sqlser 2005 使用执行计划来优化你的sql
一:sqlserver 执行计划介绍
sqlserver 执行计是在sqlser manager studio 工具中打开,是检查一条sql执行效率的工具。建议配合SET STATISTICS IO ON等语句来一起使用,执行计划是从右向左看,耗时高的一般显示在右边,我们知道,sqlserver 查询数据库的方式为:
1:表扫描(table scan) 查询速度最慢.
2:聚集索引扫描(Clustered Index Scan),按聚集索引逐行进行查询,效率比表扫描高,但速度还是慢.
3:索引扫描(index scan)效率比聚集索引快,根据索引滤出部分数据在进行逐行检查。
4;索引查找(index seek) 效率比索引扫描还要快,根据索引定位记录所在位置再取出记录.
5:聚集索引查找(Clustered Index Seek) 效率最快,直接根据聚集索引获取记录。
当发现某个查询比较慢时,可以首先检查哪些操作的成本比较高,再看看那些操作在查找记录时, 是不是【Table Scan】或者【Clustered Index Scan】,如果确实和这二种操作类型有关,则要考虑增加索引来解决了,sqlser 索引有两种,聚集索引和非聚集索引,聚集索引是一张表只能有一个,比如id,非聚集索引可以有多个,聚集索引是顺序排列的类似于字典查找拼音a、b、c……和字典文字内容顺序是相同的,非聚集索引与内容是非顺序排列的,类似字典偏旁查找时,同一个偏旁‘王’的汉字可能一个在第1页一个在第5页。
二:创建测试表
create table shopping_user(uId bigint primary key,uName varchar(10));
create table shopping_goods_category(cId bigint primary key,cName varchar(20));
create table shopping_goods(gId bigint primary key,gName varchar(50),gcId bigint,gPrice int);
create table shopping_order(oId bigint primary key,oUserId bigint,oAddTime datetime,oGoodsId bigint,oMoney int);
创建测试sql
declare @index int;
set @index = 1;
while(@index<=10)
begin
insert into shopping_user (uId,uName) values(@index,'user'+cast(@index as varchar(10)));
set @index = @index+1;
end; insert into shopping_goods_category (cid,cName) values(1,'水果');
insert into shopping_goods_category (cid,cName) values( 2,'电脑');
insert into shopping_goods_category (cid,cName) values (3,'手机');
insert into shopping_goods_category (cid,cName) values (4,'服装');
insert into shopping_goods_category (cid,cName) values (5,'食品'); ------ 商品表sql declare @index int;
declare @num int;
set @index = 1;
set @num = 10000;
begin
while(@index<=100*@num)
begin
if @index<=10*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,1,'水果'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >10*@num and @index <=20*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,1,'水果'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >20*@num and @index <=30*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,2,'电脑'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >30*@num and @index <=40*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,2,'电脑'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >40*@num and @index <=50*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,3,'手机'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >50*@num and @index <=60*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,3,'手机'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >60*@num and @index <=70*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,4,'服装'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >70*@num and @index <=80*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,4,'服装'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >80*@num and @index <=90*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,5,'食品'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
