分布式机器学习:PageRank算法的并行化实现(PySpark)
1. PageRank的两种串行迭代求解算法
我们在博客《数值分析:幂迭代和PageRank算法(Numpy实现)》算法中提到过用幂法求解PageRank。
给定有向图
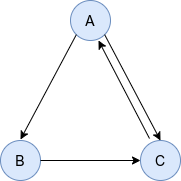
我们可以写出其马尔科夫概率转移矩阵\(M\)(第\(i\)列对应对\(i\)节点的邻居并沿列归一化)
0 & 0 & 1 \\
\frac{1}{2} & 0 & 0 \\
\frac{1}{2} & 1 & 0
\end{array}\right)
\]
然后我们定义Google矩阵为
\]
此处\(q\)为上网者从一个页面转移到另一个随机页面的概率(一般为0.15),\(1-q\) 为点击当前页面上链接的概率,\(E\)为元素全1的\(n\times n\) 矩阵( \(n\) 为节点个数)。
而PageRank算法可以视为求解Google矩阵占优特征值(对于随机矩阵而言,即1)对应的特征向量。设初始化Rank向量为 \(x\)( \(x_i\) 为页面\(i\)的Rank值),则我们可以采用幂法来求解:
\]
(每轮迭代后要归一化)
现实场景下的图大多是稀疏图,即\(M\)是稀疏矩阵。幂法中计算 \((1-q)Mx_t\) ,对于节点 \(i\) 需使用reduceByKey()(key为节点编号)操作。计算 \(\frac{q}{n}{E}x_t\) 则需要对所有节点的Rank进行reduce()操作,操作颇为繁复。
PageRank还有一种求解算法(名字就叫“迭代算法”),它的迭代形式如下:
\]
可以看到,这种迭代方法就规避了计算 \(\frac{q}{n}Ex_t\),通信开销更小。我们接下来就采用这种迭代形式。
2. 图划分的两种方法
目前对图算法进行并行化的主要思想是将大图切分为多个子图,然后将这些子图分布到不同的机器上进行并行计算,在必要时进行跨机器通信同步计算得出结果。学术界和工业界提出了多种将大图切分为子图的划分方法,主要包括两种,边划分(Edge Cut)和点划分(Vertex Cut)。
2.1 边划分
如下图所示,边划分是对图中某些边进行切分。具体在Pregel[1]图计算框架中,每个分区包含一些节点和节点的出边;在GraphLab[2]图计算框架中,每个分区包含一些节点、节点的出边和入边,以及这些节点的邻居节点。边划分的优点是可以保留节点的邻居信息,缺点是容易出现划分不平衡,如对于度很高的节点,其关联的边都被划分到一个分区中,造成其他分区中的边可能很少。另外,如下图最右边的图所示,边划分可能存在边冗余。

2.2 点划分
如下图所示,点划分是对图中某些点进行切分,得到多个图分区,每个分区包含一部分边,以及与边相关联的节点。具体地,PowerGraph[3],GraphX[4]等框架采用点划分,被划分的节点存在多个分区中。点划分的优缺点与边划分的优缺点正好相反,可以将边较为平均地分配到不同机器中,但没有保留节点的邻居关系。

总而言之,边划分将节点分布到不同机器中(可能划分不平衡),而点划分将边分布到不同机器中(划分较为平衡)。接下来我们使用的算法为类似Pregel的划分方式,使用边划分。我们下面的算法是简化版,没有处理悬挂节点的问题。
3. 对迭代算法的并行化
我们将Rank向量用均匀分布初始化(也可以用全1初始化,不过就不再以概率分布的形式呈现),设分区数为3,算法总体迭代流程可以表示如下:

注意,图中flatMap()步骤中,节点\(i\)计算其contribution(贡献度):\((x_t)_i/|\mathcal{N}_i|\),并将贡献度发送到邻居集合\(\mathcal{N}_i\)中的每一个节点。之后,将所有节点收到的贡献度使用reduceByKey()(节点编号为key)规约后得到向量\(\hat{x}\),和串行算法中\(Mx_t\)的对应关系如下图所示:

并按照公式\(x_{t+1} = \frac{q}{n} + (1-q)\hat{x}\)来计算节点的Rank向量。然后继续下一轮的迭代过程。
4. 编程实现
用PySpark对PageRank进行并行化编程实现,代码如下:
import re
import sys
from operator import add
from typing import Iterable, Tuple
from pyspark.resultiterable import ResultIterable
from pyspark.sql import SparkSession
n_slices = 3 # Number of Slices
n_iterations = 10 # Number of iterations
q = 0.15 #the default value of q is 0.15
def computeContribs(neighbors: ResultIterable[int], rank: float) -> Iterable[Tuple[int, float]]:
