(数据科学学习手札136)Python中基于joblib实现极简并行计算加速
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
我们在日常使用Python进行各种数据计算处理任务时,若想要获得明显的计算加速效果,最简单明了的方式就是想办法将默认运行在单个进程上的任务,扩展到使用多进程或多线程的方式执行。
而对于我们这些从事数据分析工作的人员而言,以最简单的方式实现等价的加速运算的效果尤为重要,从而避免将时间过多花费在编写程序上。而今天的文章费老师我就来带大家学习如何利用joblib这个非常简单易用的库中的相关功能,来快速实现并行计算加速效果。
2 使用joblib进行并行计算
作为一个被广泛使用的第三方Python库(譬如scikit-learn项框架中就大量使用joblib进行众多机器学习算法的并行加速),我们可以使用pip install joblib对其进行安装,安装完成后,下面我们来学习一下joblib中有关并行运算的常用方法:
2.1 使用Parallel与delayed进行并行加速
joblib中实现并行计算只需要使用到其Parallel和delayed方法即可,使用起来非常简单方便,下面我们直接以一个小例子来演示:
joblib实现并行运算的思想是将一组通过循环产生的串行计算子任务,以多进程或多线程的方式进行调度,而我们针对自定义的运算任务需要做的仅仅是将它们封装为函数的形式即可,譬如:
import time
def task_demo1():
time.sleep(1)
return time.time()
接着只需要像下面的形式一样,为Parallel()设置相关参数后,衔接循环创建子任务的列表推导过程,其中利用delayed()包裹自定义任务函数,再衔接()传递任务函数所需的参数即可,其中n_jobs参数用于设置并行任务同时执行的worker数量,因此在这个例子中可以看到进度条是按照4个一组递增的,可以看到最终时间开销也达到了并行加速效果:
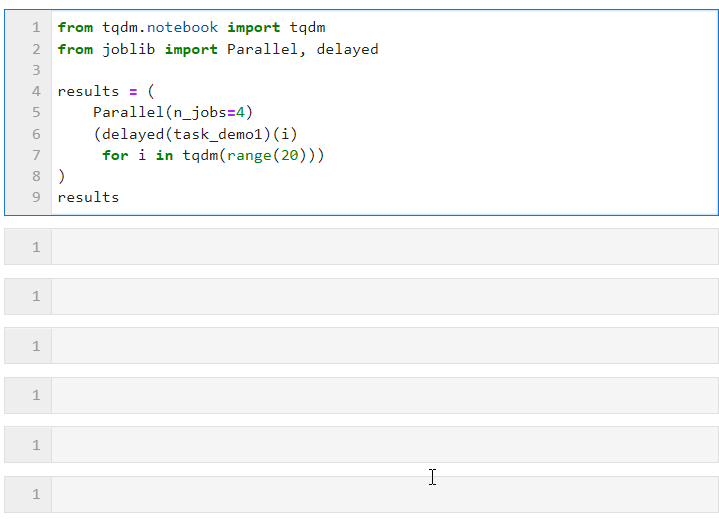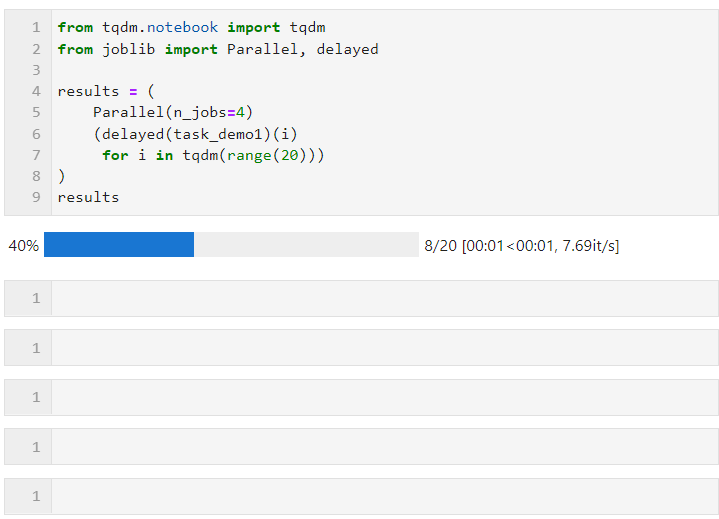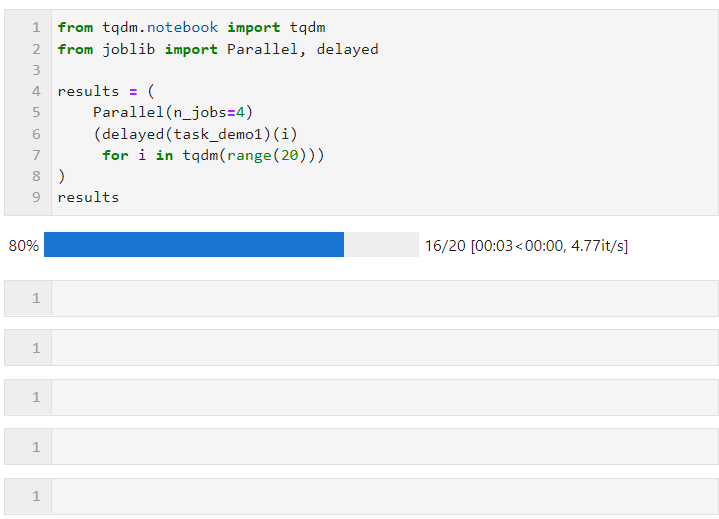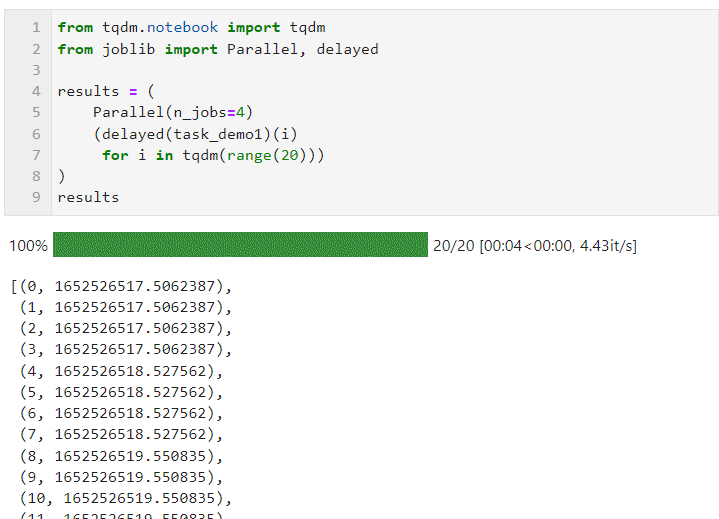
其中可以根据计算任务以及机器CPU核心数具体情况为Parallel()调节参数,核心参数有:
- backend:用于设置并行方式,其中多进程方式有