else if @index >90*@num and @index <=100*@num
begin
insert into shopping_goods (gId,gcId,gName,gPrice)
values (@index,5,'食品'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) );
end;
set @index = @index+1;
end;
end; ------- 订单表sql declare @index int;
declare @num int;
declare @timeNum int;
declare @userId int;
declare @goodsId int;
declare @money int;
declare @addTime varchar(30);
set @index = 1;
set @num = 10000;
set @timeNum = 0;
set @userId = 1;
set @goodsid = 1;
set @money = 100;
set @addTime = '';
begin
while(@index<=100*@num)
begin
set @timeNum = cast( floor(rand()*30)+1 as int)
set @userId = cast( floor(rand()*99)+1 as int)
set @money = cast ( floor(rand()*5000)+@userId as int)
set @addTime = dateadd(day,@timeNum,getdate())
set @goodsId = cast( floor(rand()*999999)+1 as int)
if @index<=10*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >10*@num and @index <=20*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >20*@num and @index <=30*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >30*@num and @index <=40*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >40*@num and @index <=50*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >50*@num and @index <=60*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >60*@num and @index <=70*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >70*@num and @index <=80*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >80*@num and @index <=90*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end;
else if @index >90*@num and @index <=100*@num
begin
insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney)
values (@index,@userId,@addTime,@goodsId,@money );
end; set @index = @index+1;
end; end;
创建索引
create index gcid_index on shopping_goods (gcid);
create index userid_index on shopping_order(ouserid);
create index goodsid_index on shopping_order(ogoodsid);
三:执行计划分析
这里使用上一篇文章sql语句百万数据量优化方案中提到的,in和exists来分析,sql语句如下:
SET STATISTICS IO ON select top 20 * from shopping_order where exists (
select top 10 gid from shopping_goods where gcid =2 and ogoodsid = gid order by gprice desc) select top 20 * from shopping_order where goodsid in (
select top 10 gid from shopping_goods where gcid =2 order by gprice desc) -- DBCC DROPCLEANBUFFERS
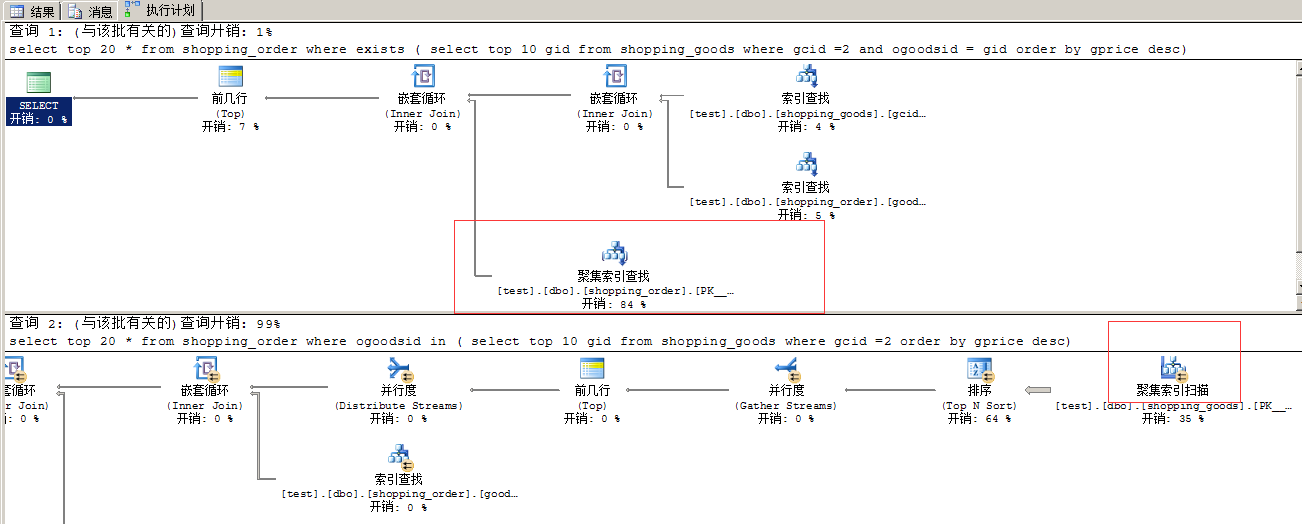
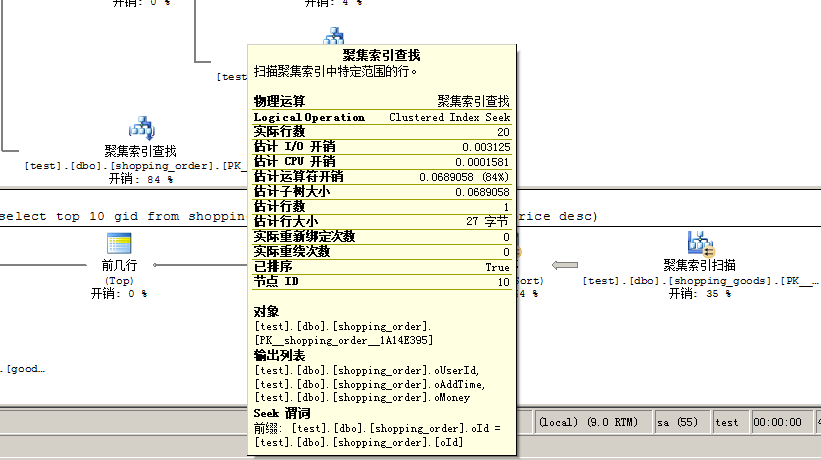
从上图中发现,使用exists,开销最大的是,使用聚集索引查找,而使用in,第一次操作(从右各左看),就使用了聚集索引扫描,in的效果明显差。我们再来看聚集索引查找结果,聚集索引返回的行数是20,见下图.
