Pytorch-UNet-master>utils>data_loading.py
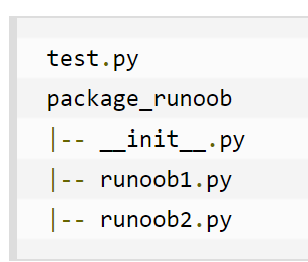
模块,包 在package_runoob同级目录下,用test.py调用package_runoob包中内容
参考链接:
Dataset 抽象类,所有创建的数据集都需要进行子类化,并重写__len__和__getitem__
from torch.utils.data import Dataset class BasicDataset(Dataset):
参考链接:
torch.utils.data - PyTorch中文文档 (pytorch-cn.readthedocs.io)
https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web
assert() 宏,断言,程序在假设条件下,能够正常良好的运作
参考链接:
https://www.runoob.com/w3cnote/c-assert.html
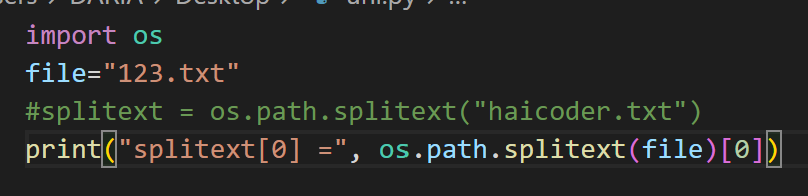
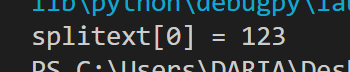
splitext() 用于分离文件名与扩展名
import os
os.path.splitext(path)
e.g.
参考链接:
Python分离文件名与扩展名-Python splitext函数-嗨客网 (haicoder.net)
logging.info() 类似print()的功能
参考链接:
python中logging模块上篇 - 知乎 (zhihu.com)
class Time():
@staticmethod
def sec_minutes(s1,s2):
可以直接用,调用
Time.sec_minutes()
也可以创建实例,调用
t=Time() t.sec_minutes()
参考链接:
简述python中的@staticmethod作用及用法 - 云+社区 - 腾讯云 (tencent.com)
pil_img = pil_img.resize((newW, newH), resample=Image.NEAREST if is_mask else Image.BICUBIC)
np.asarray() 将结构数据转化为ndarray类型
import imghdr
import cv2
import numpy as np img=cv2.imread("./00021_mask.png")
img=np.asarray(img) print("img.ndim:",img.ndim)
print("img.shape",img.shape)
print("len(img.shape)",len(img.shape))
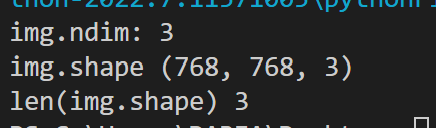
img.shape 输出数组的长、宽、通道数
np.transpose() 类似数组转置的操作,(0,1,2)对应(x,y,z)
arr.transpose((2,0,1))
相当于转成了(z, x, y)
numpy.load() 函数从具有npy扩展名(.npy)的磁盘文件返回输入数组
参考链接:
Python numpy.load()用法及代码示例 - 纯净天空 (vimsky.com)
Image.fromarray() array到image的转换
参考链接:
(17条消息) Image.fromarray的用法(实现array到image的转换)_weixin_39450145的博客-CSDN博客_image.fromarray
glob.golb() 查找符合特定规则的文件路径名
super()._init_() 自动继承父类属性
btw 整理Dataset--BasicDataset--CarvanaDataset关系
from torch.utils.data import Dataset class BasicDataset(Dataset):
def __init__(self, images_dir: str, masks_dir: str, scale: float = 1.0, mask_suffix: str = ''):
def __len__(self):
def __getitem__(self, idx): class CarvanaDataset(BasicDataset):
def __init__(self, images_dir, masks_dir, scale=1):
super().__init__(images_dir, masks_dir, scale, mask_suffix='_mask')
Dataset 是torch中的一个抽象类,用于获取每一个数据及其label
BasicDataset是一个继承了Dataset的子类,需要重写__len__和__getitem__,这里的__init__是一种普通的继承关系,所以BasicDataset中一些属性需要自己定义、自己赋值
CarvanaDataset是一个继承了BasicDataset的子类,super().__init__自动继承父类属性,不需要对父类中定义过的属性再做定义了,可以用于对含_mask的后缀(suffix)实例化。
Pytorch-UNet-master>utils>data_loading.py的更多相关文章
- xxx/labelKeypoint/utils/qt.py:81: RuntimeWarning: invalid value encountered in double_scalars
原代码: return np.linalg.norm(np.cross(p2 - p1, p1 - p3)) / np.linalg.norm(p2 - p1) 出现报错: xxx/labelKeyp ...
