CSAPP 之 CacheLab 详解
前言
本篇博客将会介绍 CSAPP 之 CacheLab 的解题过程,分为 Part A 和 Part B 两个部分,其中 Part A 要求使用代码模拟一个高速缓存存储器,Part B 要求优化矩阵的转置运算。
解题过程
Part A
题目要求
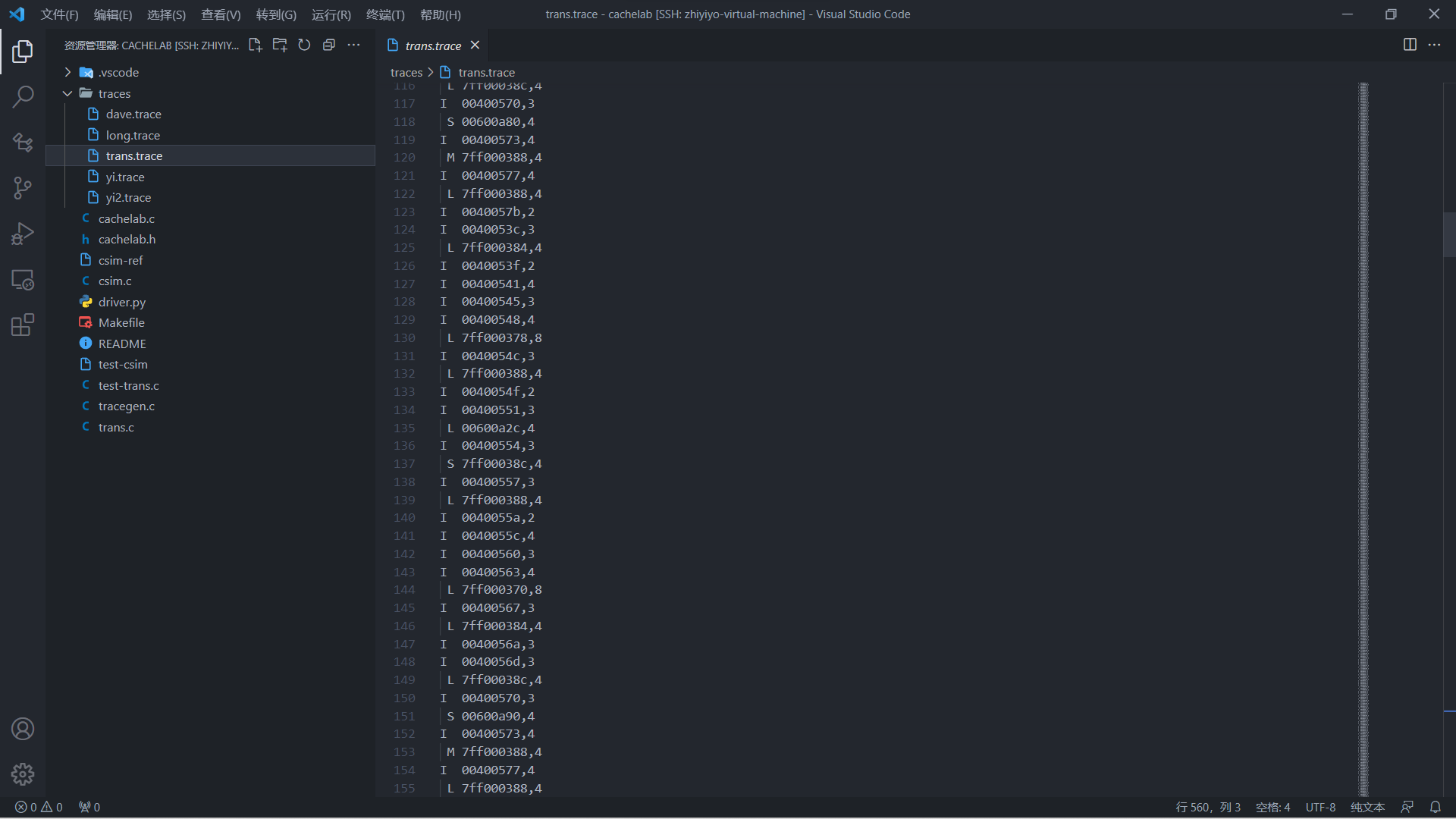
Part A 给出了一些后缀名为 trace 的文件,文件中的内容如下图所示,其中每一行代表一次对缓存的操作,格式为 [空格] 操作 地址,数据大小,其中操作的类型有以下几种:
- I:取指令操作
- L:读数据操作
- S:写数据操作
- M:修改数据操作,比如先读一次数据再写一次数据
只有 I 操作没有带前置空格,其他操作都有一个前置空格。地址为 64 位,数据大小以字节为单位。
Part A 要求实现的缓存存储器的行为和 csim-ref 一致,使用 LRU 算法进行替换操作。CSAPP 中指出高速缓存存储器可以用四元组 \((S, E, B,m)\) 来描述,其中 \(S=2^s\) 为组数,\(E\) 为行数,\(B=2^b\) 为块的大小,\(m\) 为地址的位数,具体结构如下图所示:
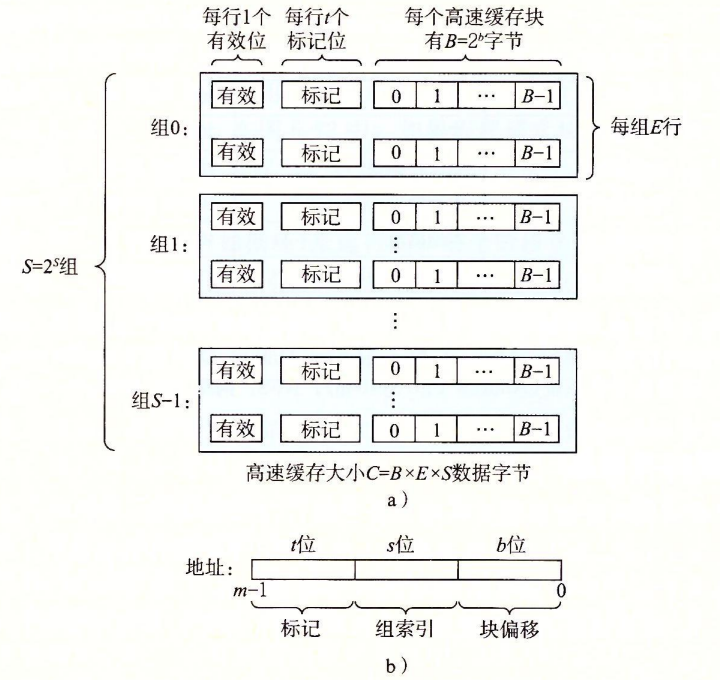
对于模拟的高速缓存,至少需要接受 4 个参数:
-s:组索引的位数-E:行数-b:块大小 \(B=2^b\) 中的 \(b\)-t:trace文件的路径
根据给定的 trace 文件,模拟的高速缓存 csim 需要给出命中次数、未命中次数和替换次数,只有和 csim-ref 的次数一样才能拿到分数。
代码
我们首先定义一个结构,用来代表高速缓存中的行,由于题目没要求存储数据,所以结构中并没有包含代表缓存块的数组,同时题目要求使用 LRU 替换算法,所以包含一个 time 代表与上次访问相隔多久:
typedef struct {
int valid;
int tag;
int time;
} CacheLine, *CacheSet, **Cache;
接着完成入口函数,进行命令行参数解析和模拟工作:
#include <assert.h>
#include <getopt.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "cachelab.h"
int hit, miss, evict;
int s, S, E, b;
char filePath[100];
Cache cache;
int main(int argc, char* argv[]) {
int opt;
while ((opt = getopt(argc, argv, "s:E:b:t:")) != -1) {
switch (opt) {
case 's':
s = atoi(optarg);
S = 1 << s;
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
strcpy(filePath, optarg);
break;
}
}
mallocCache();
simulate();
freeCache();
