深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结。
1. DNN的L1&L2正则化
想到正则化,我们首先想到的就是L1正则化和L2正则化。L1正则化和L2正则化原理类似,这里重点讲述DNN的L2正则化。
而DNN的L2正则化通常的做法是只针对与线性系数矩阵$W$,而不针对偏倚系数$b$。利用我们之前的机器学习的知识,我们很容易可以写出DNN的L2正则化的损失函数。
假如我们的每个样本的损失函数是均方差损失函数,则所有的m个样本的损失函数为:$$J(W,b) = \frac{1}{2m}\sum\limits_{i=1}^{m}||a^L-y||_2^2$$
则加上了L2正则化后的损失函数是:$$J(W,b) = \frac{1}{2m}\sum\limits_{i=1}^{m}||a^L-y||_2^2 + \frac{\lambda}{2m}\sum\limits_{l=2}^L||w||_2^2$$
其中,$\lambda$即我们的正则化超参数,实际使用时需要调参。而$w$为所有权重矩阵$W$的所有列向量。
如果使用上式的损失函数,进行反向传播算法时,流程和没有正则化的反向传播算法完全一样,区别仅仅在于进行梯度下降法时,$W$的更新公式。
回想我们在深度神经网络(DNN)反向传播算法(BP)中,$W$的梯度下降更新公式为:$$W^l = W^l -\alpha \sum\limits_{i=1}^m \delta^{i,l}(a^{x, l-1})^T $$
则加入L2正则化以后,迭代更新公式变成:$$W^l = W^l -\alpha \sum\limits_{i=1}^m \delta^{i,l}(a^{i, l-1})^T -\alpha \lambda W^l $$
注意到上式中的梯度计算中$\frac{1}{m}$我忽略了,因为$\alpha$是常数,而除以$m$也是常数,所以等同于用了新常数$\alpha$来代替$ \frac{\alpha}{m}$。进而简化表达式,但是不影响损失算法。
类似的L2正则化方法可以用于交叉熵损失函数或者其他的DNN损失函数,这里就不累述了。
2. DNN通过集成学习的思路正则化
除了常见的L1&L2正则化,DNN还可以通过集成学习的思路正则化。在集成学习原理小结中,我们讲到集成学习有Boosting和Bagging两种思路。而DNN可以用Bagging的思路来正则化。常用的机器学习Bagging算法中,随机森林是最流行的。它 通过随机采样构建若干个相互独立的弱决策树学习器,最后采用加权平均法或者投票法决定集成的输出。在DNN中,我们一样使用Bagging的思路。不过和随机森林不同的是,我们这里不是若干个决策树,而是若干个DNN的网络。
首先我们要对原始的m个训练样本进行有放回随机采样,构建N组m个样本的数据集,然后分别用这N组数据集去训练我们的DNN。即采用我们的前向传播算法和反向传播算法得到N个DNN模型的$W,b$参数组合,最后对N个DNN模型的输出用加权平均法或者投票法决定最终输出。
不过用集成学习Bagging的方法有一个问题,就是我们的DNN模型本来就比较复杂,参数很多。现在又变成了N个DNN模型,这样参数又增加了N倍,从而导致训练这样的网络要花更加多的时间和空间。因此一般N的个数不能太多,比如5-10个就可以了。
3. DNN通过dropout 正则化
这里我们再讲一种和Bagging类似但是又不同的正则化方法:Dropout。
所谓的Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元。
比如我们本来的DNN模型对应的结构是这样的:
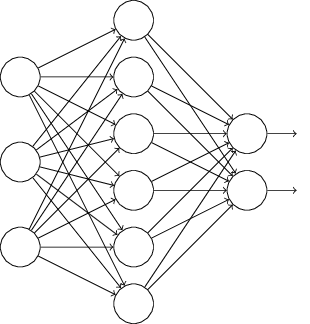
在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元,并用去掉隐藏层的神经元的网络来拟合我们的一批训练数据。如下图,去掉了一半的隐藏层神经元:
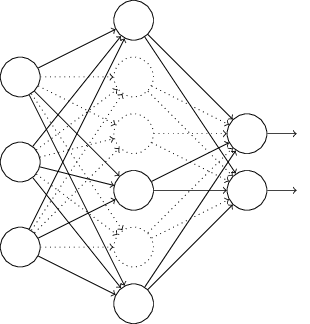
然后用这个去掉隐藏层的神经元的网络来进行一轮迭代,更新所有的$W,b$。这就是所谓的dropout。
当然,dropout并不意味着这些神经元永远的消失了。在下一批数据迭代前,我们会把DNN模型恢复成最初的全连接模型,然后再用随机的方法去掉部分隐藏层的神经元,接着去迭代更新$W,b$。当然,这次用随机的方法去掉部分隐藏层后的残缺DNN网络和上次的残缺DNN网络并不相同。
总结下dropout的方法: 每轮梯度下降迭代时,它需要将训练数据分成若干批,然后分批进行迭代,每批数据迭代时,需要将原始的DNN模型随机去掉部分隐藏层的神经元,用残缺的DNN模型来迭代更新$W,b$。每批数据迭代更新完毕后,要将残缺的DNN模型恢复成原始的DNN模型。
从上面的描述奎看出dropout和Bagging的正则化思路还是很不相同的。dropout模型中的$W,b$是一套,共享的。所有的残缺DNN迭代时,更新的是同一组$W,b$;而Bagging正则化时每个DNN模型有自己独有的一套$W,b$参数,相互之间是独立的。当然他们每次使用基于原始数据集得到的分批的数据集来训练模型,这点是类似的。
使用基于dropout的正则化比基于bagging的正则化简单,这显而易见,当然天下没有免费的午餐,由于dropout会将原始数据分批迭代,因此原始数据集最好较大,否则模型可能会欠拟合。
4. DNN通过增强数据集正则化
增强模型泛化能力最好的办法是有更多更多的训练数据,但是在实际应用中,更多的训练数据往往很难得到。有时候我们不得不去自己想办法能无中生有,来增加训练数据集,进而得到让模型泛化能力更强的目的。
对于我们传统的机器学习分类回归方法,增强数据集还是很难的。你无中生有出一组特征输入,却很难知道对应的特征输出是什么。但是对于DNN擅长的领域,比如图像识别,语音识别等则是有办法的。以图像识别领域为例,对于原始的数据集中的图像,我们可以将原始图像稍微的平移或者旋转一点点,则得到了一个新的图像。虽然这是一个新的图像,即样本的特征是新的,但是我们知道对应的特征输出和之前未平移旋转的图像是一样的。
举个例子,下面这个图像,我们的特征输出是5。

我们将原始的图像旋转15度,得到了一副新的图像如下:

我们现在得到了一个新的训练样本,输入特征和之前的训练样本不同,但是特征输出是一样的,我们可以确定这是5.
