Kaggle实战之二分类问题
0. 前言
- “尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题。”
- 本系列参考书 "Hands-on machine learning with scikit-learn and tensorflow"以及kaggle相关资料
1. MNIST 数据集
MNIST是最常用的用来实验分类模型的数据集,有7w多张手写0-9的白底黑字数字图像,每张图像大小 28*28,共784个像素,像素取值范围为[0-255],0表示白色背景,255表示纯黑,如下图:

2. 二分类器
数字识别是个多分类问题,首先我们从两分类问题开始入手,即判断一张图片是5或者非5。应用sklearn线性模型的SGDClassifier直接训练,损失函数默认是 hinge loss,即SVM分类器,如果想用logistic regression来分类,可以选用 log loss。SGDClassifier 分类器还支持不同的损失函数,如 perceptron等,这里就不一一列举了。由于SGD分类器对训练样本的顺序是敏感的,所以在模型训练之前需要shuffle训练集。
用SVM训练结束后,用模型预测得到测试集的预测结果,评估准确率(accuracy)大概是96%,看起来是一个不错的结果,但是如果我们把所有的测试样本都判定为非5,准确率也能有90%(十分之九都是对的)。看来光凭准确率,在这种情况下不能说明我们模型学习得很好,看来如何评价模型的学习能力不是件那么简单的事情。
3. 效果评测
