决策树算法4:CHAID

原理:


其中 n = a+b+c+d
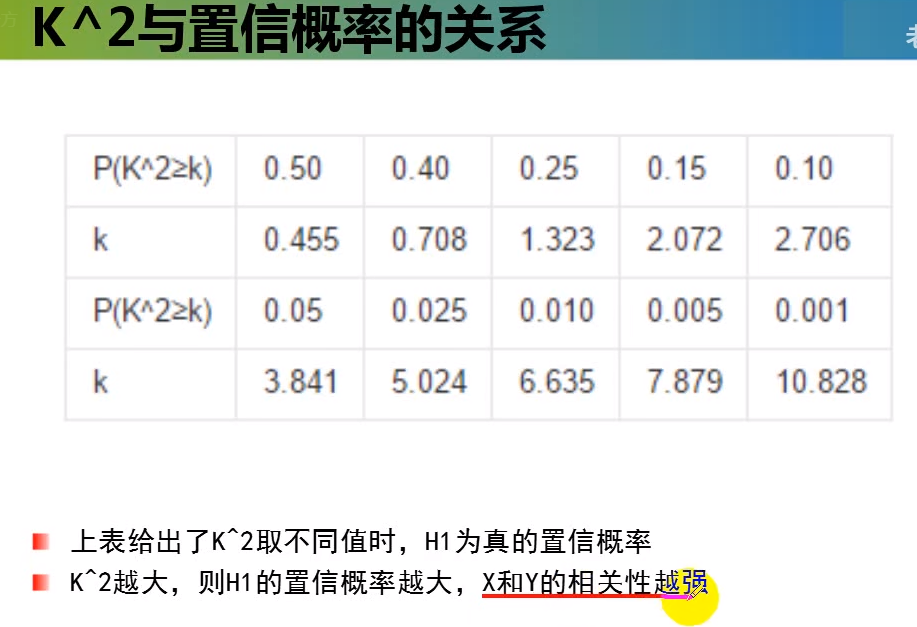
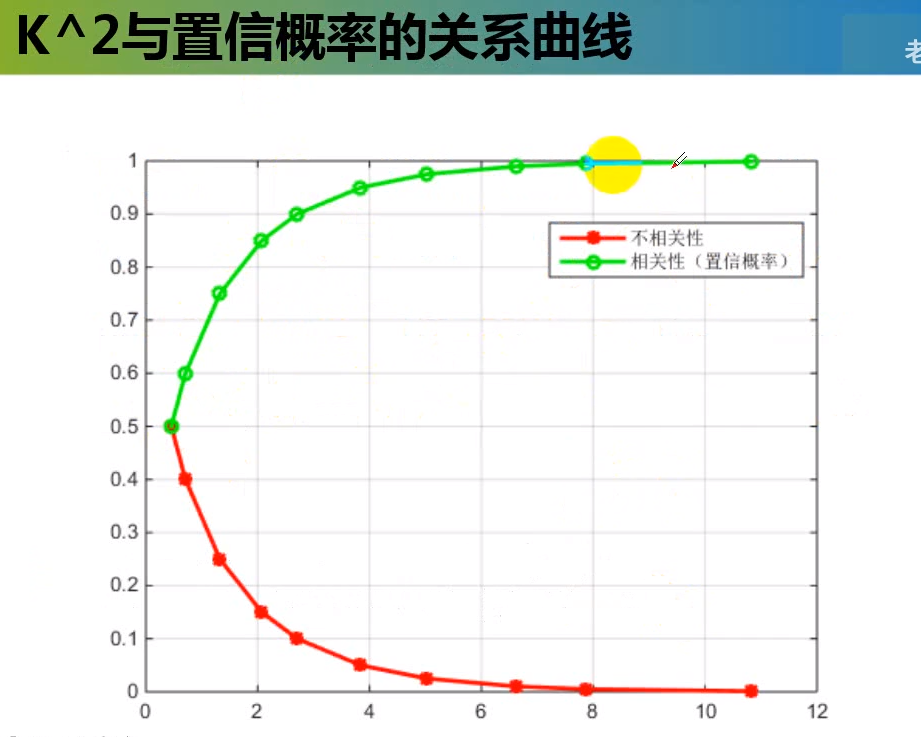
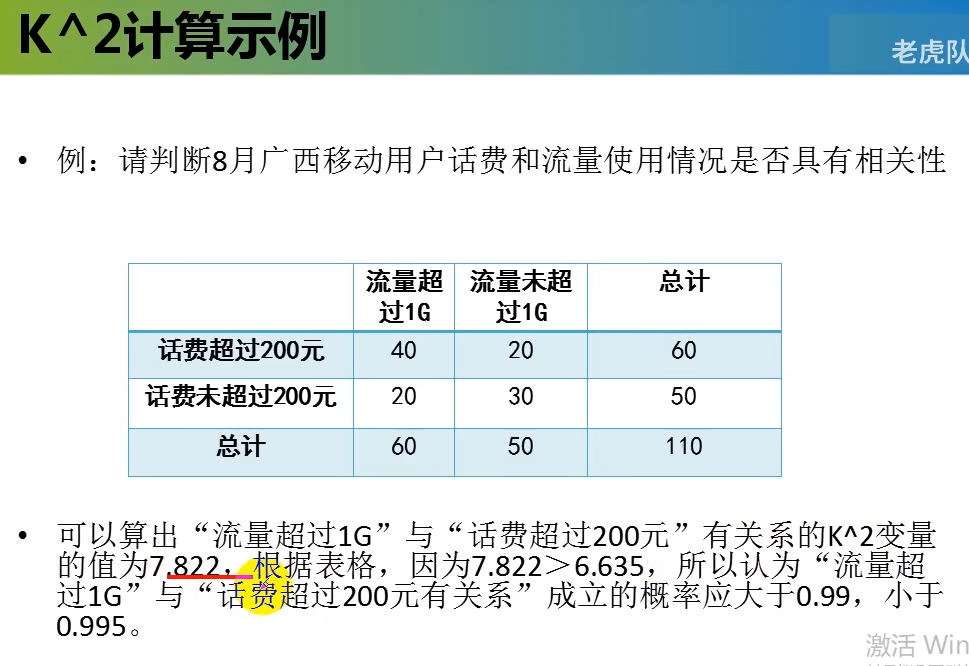

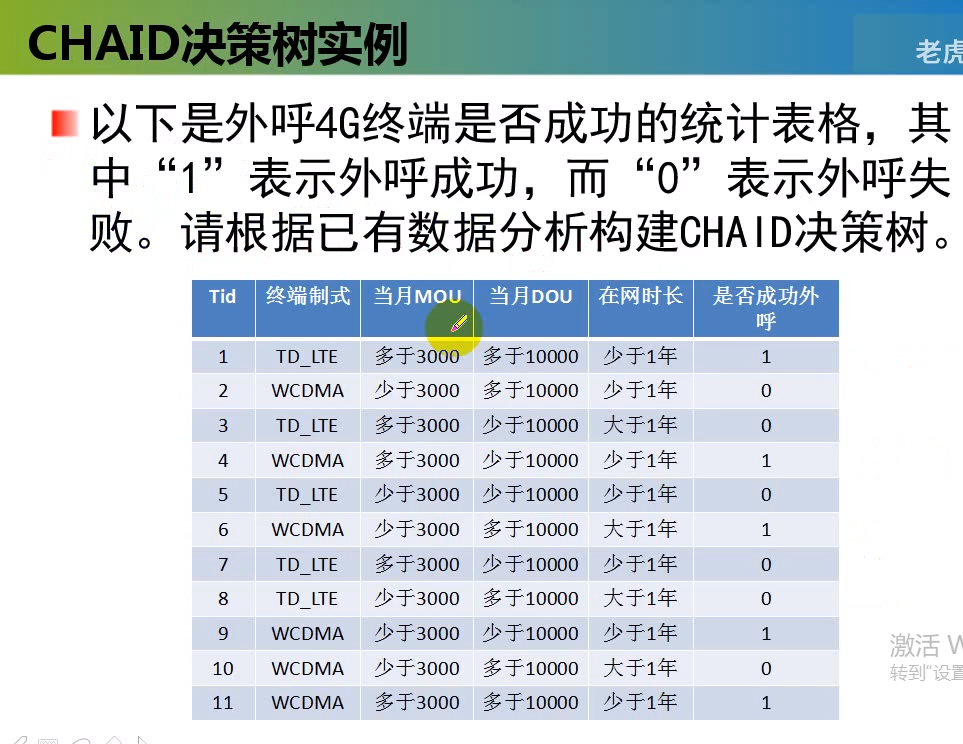

卡方计算(例子)使用 sklearn完成
data.csv中的部分数据
