cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习
监督学习有数据有标签,目的是学习数据和标签之间的映射关系。而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构。
2. 生成模型(Generative Models)
已知训练数据,根据训练数据的分布(distribution)生成新的样例。
无监督学习中的一个核心问题是估计分布。
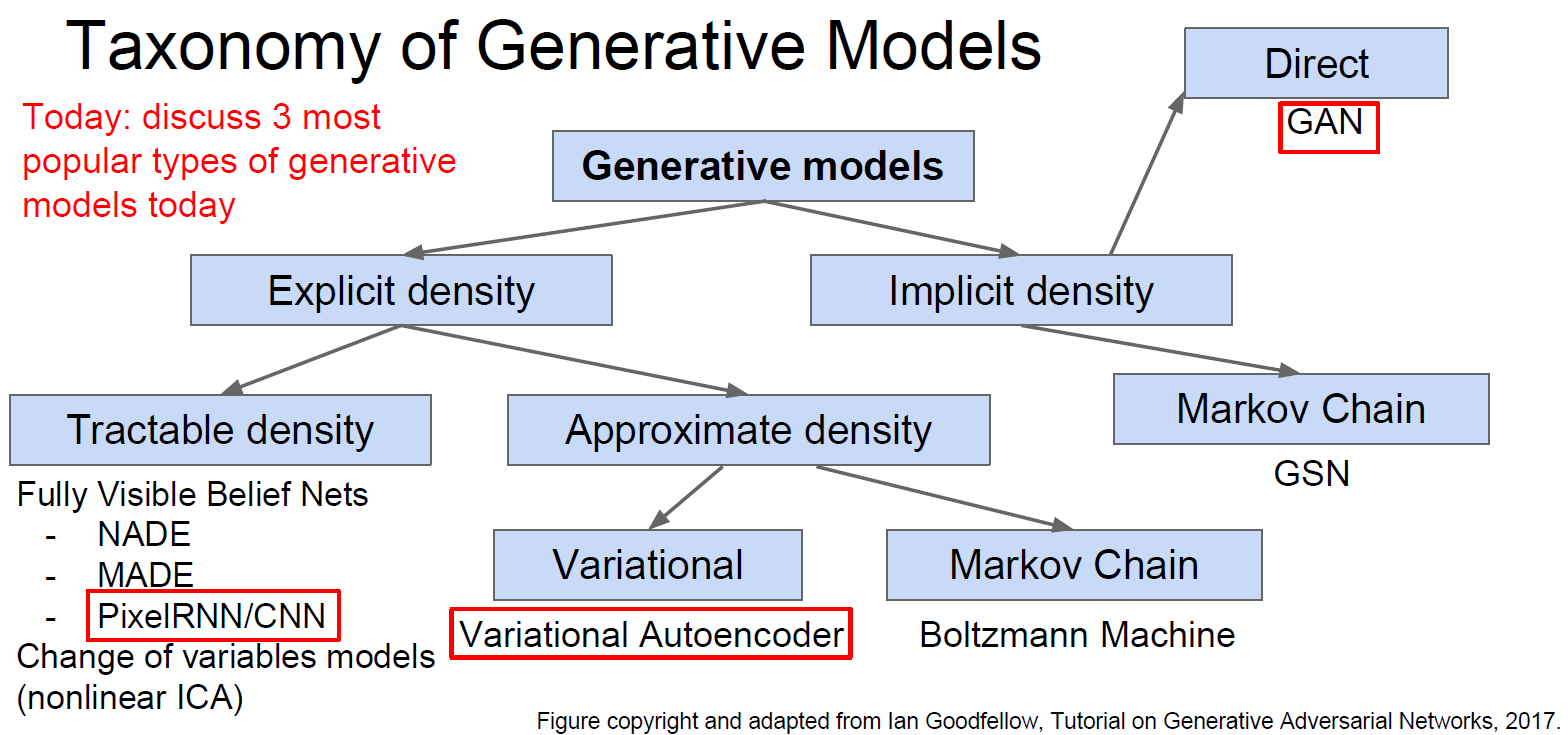
3. PixelRNN 和 PixelCNN
依次根据已知的像素估计下一个像素。

PixelRNN(van der Oord et al. NIPS 2016):利用RNN(LSTM)从角落开始依次生成像素。缺点是非常慢。

PixelCNN(van der Oord et al. NIPS 2016):利用CNN从角落开始依次生成像素。求像素的最大似然估计。比PixelRNN快,但依旧慢。
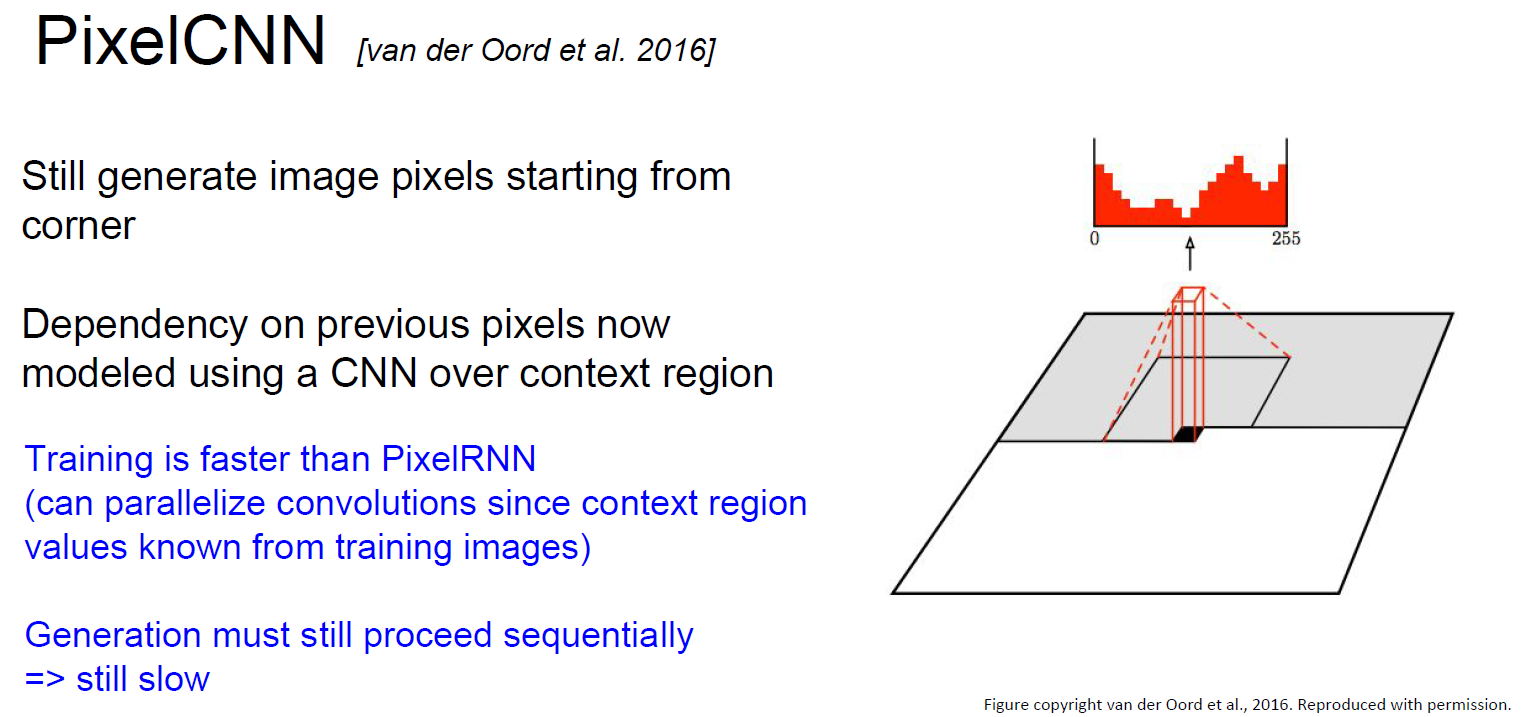
PixelRNN和PixelCNN的优点是可以显式地求出概率分布,并且给出评价尺度(evaluation metric),生成的结果也不错。缺点是慢。改进版本是PixelCNN++(Salimans et al. 2017)。
4. Variational Autoencoders (VAE)
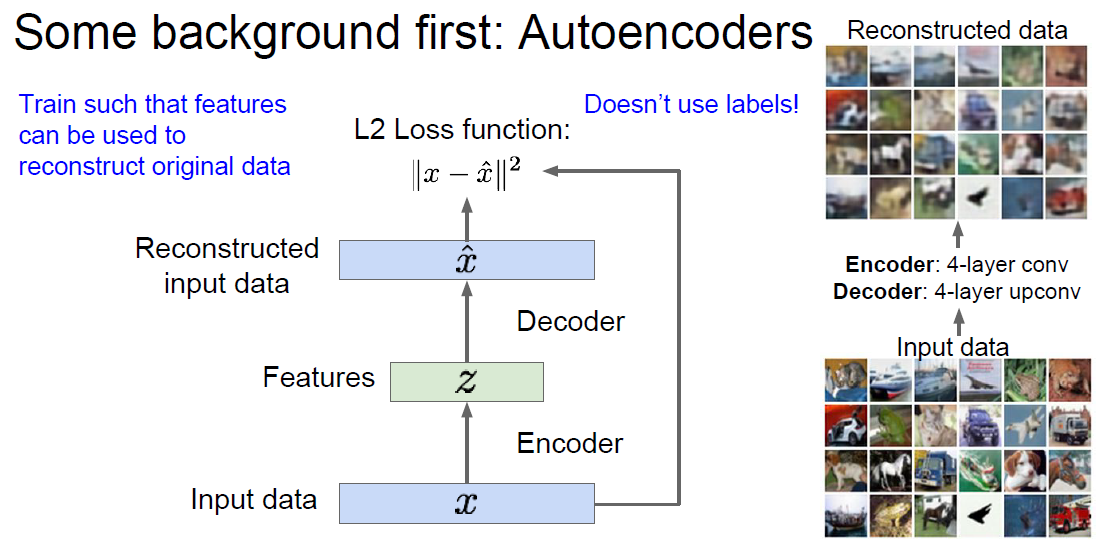