从源头出发,如下图,x、o分别表示label为负和正的样本,划分为上下两列,假设模型预测值是一个连续值(如为正的概率),把正负样本按照预测值从低到高分别排列好。一个好的模型,应该是左上角分布较密集,表示很多负样本预测值较小,右下角分布也很密集,表示为模型预测正样本的概率值普遍偏高。当然,一般模型也无法做到百分之百的分类准确,所以存在少量的负样本预测概率较高,正样本预测概率偏低,如图右上角和左下角。
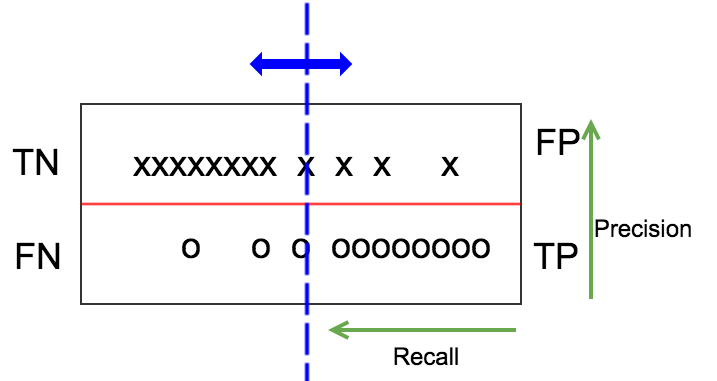
Confusion Matrix
我们设定一个阈值,用图中蓝色的竖线表示,高于阈值的模型预测为正样本,反之则为负样本。这个阈值是我们可以自行设定的,蓝色的竖线可以左右移动。红色的横线和蓝色的竖线将整个测试集数据分成四个部分,TN(True Positive)、FP(False Positive)、FN(False Negative)、TP(True Positive)。TPR(TP rate)即recall= TP/(TP+FN),precision=TP/(TP+FP)。上面我们计算accuracy实际上是 (TN+TP)/ALL,对于一个测试集来说,底下分母是不变的,如果TN对比TP很大,TP的变动很难通过accuracy反映出来。一个好的分类器,应该TP包含大部分圆圈,FP和FN几乎为空,所以很多比赛的评测指标是precision和recall的harmonic平均值,即:
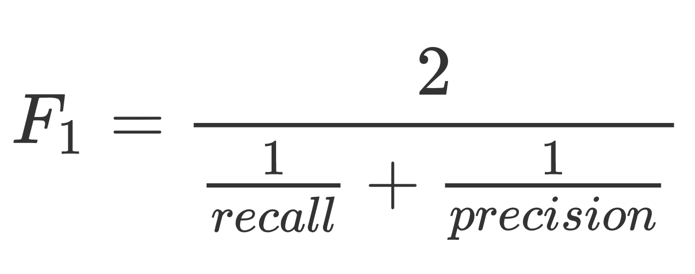
harmonic平均比直接除以2更看重较小的那个值,只有两个值都比较大,整体才会大。
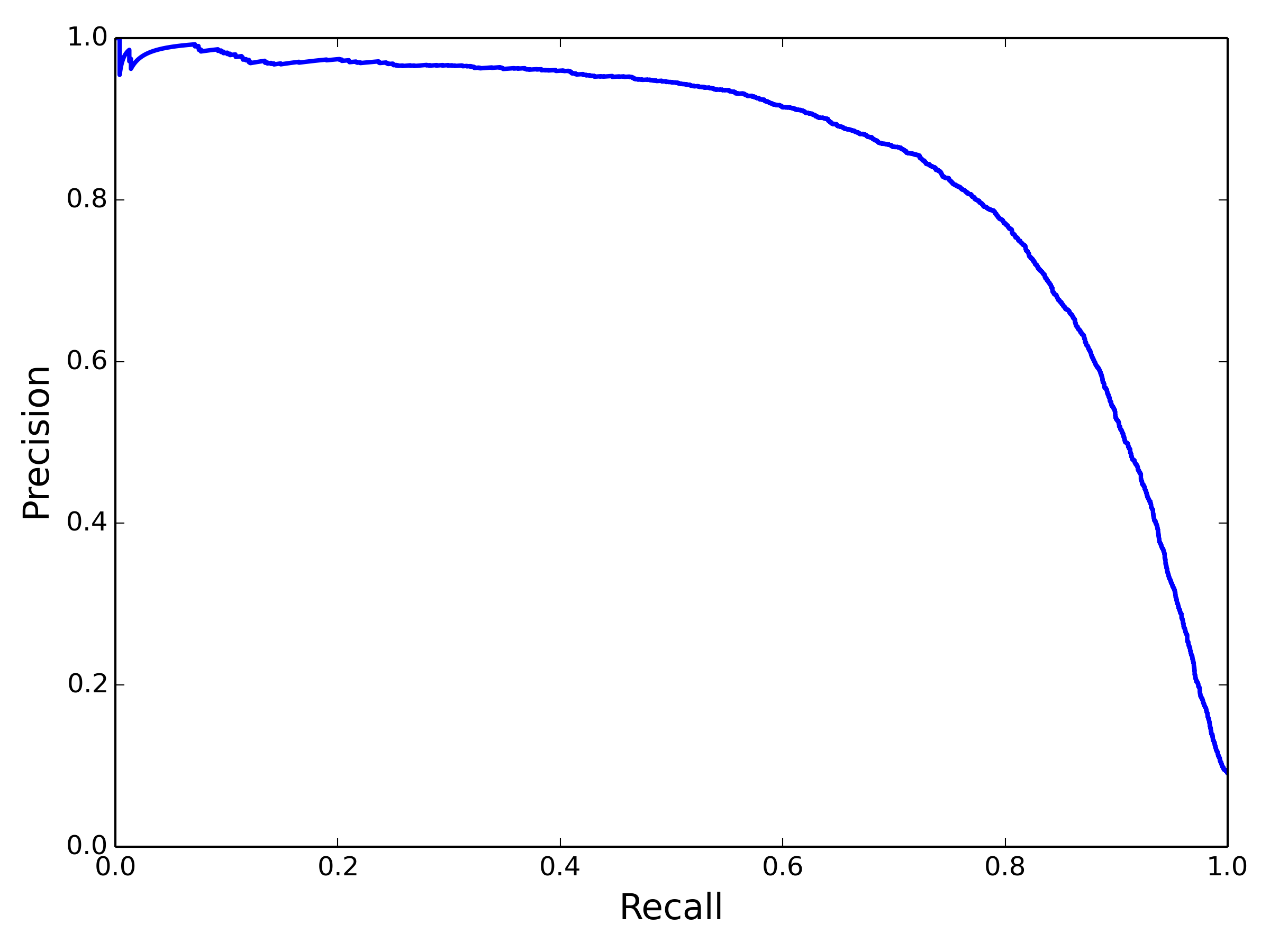
PR曲线和ROC曲线
为了得到较好的F1,需要调节适当的阈值。蓝色的线从最左往右滑动时,recall= TP/(TP+FN),分母不变,分子逐渐变小,从1单调递减到0。precision=TP/(TP+FP),分子和分母同时变小,总体上,TP变小的速度慢很多,大体上是递增的,但是并不绝对单调,尤其在靠近右侧。经常可以看到TP-1,FP不变,则precision反而变小:

关于Recall和Precision的tradeoff,还可以画一条PR 曲线:
ROC曲线是另外一种衡量二分类模型的方法,y轴是recall=TP/(TP+FN),x轴是FPR=FP/(FP+TN):
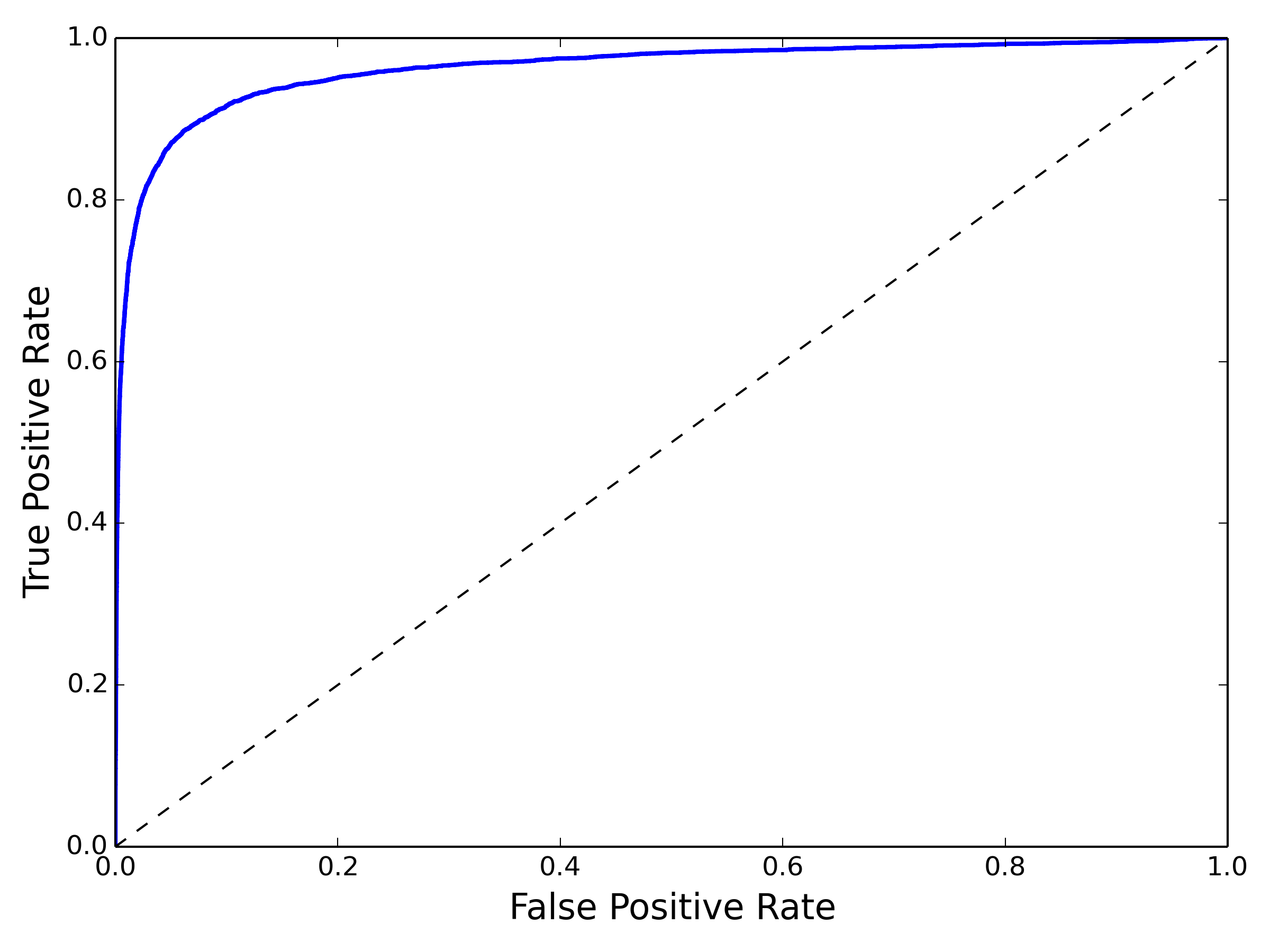
PR曲线与ROC曲线的区别在于,PR曲线不关心TN(x、y计算公式都没有包含TN),所以在负样本比例很高的时候,PR曲线波动比ROC曲线明显,更能体现优化空间。另外,ROC曲线关心TN恰好也是它的优势,比如在推荐、搜索等learn to rank 任务中,我们关心的是整个数据集的排序情况,TN也是需要考虑在内的,所以经常离线计算AUC(ROC曲线下方面积)来衡量rank model的优劣。
中场休息时间。。。喝口茶~ 欢迎关注公众号:kaggle实战,或博客:http://www.cnblogs.com/daniel-D/
4. 多分类器与误差分析
多分类器是指能区别两个以上类别的分类器,比如手写数字识别这个数据集要区分0-9,像大型图像数据集可能有几万个类别。有些算法可以直接区分多类,如softmax、RF或者贝叶斯,有些算法无法直接区分,比如上面用到的线性分类器等二分类器。二分类器也可以组合形成多分类器,常见的策略有 One vs All和 One vs One。
在数字识别这个任务中,One vs All(OVA) 一共要训练10个分类器,分别是0 vs 非0,1 vs 非1……预测的时候,10个分类器依次输出为0,为1等的概率,可直接取最大概率作为预测值。One vs One则需要10*(10-1)/ 2个分类器,依次是 0 vs 1,0 vs 2……8 vs 9。OVO和OVA在实际使用不多,这里就不赘述了。