printSummary(hit, miss, evict);
return 0;
}
由于 \(s\)、\(E\) 和 \(b\) 会变,所以需要使用 malloc 函数来在堆上分配空间,使用结束之后还得将这部分空间释放掉:
/* 动态分配缓存空间 */
void mallocCache() {
cache = (Cache)malloc(S * sizeof(CacheSet));
assert(cache);
for (int i = 0; i < S; ++i) {
cache[i] = (CacheSet)malloc(E * sizeof(CacheLine));
assert(cache[i]);
}
}
/* 释放缓存空间 */
void freeCache() {
for (int i = 0; i < S; ++i) {
free(cache[i]);
}
free(cache);
}
根据 trace 文件进行模拟的函数如下所示,其中 I 和 S 只需访问缓存一次,而 M 需要两次,且每进行一次操作,就得更新一次时间戳:
/* 模拟缓存读写操作*/
void simulate() {
FILE* file = fopen(filePath, "r");
assert(file);
char op;
uint64_t address;
int size;
while (fscanf(file, " %c %lx,%d", &op, &address, &size) > 0) {
switch (op) {
case 'M':
accessCache(address);
case 'L':
case 'S':
accessCache(address);
break;
}
lruUpdate();
}
fclose(file);
}
/* 更新访问时间 */
void lruUpdate() {
for (int i = 0; i < S; ++i) {
for (int j = 0; j < E; ++j) {
if (cache[i][j].valid) {
cache[i][j].time++;
}
}
}
}
访问缓存的代码如下所示,首先根据组索引选出组,接着行匹配,只有有效位为 1 且 tag 与地址中的 \(t\) 位标记相同才说明缓冲击中,不然就是未击中。在未击中的情况下,需要将数据写入空行中,如果没有空行就要运行 LRU 算法进行替换。
/* 访问缓存 */
void accessCache(uint64_t address) {
int tag = address >> (b + s);
uint64_t mask = ((1ULL << 63) - 1) >> (63 - s);
CacheSet cacheSet = cache[(address >> b) & mask];
// 缓存击中
for (int i = 0; i < E; ++i) {
if (cacheSet[i].valid && cacheSet[i].tag == tag) {
hit++;
cacheSet[i].time = 0;
return;
}
}
miss++;
// 有空位,直接写入