- pytorch的torch.utils.data.DataLoader认识
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口, 该接 ...
- 深度学习(PYTORCH)-3.sphereface-pytorch.lfw_eval.py详解
pytorch版本sphereface的原作者地址:https://github.com/clcarwin/sphereface_pytorch 由于接触深度学习不久,所以花了较长时间来阅读源码,以下 ...
- 【pytorch】torch.utils.data.DataLoader
简介 DataLoader是PyTorch中的一种数据类型.用于训练/验证/测试时的数据按批读取. torch.utils.data.DataLoader(dataset, batch_size=1, ...
- week06 12 后端utils cloudAMQP_client.py 安装pika
我们回到后端 pika是专门处理RabitAMQP的包 或者你可以直接一步到位 我们不能一直让我们的网络爬虫一直爬信息 一是网络消耗很大(cpu) 二是容易被网站发现被禁ip self.connect ...
- https://github.com/PyMySQL/PyMySQL/blob/master/pymysql/connections.py
# Python implementation of the MySQL client-server protocol # http://dev.mysql.com/doc/internals/en/ ...
- [PyTorch]PyTorch中模型的参数初始化的几种方法(转)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 本文目录 1. xavier初始化 2. kaiming初始化 3. 实际使用中看到的初始化 3.1 ResNeXt,de ...
- tensorflow之数据读取探究(1)
Tensorflow中之前主要用的数据读取方式主要有: 建立placeholder,然后使用feed_dict将数据feed进placeholder进行使用.使用这种方法十分灵活,可以一下子将所有数据 ...
- TFRecord读写简介+Demo 基于Ubuntu18.04+Tensorflow1.12 无WARNING
简介 TFRecord是TensorFlow官方推荐使用的数据格式化存储工具. 它规范了数据的读写方式. 只要生成一次TFRecord,之后的数据读取和加工处理的效率都会得到提高. 将图片转换成TFR ...
- PyTorch源码解读之torch.utils.data.DataLoader(转)
原文链接 https://blog.csdn.net/u014380165/article/details/79058479 写得特别好!最近正好在学习pytorch,学习一下! PyTorch中数据 ...
随机推荐
- VScode打开文件夹位置技巧
VScode在打开文件夹,弹出对话框的时候,去文件夹(应用)到达该路径,对话框中的路径自动变为当前文件夹(应用)的路径.去文件夹(应用)到达该路径
- S-HR查询用户组织范围
SELECT org.FNumber FNumber,org.FName_L2 orgName FROM T_PM_OrgRange orgRange LEFT JOIN T_ORG_admin or ...
- python 的sys.argv 和 sys.path.append() 用法和PYTHONPATH环境变量
sys.argv 我们编写一个测试用例test.py ,内容如下 imoprt sys a = sys.argv b = len(sys.argv) c = sys.argv[0] d = sys.a ...
- const引用和指针
1.可以为const引用初始化一个非const的对象.字面值,甚至是一般表达式. 2.对引用初始化时必须严格进行类型匹配,但是const引用初始化时不需要类型匹配,只要可以转换为const所定义的类型 ...
- JavaScript 字符串的操作
1. 在指定位置,插入字符串(此需求来源于,img中src没值的字符串标签中,插入图片http地址) // 使用slice写出的 自定义方法,绑定在String的原型链上 String.prototy ...
- *args、**kwargs参数组
'''def test(*args): # *agrs接收的是N个位置参数,不能接受关键字参数,转化成元祖 print(args)test(1,2,3,4,5,6)test(*[1,2,4,5,5]) ...
- 20191323王予涵sort
sort 任务 用man sort 查看sort的帮助文档 sort常用选项有哪些,都有什么功能?提交相关使用的截图 如果让你编写sort,你怎么实现?写出伪代码和相关的函数或系统调用 一.查看帮助文 ...
- Activiti工作流引擎系列-第二篇
官网案例下载安装实例 { "info": { "_postman_id": "64f2d7ca-8287-4f8d-94ba-1138861877dd ...
- Docker基本命令之 容器管理
容器管理 查看正在运行的容器: docker ps 查看完整信息:docker ps --no-trunc 查看在运行或停止运行的容器:docker ps -a 查看容器系统资源的使用情况:docke ...
- 微服务注册到Nacos上的Ip错误,是内网ip不是公网ip
spring.cloud.nacos.discovery.ip = 本机公网IP spring.cloud.nacos.discovery.port = 服务端口