用RF模型训练后,在预测集上预测图像属于哪个类别,由于模型不是百分百准确的,会有0判定成1或者1判定成2的情况,用rowIndex表示实际的label,colIndex表示预测的label,统计预测的label落到实际label的个数,可以得到以下矩阵:

可视化之后得到下图:
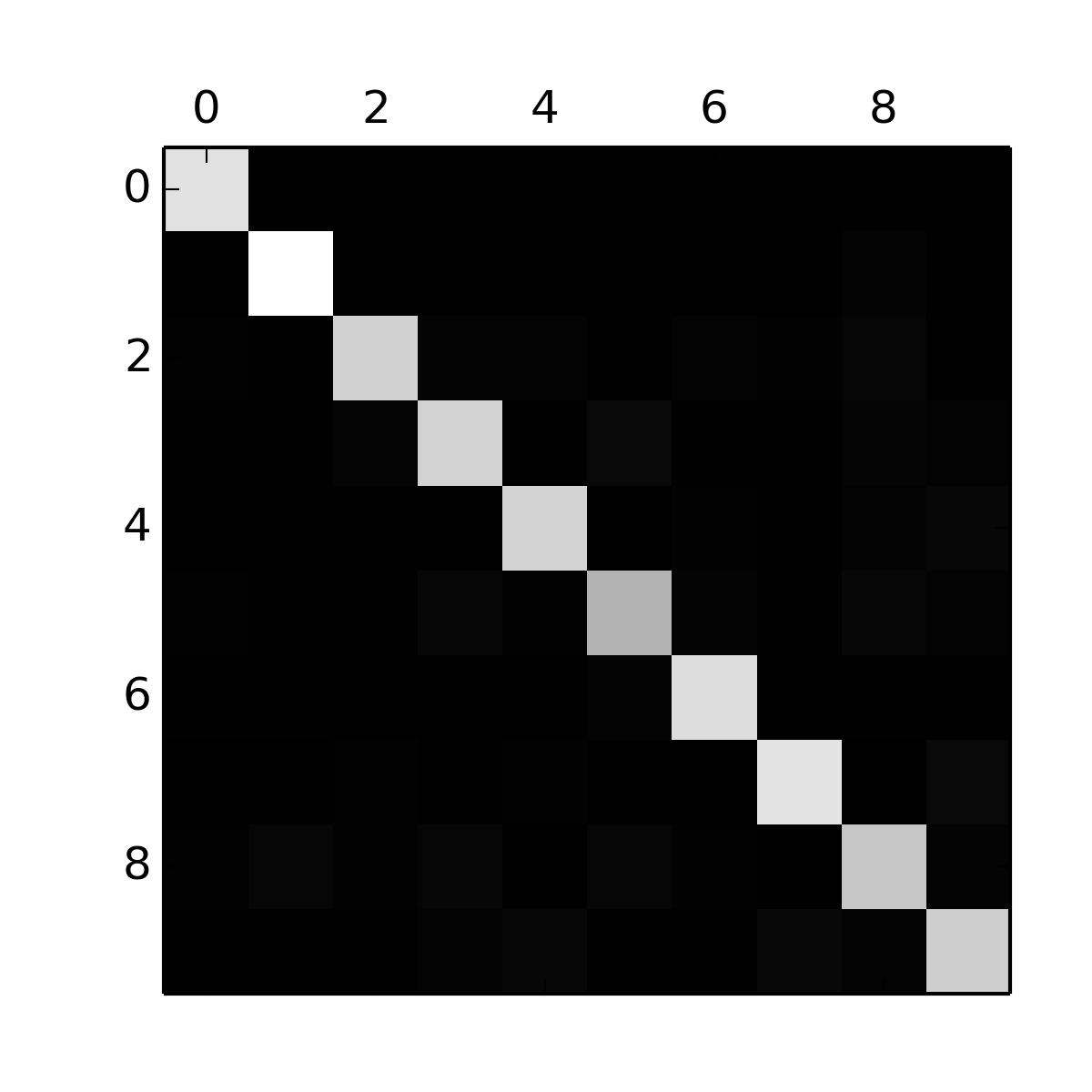
可以看到对角线方块很亮,说明所有类别基本判定准确。但是“5”方块较暗,可能是由于5的图片数量较少,或者5的准确率偏低导致,要具体分析数据才能找到原因。除了对角线方块,我们还想分析其余方块的情况,可以把Confusion Matrix每个元素处理该行的总和,对角线置0,得到下图:

可以看到3和5、7和9都容易混淆,想通过RF模型要提升效果的突破口可能就在这里。
5. Kaggle 实战
实际上,3和5、7和9容易混淆的原因在于,他们形态较为相似,直接用像素作为特征,相同的数字,在图像中旋转微小角度或者平移,都会导致像素空间的巨大变化,kaggle上高分kernel普遍都用神经网络里的CNN来提取特征,准确率可以轻松超过98%。预处理流程为:
- 把 label 从0-9的dense编码转化为 one hot encode编码
- 分割出4w个训练集和2k个验证集
然后定义一个最常用CNN网络结构和主要的超参数如下:
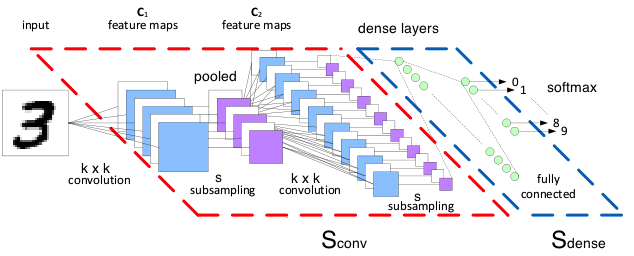
卷积参数:一般设置stride=1,卷积后保持原尺寸,用0填充,非线性变换采用relu;pooling大小2*2,stride=2,取maxPooling