Autoencoder是一种从没有标签的训练数据学习低维度特征(lower-dimensional feature representation)的方法。最开始是用Linear+nonlinearity(sigmoid)的方法,后来人们用深度的全连接层,再后来人们用ReLU CNN。为什么要“低维度特征”?或者说为什么把输入的维度降低?目的是为了获得可靠的、不变的特征。
第一种用法是和监督学习配合使用。在训练阶段,可以再用一个Decoder把低维度特征解码成和输入类似的数据。这样可以建立损失函数。训练完成之后可以把Decoder扔掉,把Encoder出的特征当成某个监督学习的输入,预测出结果,建立Loss function。在有大量没有标签的训练数据和少量有标签的数据的情况下,这样做很有效。图中的 z 叫 “latent factors”。
第二种用法是生成新的数据。对于编码出的 z(“latent factors” )的分布 p(z),可以直接选择简单的概率分布,比如高斯。而对于条件概率 p(x|z),则是比较复杂的,用神经网络来模拟。训练的过程如下图所示,(推导过程完全没听懂。。。)。训练完了之后可以只用Decoder network,渐进地改变z的各个分量(比如z1表示微笑的程度,z2表示头的姿态,则可以生成各种头的姿态各种微笑程度的人脸),生成不同的样例x_hat。
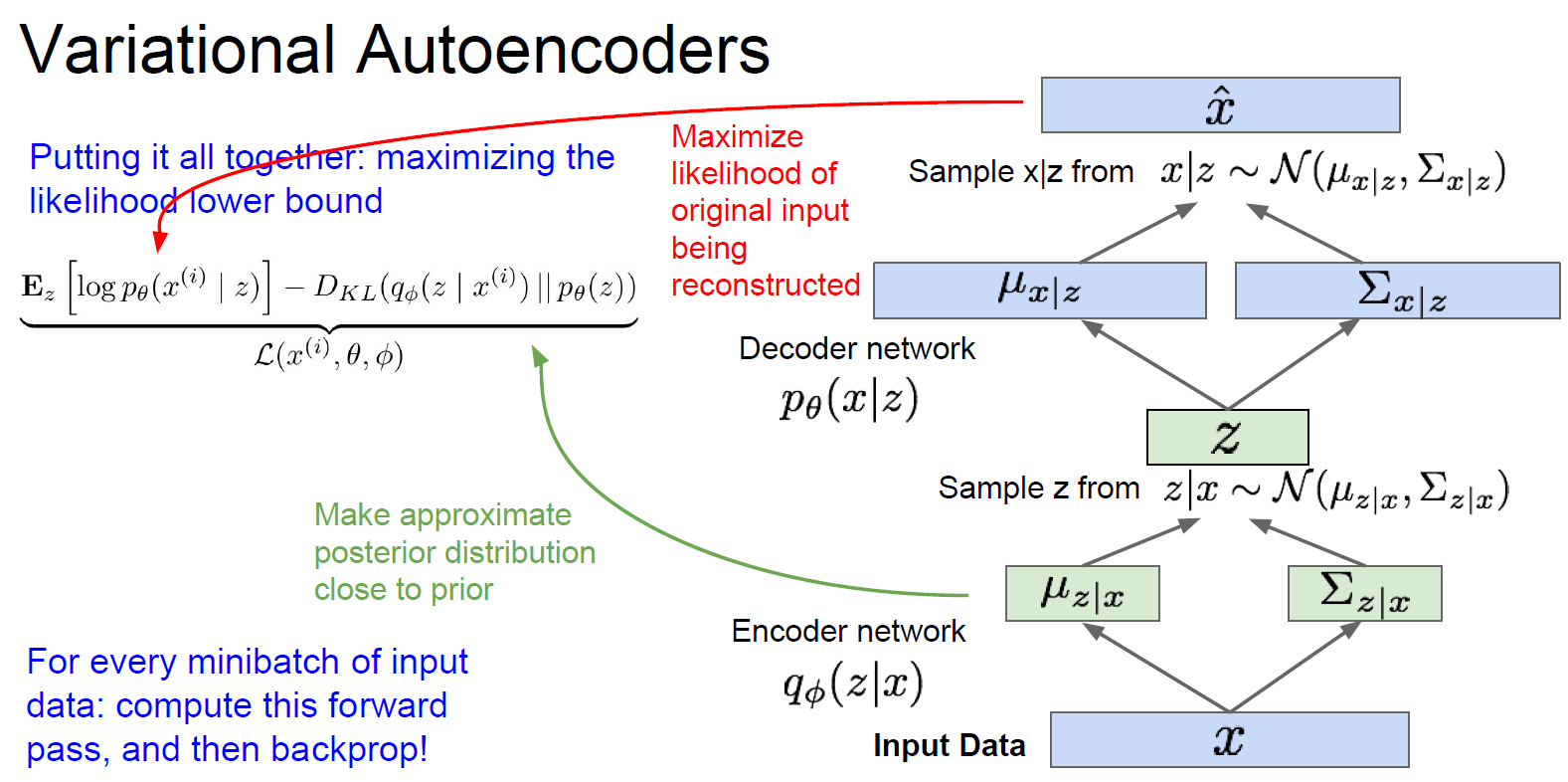