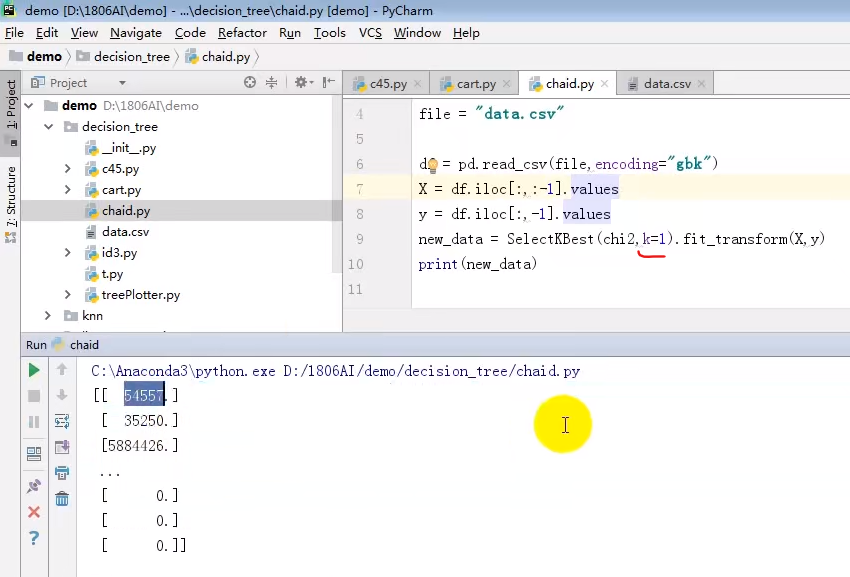
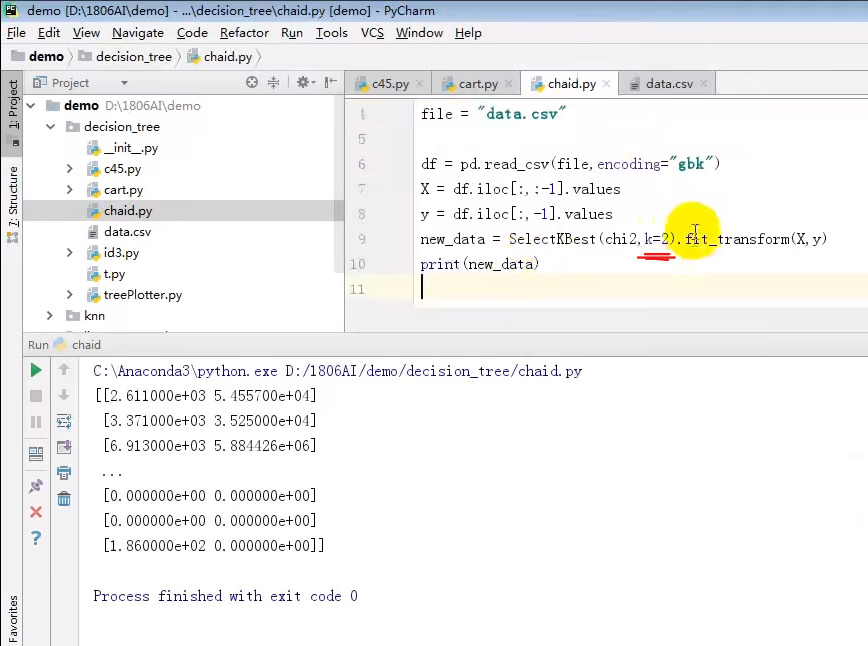
#如何使用卡方检测相关度
from sklearn.feature_selection import SelectKBest,chi2
import pandas as pd file='data.csv'
df=pd.read_csv(file,encoding='gbk') #数据本身
X=df.iloc[:,:-1].values #iloc取下标位置
y=df.iloc[:,-1].values
new_data=SelectKBest(chi2,k=2).fit_transform(X,y) #k表示取几个与y最相关的属性
print()
决策树算法4:CHAID的更多相关文章
- scikit-learn决策树算法类库使用小结
之前对决策树的算法原理做了总结,包括决策树算法原理(上)和决策树算法原理(下).今天就从实践的角度来介绍决策树算法,主要是讲解使用scikit-learn来跑决策树算法,结果的可视化以及一些参数调参的 ...