for (int i = 0; i < E; ++i) {
if (!cacheSet[i].valid) {
cacheSet[i].valid = 1;
cacheSet[i].tag = tag;
cacheSet[i].time = 0;
return;
}
}
// 没有空位,只能使用 LRU 算法进行替换
evict++;
int evictIndex = 0;
int maxTime = 0;
for (int i = 0; i < E; ++i) {
if (cacheSet[i].time > maxTime) {
maxTime = cacheSet[i].time;
evictIndex = i;
}
}
cacheSet[evictIndex].tag = tag;
cacheSet[evictIndex].time = 0;
}
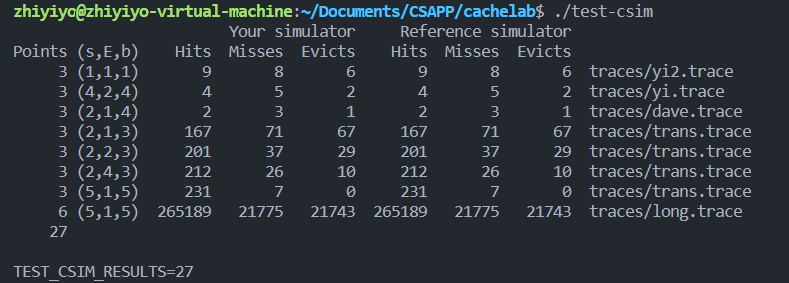
最终运行结果如下,发现模拟结果和参考答案一致:
Part B
Part B 给出了最原始的转置操作代码:
void trans(int M, int N, int A[N][M], int B[M][N]) {
int i, j, tmp;
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
题目要求针对 \(32\times 32\)、\(64\times 64\) 和 \(61\times 67\) 这三种维度的矩阵进行优化,同时给出了以下两点友情提示:
- 使用分块技术进行优化
- 对角线上的元素会引发冲突未击中
由于高速缓存的 \(S=2^s=32\)、\(E=1\)、\(B=2^b=32\),且矩阵中的元素为 int 类型,缓存的每行可以装入 8 个整数,所以对于 \(32\times 32\) 的矩阵,分块大小取为 8,代码如下所示:
for (int i = 0; i < N; i += 8)
for (int j = 0; j < M; j += 8)
for (int ii = i; ii < i + 8; ++ii)
for (int jj=j; jj < j + 8; ++jj)
B[jj][ii] = A[ii][jj];
测试效果如下图所示,发现未命中次数为 343 次,而满分要求未命中小于 300 次:

根据友情提示,我们应该避免对角线上元素原地转置引发的冲突未命中问题,所以使用循环展开直接访问行中的 8 个元素并赋值给 \(B\),将代码修改如下:
int a, b, c, d, e, f, g, h;
for (int i = 0; i < N; i += 8) {
for (int j = 0; j < M; j += 8) {
for (int ii = i; ii < i + 8; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
e = A[ii][j + 4];
f = A[ii][j + 5];
g = A[ii][j + 6];
h = A[ii][j + 7];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