网络结构:
- input:(40000, 28, 28, 1)
- conv1:kernel [5, 5, 1, 32] => (40000, 28, 28, 32)
- maxPool1:kernel [1, 2, 2, 1] => (40000, 14, 14, 32)
- conv2:kernel [5, 5, 32, 64] => (40000, 14, 14, 64)
- maxPool2: kernel [1, 2, 2, 1] => (40000, 7, 7, 64)
- flat:(40000,7*7*64) => (40000, 3136)
- FC1: (40000, 1024),非线性变换仍然可以采用relu
- dropout: 0.5
- FC2:(40000, 10)
- Loss:cross-entropy
由于MNIST数据集各类分布都比较均匀,用准确率就能较好评估模型了,比其他指标更加直白
详细代码可以参考这个kernel:https://www.kaggle.com/kakauandme/tensorflow-deep-nn
参考资料
- Kaggle: TensorFlow deep NN
- Book: Hands-on machine learning with scikit-learn and tensorflow
- Code:03_classification.ipynb
附:公众号

顺便测试下赞赏码

Kaggle实战之二分类问题的更多相关文章
- Kaggle实战分类问题2
Kaggle实战之二分类问题 0. 前言 1. MNIST 数据集 2. 二分类器 3. 效果评测 4. 多分类器与误差分析 5. Kaggle 实战 0. 前言 “尽管新技术新算法层出不穷,但是掌握 ...