Variational Autoencoders的优点:生成模型的主要方法(principled approach);可以估计q(z|x)(没搞明白这里q是什么。。。),对于其他任务可能是很好的特征描述。缺点:最大化似然估计的下限,而不是直接最大化似然估计,从评估的角度说不如PixelRNN和PixelCNN;相比于GAN,生成的图片比较模糊,质量不高。
5. Generative Adversarial Networks (GAN) (Ian Goodfellow et al., "Generative Adersarial Nets", NIPS 2014)
不考虑显式地描述density function,而是根据对抗直接生成样例。我们没有办法直接从复杂的、高维度的训练集分布中生成样例,那么就先从简单的分布生成样例(比如随机噪音),然后从训练集分布学习把这个简单分布生成的样例转变成(transformation)符合训练集分布。神经网络就是用来描述这个复杂的transformation(神经网络的作用似乎一直就是用来描述高维度、非线性的某种函数、映射、转换等等)。该神经网络的输入是随机噪声,输出是符合训练集分布的样例。
GAN有两个网络,生成网络(generator network)和区分网络(discriminator network),生成网络尽一切努力生成图片欺骗区分网络,区分网络尽一切努力区分原图和生成的图。

具体的训练过程是先优化区分网络k次迭代,再优化生成网络一次迭代,然后不断重复。

训练完成之后,可以丢掉区分网络,只用生成网络来生成样例。
改进方案如下:

2017年是GAN的爆发年,出了成吨的相关研究。生成的样例越来越好。
GAN的优点:效果非常好。缺点:训练的过程不稳定,很需要经验和技巧;不能给出对得density function的估计。
6. 总结:生成模型的对比
PixelRNN和PixelCNN:显式的density model,优化似然函数,效果不错,低效、慢。
Variational autoencoders (VAE):优化似然函数的下限,latent representation很有用,inference queries,生成的图片的质量不够好。
Generative Adversarial Network (GANs):博弈的原理,生成的图片的质量超级好,难训练,no inference queries。
cs231n spring 2017 lecture13 Generative Models 听课笔记的更多相关文章
- cs231n spring 2017 lecture13 Generative Models
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- cs231n spring 2017 lecture9 CNN Architectures 听课笔记
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture14 Reinforcement Learning 听课笔记
(没太听明白,下次重新听) 1. 增强学习 有一个 Agent 和 Environment 交互.在 t 时刻,Agent 获知状态是 st,做出动作是 at:Environment 一方面给出 Re ...