用类似的思路,我们可以对原始的数据集进行增强,进而得到增强DNN模型的泛化能力的目的。
5. 其他DNN正则化方法
DNN的正则化的方法是很多的,还是持续的研究中。在Deep Learning这本书中,正则化是洋洋洒洒的一大章。里面提到的其他正则化方法有:Noise Robustness, Adversarial Training,Early Stopping等。如果大家对这些正则化方法感兴趣,可以去阅读Deep Learning这本书中的第七章。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
深度神经网络(DNN)的正则化的更多相关文章
- 深度神经网络DNN的多GPU数据并行框架 及其在语音识别的应用
深度神经网络(Deep Neural Networks, 简称DNN)是近年来机器学习领域中的研究热点,产生了广泛的应用.DNN具有深层结构.数千万参数需要学习,导致训练非常耗时.GPU有强大的计算能 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
- 深度神经网络(DNN)模型与前向传播算法
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一个总结. 1. 从感知机 ...
- 神经网络6_CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程,QQ:231469242) https://study.163.com/course/introduction.htm?courseId ...
- 深度神经网络(DNN)
深度神经网络(DNN) 深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一 ...
- 云中的机器学习:FPGA 上的深度神经网络
人工智能正在经历一场变革,这要得益于机器学习的快速进步.在机器学习领域,人们正对一类名为“深度学习”算法产生浓厚的兴趣,因为这类算法具有出色的大数据集性能.在深度学习中,机器可以在监督或不受监督的方式 ...
- 深度神经网络(DNN)损失函数和激活函数的选择
在深度神经网络(DNN)反向传播算法(BP)中,我们对DNN的前向反向传播算法的使用做了总结.里面使用的损失函数是均方差,而激活函数是Sigmoid.实际上DNN可以使用的损失函数和激活函数不少.这些 ...
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
https://www.zhihu.com/question/34681168 CNN(卷积神经网络).RNN(循环神经网络).DNN(深度神经网络)的内部网络结构有什么区别?修改 CNN(卷积神经网 ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
随机推荐
- iOS数据存储
[reference]http://www.infoq.com/cn/articles/data-storage-in-ios 谈到数据储存,首先要明确区分两个概念,数据结构和储存方式.所谓数据结构就 ...
- vs2015编译mysql c++ connector
目前MySQL Connector/C++的binary版本最高只支持VS2008,VS2015需要下载源码自行编译. 1.CMAKE 到官网下载最新的稳定版本 把bin目录添加到环境变量PATH中 ...
- NamingException with message: Name [spring.liveBeansView.mbeanDomain]
spring mvc启动出现 NamingException with message: Name [spring.liveBeansView.mbeanDomain],解决方式: 在web.xml中 ...
- Raphael的set使用
Raphael的set使用 $(function() { initRaphael(); }); function initRaphael(e) { var paper = Raphael(0, 0, ...
- myeclipse 2014破解
开始安装的时候已经进行了破解,不知道为什么还是会出现问题,按照下面说的才可以了: http://blog.sina.com.cn/s/blog_7f5862570101oxyv.html
- JS加载相对路径脚本的方法 - 汇总
js加载脚本的方式有很多,但是各有各的用途. 最近公司https项目改造,对于资源文件这一块,也是遇到一些问题,现在就来总结一下,怎样改造https的脚本吧~! 方法1.借助服务端语言如PHP,输入当 ...
- KVO,看我就够了!
概述 KVO全称Key-Value-Observing,也叫键值监听,是一种观察者设计模式.提供了一种机制,当指定的对象的属性被修改后,对象就会收到一个通知.也就是说每次指定的被观察的对象的属性被修改 ...
- python yield generator 详解
本文将由浅入深详细介绍yield以及generator,包括以下内容:什么generator,生成generator的方法,generator的特点,generator基础及高级应用场景,genera ...
- SDWebImage源码解读之分类
第十一篇 前言 我们知道SDWebImageManager是用来管理图片下载的,但我们平时的开发更多的是使用UIImageView和UIButton这两个控件显示图片. 按照正常的想法,我们只需要在他 ...
- ubuntu14.04下手动安装eclipse
ubuntu14.04下手动安装eclipse 第一步: 安装jdk 第二步: 下载eclipse,假设下载的文件文件名为eclipse.tar.gz 第三步: 解压 sudo -zxvf ./ecl ...