体的数据对象还是需要设置expire,保证数据的新鲜度,比如,这里的STRING:p100商品。
1.2.压缩表与集合的整数集合编码
redis为列表、集合、散列、有序集合提供了压缩存储的方式,在存储数据不多的情况下用redis提供的短结构, 可以换来极大的存储压缩比。
redis的数据类型对应的短结构实现:list、zset、hash,这三个将使用ziplist,set使用集合整数编码。
默认的存储结构是以entry node 链表来存储数据的。然而,entry node 是一个结构化的存储。就拿list来说,entry node 前后包含了一个指针,形成双向链表,中间是包含的数据。数据节点包含三个部分,当前字符串所用空间,当前字符串所剩空间,当前字符串的值。
这些松散性的结构带来了一定的存储开销。redis提供了一个ziplist(压缩表)的功能,一旦开启压缩表那么原本用entry node的存储结构将使用序列化的字节序列来存储。这有优势也有劣势,优势就是存储空间少了,劣势就是不灵活了。存储空间少了,不仅带来空间利用率高,还有一个大的优势就是执行master\slave repliaction 或者BGSAVE的时候都是有好处,存储或者带宽都会消耗小。
set背后使用hash来保证不会存在重复的可以。当对set使用短结构存储的时候,redis将使用整数集合编码进行存储。
还有一点,如果我们设置的最大压缩限制超过之后redis将恢复entry node链表的是方式存储。因为,如果你的压缩表数据太多,读取或者修改就会很影响性能。可能需要对整个压缩列表进行解码、编码操作,等等。
2.redis 事务
redis 提供transaction 功能,你可以使用事务来处理一些数据一致性要求比较敏感的场景。redis的事务是没有所谓的隔离级别这一说的,性能是才是它追求的目的。事务所包含的所有command,是一个接着一个被执行,这执行结束之前其他客户端的所有请求都被block住。
使用redis事务比较简单,它有一个表示事务开始的命令 multi,然后使用exec提交。
有两点需要注意,在没有执行exec的时候所有在multi之后的命令都不会被执行。默认情况下,redis收到multi命令之后会将用户接下来的提交都暂时性的存放在一起queue里,直到接收到exec命令才会去执行queue里的所有命令。还有一点,有些redis客户端为了提高性能,会将multi与exec的所有命令都暂时存在redis客户端本地,然后一次性提交。这其实基于的是redis的pipeline 。
你也可以单独使用pipeline,而不使用multi、exec事务。只是为了减少redis key的传输次数而已。如果不会产生数据一致性问题是可以这么做的。
说到redis事务就不得不提redis事务的性能问题,所以现在结合redis来开发分布式事务来提供性能也是很常见的方案:https://github.com/Plen-wang/redis-lock 供参考。
3.redis两种持久化原理(RDB、AOF)
redis支持两种方式来持久化数据,第一种:snapshotting(镜像或快照)也称RDB、第二种:AOF(append-only file 文件追加)。
RDB:镜像模式就是将某个时间段的所有内存数据直接写入硬盘。
AOF:将执行的写命令增量复制到硬盘里面。
这两种其实就是不同的侧重,RDB是数据持久化,AOF是命令持久化,数据持久化比较直接,还原的时候直接恢复数据即可。命令持久化恢复的话需要执行一遍命令才行。
redis执行持久化操作取决于两方面:默认是根据持久化配置来执行,还有就是用户手动触发。手动触发有两个命令:
SAVE:会block所有的用户操作,知道持久化结束。
BGSAVE:后台子进程执行,linux中使用fork命令开启一个子进程副本,这个子进程副本与主进程共用一套内存空间,直到主进程或子进程对内存进行修改,被修改之后的内存区域将被子进程复制出来单独使用。
RDB持久化的问题是会存在丢失数据的可能,AOF持久化最多丢失一秒内的命令。所以持久化结合这两种来执行会在数据完整性和性能之间取的平衡。
4.redis 主从复制的基本原理
redis提供复制功能,这有很多好处。容灾、扩展读写性能。
有两个点需要注意:从服务器一旦进行同步数据时会清空自己的所有数据。redis不支持主主复制。
复制过程大致如下:
1.从服务器连接主服务器,发送SYNC命令。
2.主服务器执行BGSAVE,并使用缓存区记录BGSAVE之后执行的所有写命令。
3.BGSAVE执行完毕之后,向从服务器发送快照文件。从节点丢弃所有本实例数据。载入主服务器发送过来的快照数据。
4.快照发送完毕之后开始发送缓存区中的写命令。从节点开始向常规的操作一样执行增量复制。
5.开始进入常规的复制操作。
有个问题需要分享下,redis一旦占用的内存哪怕我们清楚了key,这部分内存还是无法还给操作系统的,这是redis的设计策略。虽然从redis info命令中查看的内存大小是没用占用的,但是操作系统无法使用这部分内存。
还有个问题,所有redis服务器如果要被复制数据,也就是要执行BGSAVE,那么至少需要保留30%-45%的空余内存。因为BGSAVE执行的时候可能需要copy key出来,如果这个时候写命令过多还需要给缓存区留有点空间。
5.redis 扩展读性能
有了主从复制功能之后实际上扩展读性能是比较容易的。利用主从链,将同步操作分派给同步节点,这样主节点就可以专门只负责写命令处理。
图2:

复制节点专门处理复制功能,最下游的读节点专门来接受读请求。如果考虑主节点宕机问题,可以开启复制节点的持久化功能,或者开启读节点的部分节点也行。主要是为了防止宕机可以快速恢复master。如果是异地双活,可以把左右两边的所有读节点开启持久化,左边一个机房,右边一个机房,既可以双活也可以恢复。(实际情况没有这么简单,只是个思路)
读节点是不能够执行写入命令的,这个才能保证将来的数据复制。
6.redis HA方案(sentinel)
redis 的高可用方案基于自己的一套sentinel 集群来管理。
图3:
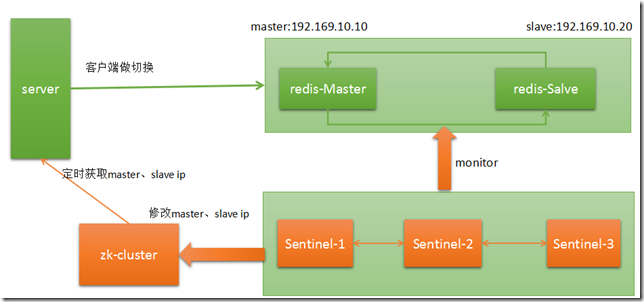
sentinel cluster 保持对redis集群的监控,如果sentinel-1发现master在某个时间段内没有响应ping命令,就主观断定是可能宕机了。sentinel-2、sentinel-3如果都发现master是无响应的,那么三个投票断定master是客观宕机了,做一次master、slave切换。同时会通过sentinel-sh脚本进行一些通知操作。
当然,redis-HA方案有好几种,我们也可以用keepalived、VIP来实现,将master、backup、slave分离开来,master、backup自动VIP切换。
redis 一般性使用概述的更多相关文章
- 峰Redis学习(9)Redis 集群(概述)
第一节:Redis 集群概述 redis cluster是去中心化,去中间件的,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态.每个节点都和其他所有节点 ...
