倒计时2日!基于 Apache DolphinScheduler&TiDB 的交叉开发实践,从编写到调度让你大幅提升效率

当大数据挖掘成为企业赖以生存、发展乃至转型的生命,如何找到一款好软件帮助企业满足需求,成为了许多大数据工程师困扰的问题。但在当下高速发展的大数据领域,光是一款好软件似乎都不足以满足所有场景业务需求,许多企业逐渐将目光转向了技术生态的“外延”——即结合各种场景打造企业适用的技术架构。
那该如何才能打造出一款,用户能够“轻松上手”、“简单应用”的软件呢?Apache DolphinScheduler 联合 TiDB 社区共同举办的Meetup将带给你答案!本周六下午两点,社区也有幸邀请到了数位来自阿里云、国内跨境电商巨头 SHEIN、TiDB 社区等企业的资深大数据工程师与开发者。他们将从数据仓库、数据调度、应用开发、技术外延等话题探讨Apache DolphinScheduler 与 TiDB 两个开源项目的开发实践。

无论你是Apache DolphinScheduler&TiDB的开发工程师还是个人爱好者,来到本次Meetup,相信一定可以解答你的所有疑惑。
报名通道
Apache DolphinScheduler & TiDB 联合 Meetup | 6 月线上直播报名通道已开启,赶快预约吧!
时间:2022-6-18 14:00-16:10
形式:线上直播
点击原文链接或扫描报名二维码(免费):
https://www.slidestalk.com/m/902/dsgongzhonghao 
扫码预约报名

扫码加入群聊
活动议程

抽奖福利环节
01直播间福袋抽奖
共设置两轮抽奖,4个中奖名额。只要参与直播即有机会获得TiDB社区定制充电宝一枚。

02 全场最佳提问
在直播过程中向讲师提出疑问。在直播的最后,讲师会选出本次直播中观众问出的最有价值的3个问题,获奖者将获得 Apache DophinScheduler 定制鼠标垫一枚。

03 问卷调查填写
在直播进行的过程中,直播间会在中场环境放出问卷链接,填写 Meetup 调查问卷,您就有机会获得TiDB定制双肩包和DS定制T恤,随机抽取3位幸运填写人。如果您不巧错过,在本次直播的微信群聊中,您也能找到问卷调查的填写入口。

邀请好友一起参加社区活动直播还有奖品拿,成为社区推广大使,只要邀请人数排在前10都有奖,丰富奖品送到手软!听说这次一等奖价值人民币300+,动动手就能拿(大佬们不一定参加),这次我们不靠运气,靠实力拿奖(薅羊毛)!