B[j + 4][ii] = e;
B[j + 5][ii] = f;
B[j + 6][ii] = g;
B[j + 7][ii] = h;
}
}
}
再次测试,未命中次数为 287 次:

对于 \(64\times 64\) 大小的矩阵,如果同样使用 \(8\times 8\) 的分块,会发现命中次数和未分块情况下一模一样,为 4723 次左右。所以这里把分块换成 \(4\times 4\) 的,代码如下所示:
int a, b, c, d;
for (int i = 0; i < N; i += 4) {
for (int j = 0; j < M; j += 4) {
for (int ii = i; ii < i + 4; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
}
}
}
测试结果如下图所示,未命中次数为 1699 次,虽然没有达到低于 1300 次的满分要求(但是至少拿了一点分数):

最后是 \(61\times 67\) 维度的矩阵,因为这个维度不能被 8 整除,所以先使用分块处理一部分元素,对剩下的元素再单独处理:
int a, b, c, d, e, f, g, h;
int n = 8 * (N / 8);
int m = 8 * (M / 8);
for (int i = 0; i < n; i += 8) {
for (int j = 0; j < m; j += 8) {
for (int ii = i; ii < i + 8; ++ii) {
a = A[ii][j];
b = A[ii][j + 1];
c = A[ii][j + 2];
d = A[ii][j + 3];
e = A[ii][j + 4];
f = A[ii][j + 5];
g = A[ii][j + 6];
h = A[ii][j + 7];
B[j][ii] = a;
B[j + 1][ii] = b;
B[j + 2][ii] = c;
B[j + 3][ii] = d;
B[j + 4][ii] = e;
B[j + 5][ii] = f;
B[j + 6][ii] = g;
B[j + 7][ii] = h;
}
}
}
// 处理剩余部分
for (int i = 0; i < n; i++) {
for (int j = m; j < M; j++) {
B[j][i] = A[i][j];
}
}
for (int i = n; i < N; i++) {
for (int j = 0; j < M; j++) {
B[j][i] = A[i][j];
}
}
测试结果如下图所示,未命中次数为 2093,接近满分 2000:

总结
通过这次实验,可以加深对存储器层次结构和高速缓存工作原理的理解,为后续学习打下铺垫(经典实验报告总结)。以上~~
CSAPP 之 CacheLab 详解的更多相关文章
- CSAPP 之 BombLab 详解
前言 本篇博客将会展示 CSAPP 之 BombLab 的拆弹过程,粉碎 Dr.Evil 的邪恶阴谋.Dr.Evil 的替身,杀手皇后,总共设置了 6 个炸弹,每个炸弹对应一串字符串,如果字符串错误, ...