- redis之sentinel概述
一.配置sentinel 修改的是这条: 对应: 上面那条配置需要注意:<master-name>:监控主节点的名称 <ip>:监控主节点的ip <redis-por ...
- Redis数据库 01概述| 五大数据类型
1.NoSQL数据库简介 解决应用服务器的CPU和内存压力:解决数据库服务的IO压力: ----->>> ① session存在缓存数据库(完全在内存里),速度快且数据结构简单: 打 ...
- Redis集群概述
Redis Cluster与Redis3.0.0同时发布,以此结束了Redis无官方集群方案的时代,目前,Redis已经发布了3.0.7版本. redis cluster是去中心化,去中间件的,也就是 ...
- Redis系列1——概述
1. 简介 Redis,key-value内存存储的数据库,全称“”Remote Dictionary Service(Sever)“”,默认端口号:6379 Redis是一个开源的使用ANSI C语 ...
- Redis之datatype概述
Redis支持的数据类型 String List Set Sorted Set Hashes Bit array HyperLogLog Bina ...
- Redis底层结构概述
可以使用 object encoding <key> 查看使用的具体数据结构 原图链接
- Redis复制与可扩展集群搭建
抄自:http://www.infoq.com/cn/articles/tq-redis-copy-build-scalable-cluster 讨论了Redis的常用数据类型与存储机制,本文会讨论一 ...
- 【转载】Redis多实例及分区
主要看的这篇文章 http://mt.sohu.com/20160523/n451048025.shtml edis Partitioning即Redis分区,简单的说就是将数据分布到不同的redis ...
随机推荐
- 模拟jquery底层链式编程
//特点1:快级作用域,程序启动自动执行 //内部的成员变量,外部无法访问(除了var) //简单的函数链式调用 function Dog(){ this.run=function(){ alert( ...
- 带着问题写React Native原生控件--Android视频直播控件
最近在做的采用React Native项目有一个需求,视频直播与直播流播放同一个布局中,带着问题去思考如何实现,能更容易找到问题关键点,下面分析这个控件解决方法: 现在条件:视频播放控件(开源的ijk ...
- javascript基础(幼兔、小兔成兔数量等典型例题)
一张纸的厚度是0.0001米,将纸对折,对折多少次厚度超过珠峰高度8848米var sum=0; var a=0.0001 for(var i=0;i<100;i++){ a=a*2; sum= ...
- Linux命令 用户管理命令
groupadd [功能说明] 新建用户组 [语法格式] Groupadd[-f][-r][-g<GID><-o>][组名] [选项参数] 参数 说明 -f 建立已存在的组,强 ...
- javaScript的一些奇妙动画
今天我给大家讲一下JavaScript中的显示隐藏.淡入淡出的效果 显示与隐藏动画效果 show()方法: show()方法会动态地改变当前元素的高度.宽度和不透明度,最终显示当前元素,此时 ...
- html中p标签行间距的问题
使用CSS行高样式line-height可以设置调整p行间距,但是同时会影响每行文字间的上下间距,所以使用line-height虽然可以用来设置html p 行距离间隔,但是不是很实用,一般line- ...
- 记一次使用搬瓦工VPS的经历
自己因为有需求上Google,以前是通过修改hosts的方法实现访问Google,但是最近不知道为什么改hosts后还是无法访问Google,于是决定搭建VPS来实现科学上网,看了一下价格,作为穷逼学 ...
- Visual Studio Debugger中七个鲜为人知的小功能
Visual Studio debugger是一个很棒的调试工具,可以帮助程序猿们快速地发现和解决问题.这里给大家简单介绍一下VS调试工具中的七个鲜为人知的小功能. 1. 一键跳转到指定语句 调 ...
- 使用javac编译zookeeper项目
这里记录zookeeper编译源代码上的一些细节的问题. 网上不少关于如何使用ant eclipse来构建zookeeper对应的eclipse工程的记录.这里就不再过多赘述.只做简单阐述. 这里主要 ...
- JAVA基础——数组详解
学习JAVA中数组的使用 一.什么是数组? 问:编写代码保存 4 名学生的考试成绩. 答:简单啊,定义 4 个变量呗 问:那"计算全年级 400 名学生的考试成绩",肿么办 答: ...