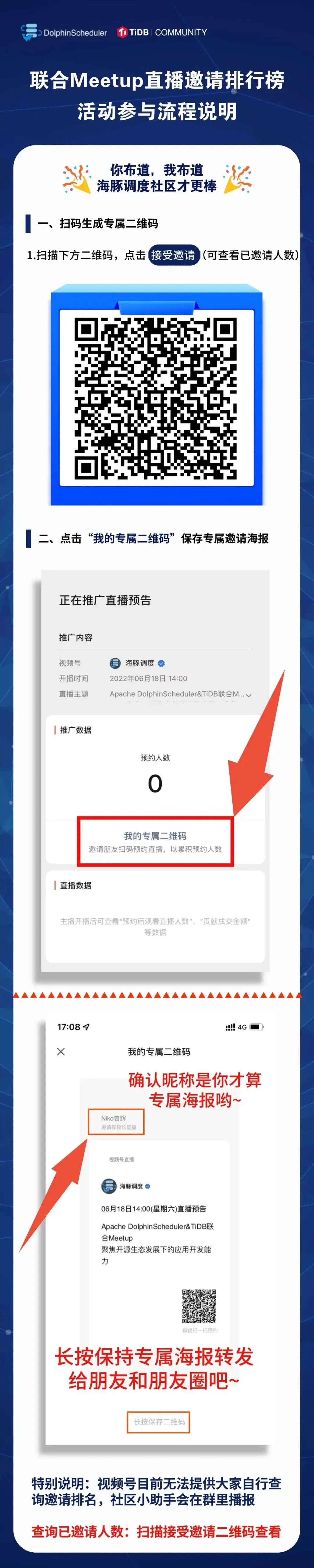
618Meetup邀请排行榜火热进行中~
截止6月15日18:00邀请排名:
第一名:公侯伯子男的侯 | 邀请人数47个
第二名:wind | 邀请人数23个
第三名:Adkins Han | 邀请人数14个
第四名:自由 | 邀请人数11个
第五名:杨启煜 | 邀请人数10个
第六名:游语 | 邀请人数8个
第七名:Mr Chestnuts | 邀请人数7个
第八名:Any | 邀请人数5个
第九名:東20222022 | 邀请人数5个
第十名:進豪 | 邀请人数5个
活动排名于6月18日中午12点截止
欢迎大家参与6月18日Apache DolphinScheduler &TiDB联合的线上交流会,下午14:00,我们不见不散!
倒计时2日!基于 Apache DolphinScheduler&TiDB 的交叉开发实践,从编写到调度让你大幅提升效率的更多相关文章
- 倒计时0日!Apache DolphineScheduler4月 Meetup 大佬手把手教你大数据开发,离线调度
随着互联网技术和信息技术的发展,信息的数据化产生了许多无法用常规工具量化.处理和捕捉的数字信息.面对多元的数据类型,海量的信息价值,如何有效地对大数据进行挖掘分析,对大数据工作流进行调度,是保障企业大 ...
- Apache DolphinScheduler 的持续集成方向实践
今天给大家带来的分享是基于 Apache DolphinScheduler 的持续集成方向实践,分享的内容主要为以下六点: " 研发效能 DolphinScheduler CI/CD 应用案 ...
- Apache DolphinScheduler&TiDB联合Meetup | 聚焦开源生态发展下的应用开发能力
在软件开发领域有一个流行的原则:Don't Repeat Yourself(DRY),翻译过来就是:不要重复造轮子.而开源项目最基本的目的,其实就是为了不让大家重复造轮子. 尤其是在大数据这样一个高速 ...
- 4 亿用户,7W+ 作业调度难题,Bigo 基于 Apache DolphinScheduler 巧化解
点击上方 蓝字关注我们 ✎ 编 者 按 成立于 2014 年的 Bigo,成立以来就聚焦于在全球范围内提供音视频服务.面对 4 亿多用户,Bigo 大数据团队打造的计算平台基于 Apache Dolp ...
- 挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 精彩回顾 近期,初灵科技的大数据开发工程师钟霈合在社区活动的线 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于React Native的58 APP开发实践
React Native在iOS界早就炒的火热了,随着2015年底Android端推出后,一套代码能运行于双平台上,真正拥有了Hybrid框架的所有优势.再加上Native的优秀性能,让越来越多的公司 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
随机推荐
- Python数据分析--Numpy常用函数介绍(2)
摘要:本篇我们将以分析历史股价为例,介绍怎样从文件中载入数据,以及怎样使用NumPy的基本数学和统计分析函数.学习读写文件的方法,并尝试函数式编程和NumPy线性代数运算,来学习NumPy的常用函数. ...
- 第06组 Beta冲刺 (5/5)
目录 1.1 基本情况 1.2 冲刺概况汇报 1.郝雷明 2. 方梓涵 3.曾丽莉 4.黄少丹 5. 董翔云 6.鲍凌函 7.杜筱 8.詹鑫冰 9.曹兰英 10.吴沅静 1.3 冲刺成果展示 1.1 ...
- SpringBoot+Mybatis-Plus整合Sharding-JDBC5.1.1实现单库分表【全网最新】
一.前言 小编最近一直在研究关于分库分表的东西,前几天docker安装了mycat实现了分库分表,但是都在说mycat的bug很多.很多人还是倾向于shardingsphere,其实他是一个全家桶,有 ...
- 看看CabloyJS工作流引擎是如何实现Activiti边界事件的
CabloyJS内置工作流引擎的基本介绍 1. 由来 众所周知,NodeJS作为后端开发语言和运行环境,支持高并发.开发效率高,有口皆碑,但是大多用于数据CRUD管理.中间层聚合和中间层代理等工具场景 ...
- 大功率超远距离lora无线数传电台,多级中继功能
一.在无线通信领域,LoRa是目前市场最被看好的技术之一.随着新一代LoRa调制技术的升级,市场对LoRa技术的认知.认可逐步提高,基于LoRa调制技术开发的产品得到更广泛的应用.受益于其超低的接收灵 ...
- 开发工具-Typora编辑器下载地址
更新记录 2022年6月10日 完善标题. 比较好用的Markdown编辑器了,哈哈. https://typoraio.cn/
- 如何提高访问 GitHub 的速度
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月11日. 因为一些特殊的原因,国内访问Github的速度确实比较慢.国内访问Github经常会出现连接不上.图片加载不出来.文件无 ...
- Markdown常见基本语法
标题 -方式一:使用警号 几个警号就是几级标题,eg: # 一级标题 -方式二: 使用快捷键 ctrl+数字 几级标题就选其对应的数字, eg: ctrl+2(二级标题) 子标题 -方式一: 使用星号 ...
- rpm构建流程学习总结
rpm构建流程 学习链接: b站马哥: https://www.bilibili.com/video/BV1ai4y1N7gp RedHat: https://access.redhat.com/do ...
- 第五章、Linux网络服务之yum仓库
目录 一.yum仓库简介 二.yum配置文件 1yum主配置文件 2日志文件 三.yum命令详解 1查询软件包命令 2查询软件包组命令 3yum安装升级 4 软件卸载 四.搭建yum仓库 本地仓库 h ...