- CSAPP 之 DataLab 详解
前言 本篇博客将会剖析 CSAPP - DataLab 各个习题的解题过程,加深对 int.unsigned.float 这几种数据类型的计算机表示方式的理解. DataLab 中包含下表所示的 12 ...
- CSAPP 之 AttackLab 详解
前言 本篇博客将会介绍 CSAPP 之 AttackLab 的攻击过程,利用缓冲区溢出错误进行代码注入攻击和 ROP 攻击.实验提供了以下几个文件,其中 ctarget 可执行文件用来进行代码注入攻击 ...
- CSAPP 之 ShellLab 详解
前言 本篇博客将会详细介绍 CSAPP 之 ShellLab 的完成过程,实现一个简易(lou)的 shell.tsh 拥有以下功能: 可以执行外部程序 支持四个内建命令,名称和功能为: quit:退 ...
- 《TCP/IP 详解 卷1:协议》第 10 章:用户数据报协议
引言 UDP 稍微扩展了IP协议,使得包可以在进程间传送,而不仅仅是在主机件.--<CSAPP> IP 数据报是指 IP 层端到端的传输单元.分组(packet)是 IP 层和链路层的传输 ...
- Linq之旅:Linq入门详解(Linq to Objects)
示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细介绍 .NET 3.5 中引入的重要功能:Language Integrated Query(LINQ,语言集 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- EntityFramework Core 1.1 Add、Attach、Update、Remove方法如何高效使用详解
前言 我比较喜欢安静,大概和我喜欢研究和琢磨技术原因相关吧,刚好到了元旦节,这几天可以好好学习下EF Core,同时在项目当中用到EF Core,借此机会给予比较深入的理解,这里我们只讲解和EF 6. ...
- Java 字符串格式化详解
Java 字符串格式化详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 文中如有纰漏,欢迎大家留言指出. 在 Java 的 String 类中,可以使用 format() 方法 ...
随机推荐
- Collection单列集合的继承关系(集合的层次结构)
- 1108. IP 地址无效化
给你一个有效的 IPv4 地址 address,返回这个 IP 地址的无效化版本. 所谓无效化 IP 地址,其实就是用 "[.]" 代替了每个 ".". 示例 ...
- 6_稳定性_李雅普诺夫_Lyapunov
李雅普诺夫方法参考
- C# Coding Conventions, Coding Standards & Best Practices
C# Coding Conventions, Coding Standards & Best Practices Cui, Chikun Overview Introduction This ...
- google fonts 国内使用解决方案
由于众所周知的原因,国内使用google font库有很大的问题. 解决方案1:使用国内镜像如360网站卫士常用前端公共库CDN服务 优点:使用方便 缺点:目标用户包含国外的开发者,不清楚国外用户的加 ...
- ASP.NET WebAPI解决跨域问题
跨域是个很蛋疼的问题...随笔记录一下... 一.安装nuget包:Microsoft.AspNet.WebApi.Core 二.在Application_Start方法中启用跨域 1 protect ...
- javaweb图书管理系统之不同用户跳转不同页面
关于分级自测题,我们知道该系统一共分为两个角色,一个是读者,一个是管理员,我们需要根据不同用户去到不同的页面,所以我们需要写一个登陆界面. 本文先写这个功能的实现,该功能主要在servlet里面实现. ...
- Ubuntu安装开发者平台Backstage
Ubuntu安装开发者平台Backstage 什么是Backstage? Backstage是一个构建开发者门户的开源平台.通过支持一个集中的软件分类,Backstage可以保存并发布你的微服务和基础 ...
- LC-454
题目 给你四个整数数组 nums1.nums2.nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 <= i, j, k, l < ...
- String类 的基本用法
1.String 对象的创建 String对象的创建有两种方式. 第1 种方式就是我们最常见的创建字符串的方式: String str1 = "Hello, 慕课网"; 第 2 种 ...