# Calculates the contribution(rank/num_neighbors) of each vertex, and send it to its neighbours.
num_neighbors = len(neighbors)
for vertex in neighbors:
yield (vertex, rank / num_neighbors)
if __name__ == "__main__":
# Initialize the spark context.
spark = SparkSession\
.builder\
.appName("PythonPageRank")\
.getOrCreate()
# link: (source_id, dest_id)
links = spark.sparkContext.parallelize(
[(1, 2), (1, 3), (2, 3), (3, 1)],
n_slices
)
# drop duplicate links and convert links to an adjacency list.
adj_list = links.distinct().groupByKey().cache()
# count the number of vertexes
n_vertexes = adj_list.count()
# init the rank of each vertex, the default is 1.0/n_vertexes
ranks = adj_list.map(lambda vertex_neighbors: (vertex_neighbors[0], 1.0/n_vertexes))
# Calculates and updates vertex ranks continuously using PageRank algorithm.
for t in range(n_iterations):
# Calculates the contribution(rank/num_neighbors) of each vertex, and send it to its neighbours.
contribs = adj_list.join(ranks).flatMap(lambda vertex_neighbors_rank: computeContribs(
vertex_neighbors_rank[1][0], vertex_neighbors_rank[1][1] # type: ignore[arg-type]
))
# Re-calculates rank of each vertex based on the contributions it received
ranks = contribs.reduceByKey(add).mapValues(lambda rank: q/n_vertexes + (1 - q)*rank)
# Collects all ranks of vertexs and dump them to console.
for (vertex, rank) in ranks.collect():
print("%s has rank: %s." % (vertex, rank))
spark.stop()
运行结果如下:
1 has rank: 0.38891305880091237.
2 has rank: 0.214416470596171.
3 has rank: 0.3966704706029163.
该Rank向量与我们采用串行幂法得到的Rank向量 \(R=(0.38779177,0.21480614,0.39740209)^{T}\) 近似相等,说明我们的并行化算法运行正确。
参考
[1] Malewicz G, Austern M H, Bik A J C, et al. Pregel: a system for large-scale graph processing[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. 2010: 135-146.
[2] Low Y, Gonzalez J, Kyrola A, et al. Distributed graphlab: A framework for machine learning in the cloud[J]. arXiv preprint arXiv:1204.6078, 2012.
[3] Gonzalez J E, Low Y, Gu H, et al. {PowerGraph}: Distributed {Graph-Parallel} Computation on Natural Graphs[C]//10th USENIX symposium on operating systems design and implementation (OSDI 12). 2012: 17-30.
[6] 许利杰,方亚芬. 大数据处理框架Apache Spark设计与实现[M]. 电子工业出版社, 2021.
[7] Stanford CME 323: Distributed Algorithms and Optimization (Lecture 15)
分布式机器学习:PageRank算法的并行化实现(PySpark)的更多相关文章
- 分布式机器学习:逻辑回归的并行化实现(PySpark)
1. 梯度计算式导出 我们在博客<统计学习:逻辑回归与交叉熵损失(Pytorch实现)>中提到,设\(w\)为权值(最后一维为偏置),样本总数为\(N\),\(\{(x_i, y_i)\} ...