- 文本分类实战(二)—— textCNN 模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Kaggle实战之一回归问题
0. 前言 1.任务描述 2.数据概览 3. 数据准备 4. 模型训练 5. kaggle实战 0. 前言 "尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题 ...
- Python机器学习实践与Kaggle实战(转)
https://mlnote.wordpress.com/2015/12/16/python%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E8%B7%B5 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- 监督学习——logistic进行二分类(python)
线性回归及sgd/bgd的介绍: 监督学习--随机梯度下降算法(sgd)和批梯度下降算法(bgd) 训练数据形式: (第一列代表x1,第二列代表 x2,第三列代表 数据标签 用 0/ ...
- 【深度学习系列】PaddlePaddle垃圾邮件处理实战(二)
PaddlePaddle垃圾邮件处理实战(二) 前文回顾 在上篇文章中我们讲了如何用支持向量机对垃圾邮件进行分类,auc为73.3%,本篇讲继续讲如何用PaddlePaddle实现邮件分类,将深度 ...
- tensorflow实现二分类
读万卷书,不如行万里路.之前看了不少机器学习方面的书籍,但是实战很少.这次因为项目接触到tensorflow,用一个最简单的深层神经网络实现分类和回归任务. 首先说分类任务,分类任务的两个思路: 如果 ...
- 机器学习(一):记一次k一近邻算法的学习与Kaggle实战
本篇博客是基于以Kaggle中手写数字识别实战为目标,以KNN算法学习为驱动导向来进行讲解. 写这篇博客的原因 什么是KNN kaggle实战 优缺点及其优化方法 总结 参考文献 写这篇博客的原因 写 ...
随机推荐
- Echarts数据可视化radar雷达坐标系,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- git的使用(进阶篇)
如何处理代码冲突 冲突合并一般是因为自己的本地做的提交和服务器上的提交有差异,并且这些差异中的文件改动,Git不能自动合并,那么就需要用户手动进行合并 如我这边执行git pull origin ma ...
- 小程序1_app.json配置
1 window配置: window属性主要用于设置小程序的状态栏,导航条,标题,窗口背景色 直接在app.json里配置即可 2 tabBar底部导航 一般程序都会有底部导航栏,这个同样只要在app ...
- win10 uwp 如何让一个集合按照需要的顺序进行排序
虽然这是 C# 的技术,但是我是用在 uwp ,于是就把标题写这个名.有一天,我的小伙伴让我优化一个列表.这个列表是 ListView 他绑定了一个 ObservableCollection 所以需要 ...
- Java 线程基本知识
线程 线程和进程 进程 : 进程指正在运行的程序.确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能. 线程 : 线程是进程中的一个执行单元(执行路径 ...
- winform中执行任务,解决未响应界面
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e) { var coun ...
- 实验之-----------修改oracle实例名
--查询当前数据库实例名称: SQL> select instance_name,status from v$instance; INSTANCE_NAME STATUS------------ ...
- web 开发中的路由是什么意思
路由: 就是一个路径的解析,根据客户端提交的路径,将请求解析到相应的控制器上 从 URL 找到处理这个 URL 的类和函数
- 博客迁移至 http://www.loveli.site
对于博客园的Markdow 支持太过...,你懂的, 以后博客迁移至:http://www.loveli.site
- Cloud9 on Docker镜像发送
老外有做过几个cloud9的镜像,但是都有各种各样的问题. 小弟在此做了一个docker镜像,特此分享,希望各位大佬多提宝贵意见.谢谢. Cloud9 Online IDE Coding anywhe ...