- cs231n spring 2017 lecture2 Image Classification 听课笔记
1. 相比于传统的人工提取特征(边.角等),深度学习是一种Data-Driven Approach.深度学习有统一的框架,喂不同的数据集,可以训练识别不同的物体.而人工提取特征的方式很脆弱,换一个物体 ...
- cs231n spring 2017 lecture9 CNN Architectures
参考<deeplearning.ai 卷积神经网络 Week 2 听课笔记>. 1. AlexNet(Krizhevsky et al. 2012),8层网络. 学会计算每一层的输出的sh ...
- cs231n spring 2017 lecture11 Detection and Segmentation 听课笔记
1. Semantic Segmentation 把每个像素分类到某个语义. 为了减少运算量,会先降采样再升采样.降采样一般用池化层,升采样有各种"Unpooling"." ...
- cs231n spring 2017 lecture7 Training Neural Networks II 听课笔记
1. 优化: 1.1 随机梯度下降法(Stochasitc Gradient Decent, SGD)的问题: 1)对于condition number(Hessian矩阵最大和最小的奇异值的比值)很 ...
- cs231n spring 2017 lecture16 Adversarial Examples and Adversarial Training 听课笔记
(没太听明白,以后再听) 1. 如何欺骗神经网络? 这部分研究最开始是想探究神经网络到底是如何工作的.结果人们意外的发现,可以只改变原图一点点,人眼根本看不出变化,但是神经网络会给出完全不同的答案.比 ...
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记
1. 深度学习面临的问题: 1)模型越来越大,很难在移动端部署,也很难网络更新. 2)训练时间越来越长,限制了研究人员的产量. 3)耗能太多,硬件成本昂贵. 解决的方法:联合设计算法和硬件. 计算硬件 ...
随机推荐
- JaveScript运算符(JS知识点归纳三)
JaveScript中有许多的运算符,在这里就只说明一些需要注意的. 01 一元运算符 一元:指的是参与运算的操作数只有一个 最经常使用的是++ -- 计算规则: ++/-- 前置于操作数的时候 ...
- JavaScript:AOP实现
AOP的概念,使用过Spring的人应该都不陌生了.Dojo中,也是支持AOP的.对于JavaScript的其他框架.库不知道有没有AOP的支持.相信即便没有支持,也不会太远了.下面就介绍一下使用Ja ...
- 455. Assign Cookies.md
Assume you are an awesome parent and want to give your children some cookies. But, you should give e ...
- uptime 命令详解
作用: 打印系统总共运行了多长时间和系统的平均负载. uptime 命令可以显示的信息依次为: 现在时间, 系统已经运行时间, 目前登录用户个数, 系统1,5,15 分钟内的平均负载 实例: up ...
- flex基础示例
flex的一些基础用法: <!-- Flex布局已经得到了所有浏览器的支持:chrome21+.Opera12.1+.Firefox22+.safari6.1+.IE10+ Webkit内核浏览 ...
- 保存html上传文件过程中遇到的字节流和字符流问题总结
java字节流和字符流的区别以及相同 1. 字节流文件本身进行操作,字符流是通过缓存进行操作, 1.1 使用字节流不执行关闭操作 File f =new File("d:/test/test ...
- Keep Mind Working
想找一个这样的地方,可以让脑袋持续运转着.不会像游戏一样让人着迷,不会像有色电视一样让人想错地方,也不会像工作一样充满太多严密.就是让脑袋继续转着,适意地思考些什么. 之前会跑去游戏里,至少没有太污. ...
- Linux下Tomcat重新启动,及kill命令的使用
Linux下Tomcat重新启动,及kill命令的使用 首先,进入Tomcat下的bin目录 cd /usr/local/tomcat/bin 使用Tomcat关闭命令 ./shutdown.sh 查 ...
- TypeScript VS JavaScript 深度对比
TypeScript 和 JavaScript 是目前项目开发中较为流行的两种脚本语言,我们已经熟知 TypeScript 是 JavaScript 的一个超集,但是 TypeScript 与 Jav ...
- MicroPython-GPRS教程之TPYBoardv702GPRS功能测试
一.什么是TPYBoardV702 TPYBoardV702是目前市面上唯一支持通信通信功能的MicroPython开发板:支持Python3.0及以上版本直接运行.支持GPS+北斗双模通信.GPRS ...