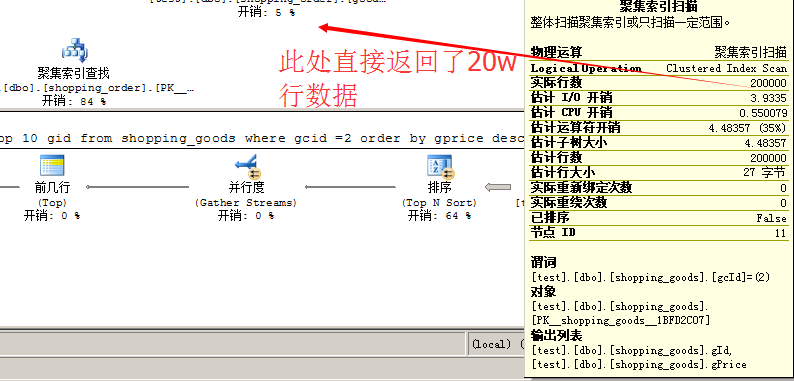
然后我们来看使用in查询,聚集索引扫描,查询结果却是20w
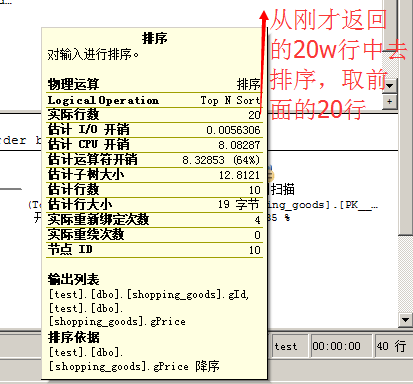
接着我们来看使用in查询,第二个开销大的排序,从刚才查询出来的20w数据中,order by desc 返回前20条数据。
此处我们还可以使用SET STATISTICS IO ON来查询这两者的io开销:
扫描计数:执行的扫描次数;
逻辑读取:从数据缓存读取的页数;
物理读取:从磁盘读取的页数;
预读:为进行查询而放入缓存的页数
重要:如果对于一个SQL查询有多种写法,那么这四个值中的逻辑读(logical reads)决定了哪个是最优化的。

从上图中发现,exists查询:shopping_order表扫描次数是2,逻辑读取是80,shopping_goods表,扫描次数是1,逻辑读取是6次,
而in shopping_order表扫描次数是2,逻辑读取是55,shopping_goods表,扫描次数是5,逻辑读取是5247次,当然工作中的sql肯定要复杂得多,但我们可以借助这个工具来找到需要优化的sql,当然这也只是执行计划,可能实际执行的效率和这个计划有出入,但我们还是可以借鉴执行计划来找到其中的不足。
sqlser 2005 使用执行计划来优化你的sql的更多相关文章
- db2数据库创建索引,删除索引,查看表索引,SQL语句执行计划以及优化建议
1.建立表索引 create index 索引名 on 表名(列名,列名); 2.删除表索引 drop index 索引名 on 表名; 3.查看表索引 select * from sysibm.sy ...
- 转://利用从awr中查找好的执行计划来优化SQL
原文地址:http://blog.csdn.net/zengxuewen2045/article/details/53495613 同事反应系统慢,看下是不是有锁了,登入数据库检查,没有异常锁定,但发 ...
- 分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分 ...