- 分布式机器学习:同步并行SGD算法的实现与复杂度分析(PySpark)
1 分布式机器学习概述 大规模机器学习训练常面临计算量大.训练数据大(单机存不下).模型规模大的问题,对此分布式机器学习是一个很好的解决方案. 1)对于计算量大的问题,分布式多机并行运算可以基本解决. ...
- 分布式机器学习:模型平均MA与弹性平均EASGD(PySpark)
计算机科学一大定律:许多看似过时的东西可能过一段时间又会以新的形式再次回归. 1 模型平均方法(MA) 1.1 算法描述与实现 我们在博客<分布式机器学习:同步并行SGD算法的实现与复杂度分析( ...
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- Spark MLBase分布式机器学习系统入门:以MLlib实现Kmeans聚类算法
1.什么是MLBaseMLBase是Spark生态圈的一部分,专注于机器学习,包含三个组件:MLlib.MLI.ML Optimizer. ML Optimizer: This layer aims ...
- 机器学习经典算法之PageRank
Google 的两位创始人都是斯坦福大学的博士生,他们提出的 PageRank 算法受到了论文影响力因子的评价启发.当一篇论文被引用的次数越多,证明这篇论文的影响力越大.正是这个想法解决了当时网页检索 ...
- 分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 文章索引::"机器学 ...
- Adam:大规模分布式机器学习框架
引子 转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/46676515 又是好久没写博客,记得有一次看Ng大神的訪谈录,假设每周读三篇论文, ...
随机推荐
- java中抽象类和抽象方法到底有什么用呢?
抽象类和抽象方法有什么用呢?马克-to-win:当初sun公司为什么要设计抽象类和抽象方法呢?当你在做车的系统设计时,当你设计车这个通用类时,假如你确认别人实例化车这个通用类没有意义时(不知道是bik ...
- sql server总结二
一些常用查询 Insert into 表(字段一,字段二,字段三,---) values(插入一,插入二,插入三,----) Update 表 set 字段= where 字段= Delete fro ...
- Mysql_事务_存储过程_触发器
一.什么是事务? 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit).事务通常由高级数据库操纵语言或编程语言( ...
- Skipper & Tcl 笔记
https://www.cnblogs.com/yeungchie/ ski-db 打开一个文件获取 lib 对象 dbImport set file "layout.gds" s ...
- 数据库纳管平台DBhouse的技术路线与实践
为帮助开发者更好地了解和学习前沿数据库技术,腾讯云数据库特推出"DB · TALK"系列技术分享会,聚焦干货赋能创新,邀请数十位鹅厂资深数据库专家每月和您一起深入探讨云数据库的内核 ...
- 7.Arrays类
1. Arrays类 数组的工具类java.util.Arrays Arrays类中的方法都是static修饰的静态方法,使用的时候可以直接使用类名进行调用 (而不是使用对象)(是"不用&q ...
- 如丝般顺滑:DDD再实践之类目树管理
在上次反思DDD实践之后,在类目树管理项目中再次实践DDD.从需求分析到建模和具体的落地,结合个人体会,都是干货.
- uTools .SRT 转 .VTT 格式转换自动化小工具
不想用网上的转换工具,要有网,先上传,再下载,可能还要看广告.有些工具也不是很方便.打算配合uTools的自动化助手插件搞一个一键格式转换.
- 【简单dfs】Bubble Cup 14 - Finals Online Mirror (Unrated, ICPC Rules, Teams Preferred, Div. 2), problem: (J) Robot Factory,
传送门 Problem - 1600J - Codeforces 题目 题意 给定n行m列, 求每个连通块由多少格子组成,并将格子数从大到小排序输出 对于每个格子都有一个数(0~15),将其转化 ...
- docker基础_Dockerfile
Dockerfile []: https://docs.docker.com/language/python/build-images/ "docker官方文档" 以python为 ...