- 4-Spark高级数据分析-第四章 用决策树算法预测森林植被
预测是非常困难的,更别提预测未来. 4.1 回归简介 随着现代机器学习和数据科学的出现,我们依旧把从“某些值”预测“另外某个值”的思想称为回归.回归是预测一个数值型数量,比如大小.收入和温度,而分类则 ...
- 《BI那点儿事》Microsoft 决策树算法
Microsoft 决策树算法是由 Microsoft SQL Server Analysis Services 提供的分类和回归算法,用于对离散和连续属性进行预测性建模.对于离散属性,该算法根据数据 ...
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
- 转载:scikit-learn学习之决策树算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 决策树算法实现(train+test,matlab) 转
原文:http://www.zgxue.com/198/1985544.html 华电北风吹 天津大学认知计算与应用重点实验室 修改日期:2015/8/15 决策树是一种特别简单的机器学习分类算法.决 ...
- [转]机器学习——C4.5 决策树算法学习
1. 算法背景介绍 分类树(决策树)是一种十分常用的分类方法.它是一种监管学习,所谓监管学习说白了很简单,就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分 ...
- ID3决策树算法原理及C++实现(其中代码转自别人的博客)
分类是数据挖掘中十分重要的组成部分.分类作为一种无监督学习方式被广泛的使用. 之前关于"数据挖掘中十大经典算法"中,基于ID3核心思想的分类算法C4.5榜上有名.所以不难看出ID3 ...
- R语言 决策树算法
定义: 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解 ...
随机推荐
- 一个C#程序的执行过程
可能很多人都知道我们把程序打包成dll就丢出去了,但是里面的具体的执行过程是怎么样的呢. 程序集是由元数据和IL组成的.IL是和CPU无关的语言,是微软的几个专家请教了外面的编译器的作则,开发出来的. ...
- 经验分享:分析如何使程序在Linux下后台运行---Linux就该这么学!
转至:https://www.cnblogs.com/maoju/p/13848740.html 一.为什么要使程序在后台执行 我们计算的程序都是周期很长的,通常要几个小时甚至一个星期.我们用的环 ...
- Git——版本控制器概述
一.版本控制 版本控制(Revision contontrol)是一种在开发过程中用于管理修改历史,方便查看更改历史记录,备份以便恢复以前版本的软件工程的技术. 1.实现跨区域多人协同开发 2.追踪和 ...
- 论文解读(GIN)《How Powerful are Graph Neural Networks》
Paper Information Title:<How Powerful are Graph Neural Networks?>Authors:Keyulu Xu, Weihua Hu, ...
- Java:代码改进技巧
1.类名首字母大写:方法名首字母小写:常量名全大写: 2.当控制语句只有一句时,可以省略大括号{}:但是,建议任何时候都保留大括号,因为这是Java语句块的标志 3.用某个接口承接实现类时(多态),之 ...
- jq获取不包含某些属性的元素
最近写项目,有个功能实现checkbox全选,但是被禁用的checkbox不能选中 点击全选后发现禁用checkbox的也被选中了,不符合需求. 但是想了半天,属性选择器都是判断某个属性值的,没有判断 ...
- JAVA——选择,循环,顺序控制结构
目录 一.顺序控制 二.选择控制 2.1分支控制 2.1.1单分支 2.1.2双分支 2.1.3分支控制if-else 2.1.4嵌套分支 2.2switch分支结构 细节讨论 练习 题目1 题目2 ...
- 2022年官网下安装GIT最全版与官网查阅方法
目录 安装部署Git 1.百度搜索git,双击进入. 2.进入主页,双击如图位置. 3.进入下载列表,双击下载. 4.找到本地文件位置,双击安装,弹出界面,选择next 5.进入安装路径位置,修改路径 ...
- CF492E题解
屑题. 考虑对于每一个 \((x,y)\),将其与 \(((x+dx) \mod n,(y+dy) \mod n)\) 连边. 答案就是连通块中权值最大的那个. 考虑对于 \((x_1,y_1)\) ...
- 『德不孤』Pytest框架 — 14、Pytest中的conftest.py文件
目录 1.conftest.py文件介绍 2.conftest.py的注意事项 3.conftest.py的使用 4.不同位置conftest.py文件的优先级 5.conftest.py中Fixtu ...