- Oracle 课程五之优化器和执行计划
课程目标 完成本课程的学习后,您应该能够: •优化器的作用 •优化器的类型 •优化器的优化步骤 •扫描的基本类型 •表连接的执行计划 •其他运算方式的执行计划 •如何看执行计划顺序 •如何获取执行计划 ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- Oracle性能优化之Oracle里的执行计划
一.执行计划 执行计划是目标SQL在oracle数据库中具体的执行步骤,oracle用来执行目标SQL语句的具体执行步骤的组合被称为执行计划. 二.如何查看oracle数据库的执行计划 oracle数 ...
- 基于Oracle的SQL优化(崔华著)-整理笔记-第2章“Oracle里的执行计划”
详细介绍了Oracle数据里与执行计划有关的各个方面的内容,包括执行计划的含义,加何查看执行计划,如何得到目标SQL真实的执行计划,如何查看执行计划的执行顺序,Oracle数据库里各种常见的执行计划的 ...
- mysql之优化器、执行计划、简单优化
mysql之优化器.执行计划.简单优化 2018-12-12 15:11 烟雨楼人 阅读(794) 评论(0) 编辑 收藏 引用连接: https://blog.csdn.net/DrDanger/a ...
- Oracle之SQL优化专题02-稳固SQL执行计划的方法
首先构建一个简单的测试用例来实际演示: create table emp as select * from scott.emp; create table dept as select * from ...
随机推荐
- 字符函数 php
strrchr( '123456789.xls' , '.' ); //程序从后面开始查找 '.' 的位置,并返回从 '.' 开始到字符串结尾的所有字符
- .NET Core工程编译事件$(TargetDir)变量为空引发的思考
前言 最近客户反馈,为啥不用xcopy命令代替我自己写的命令来完成插件编译复制: 我的: <PostBuildEvent>call "$(SolutionDir)tools\to ...
- ASP.NET Core 认证与授权[5]:初识授权
经过前面几章的姗姗学步,我们了解了在 ASP.NET Core 中是如何认证的,终于来到了授权阶段.在认证阶段我们通过用户令牌获取到用户的Claims,而授权便是对这些的Claims的验证,如:是否拥 ...
- spring各个版本开发包下载
spring各个开发包版本下载地址:https://repo.spring.io/webapp/#/artifacts/browse/tree/General/libs-release-local/o ...
- 【Java疑难杂症】有return的情况下try catch finally的执行顺序
有这样一个问题,异常处理大家应该都不陌生,类似如下代码: public class Test { public static void main(String[] args) { int d1 = 0 ...
- 但未在用户代码中进行处理 具有固定名称“Oracle.ManagedDataAccess.Client”的 ADO.NET 提供程序未在计算机或应用程序配置文件中注册或无法加载。
这是使用ODP.NET链接Orcl数据库常见错误,需要配置系统环境变量. 解决方法如下: 找到以下路径文件:C:\Windows\Microsoft.NET\Framework\v4.0.30319\ ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(88)-Excel导入和导出-自定义表模导出
前言 之前说了导入和导出,也提供了自定义的表模的导入,可见LinqToExcel可以做的事情不仅仅如此 这次我们来演示比较复杂的导出Excel,导出复杂的Excel与导入复杂的Excel原理基本是一样 ...
- “战术竞技类”外挂打击已开始!揭秘腾讯We Test游戏安全服务新动作!
商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. 原文链接:http://wetest.qq.com/lab/view/353.html We Test导读 国服PUBG的游戏安全将由我 ...
- 基于MVC设计模式的Web应用框架:struts2的简单搭建(一)
Struts2的初步介绍 Struts2是apache项目下的一个web 框架,普遍应用于阿里巴巴.京东等互联网.政府.企业门户网站.虽然之前存在了很大的安全漏洞,在2013年让苹果.中国移动.中国联 ...
- 如何使用MFC连接Access数据库
(1)新建一个Access数据库文件.将其命名为data.mdb,并创建好表.字段. (2)为系统添加数据源.打开“控制面板”—>“管理工具”—>“数据源”,选择“系统DSN”,点击右边的 ...