'loky'(更稳定)和'multiprocessing'两种可选项,多线程有'threading'一种选项。默认为'loky' - n_jobs:用于设置并行任务同时执行的worker数量,当并行方式为多进程时,
n_jobs最多可设置为机器CPU逻辑核心数量,超出亦等价于开启全部核心,你也可以设置为-1来快捷开启全部逻辑核心,若你不希望全部CPU资源均被并行任务占用,则可以设置更小的负数来保留适当的空闲核心,譬如设置为-2则开启全部核心-1个核心,设置为-3则开启全部核心-2个核心
譬如下面的例子,在我这台逻辑核心数为8的机器上,保留两个核心进行并行计算:
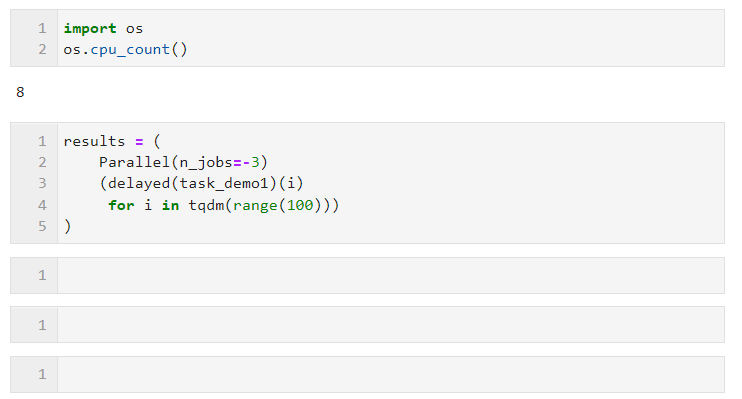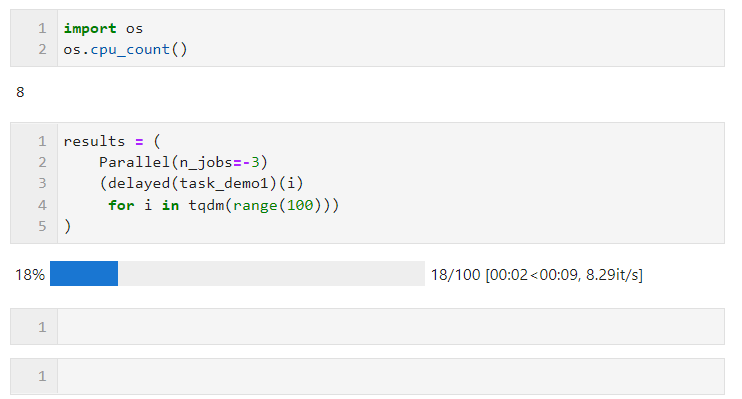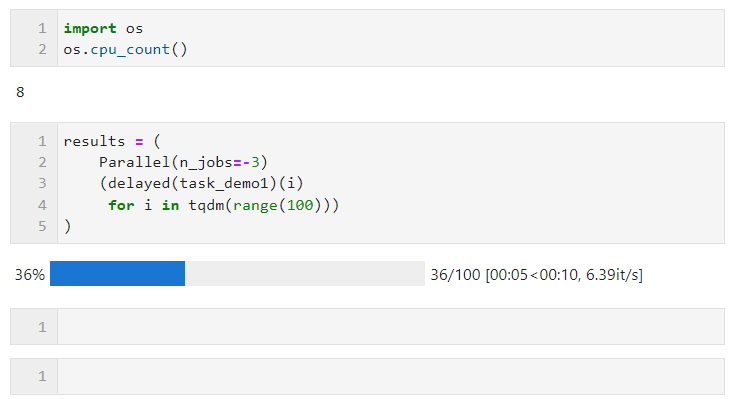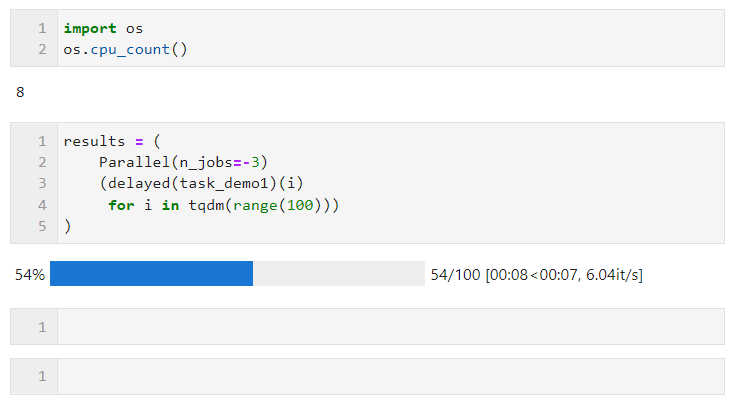
关于并行方式的选择上,由于Python中多线程时全局解释器锁的限制,如果你的任务是计算密集型,则推荐使用默认的多进程方式加速,如果你的任务是IO密集型譬如文件读写、网络请求等,则多线程是更好的方式且可以将n_jobs设置的很大,举个简单的例子,可以看到,通过多线程并行,我们在5秒的时间里完成了1000次请求,远快于单线程17秒请求100次的成绩:
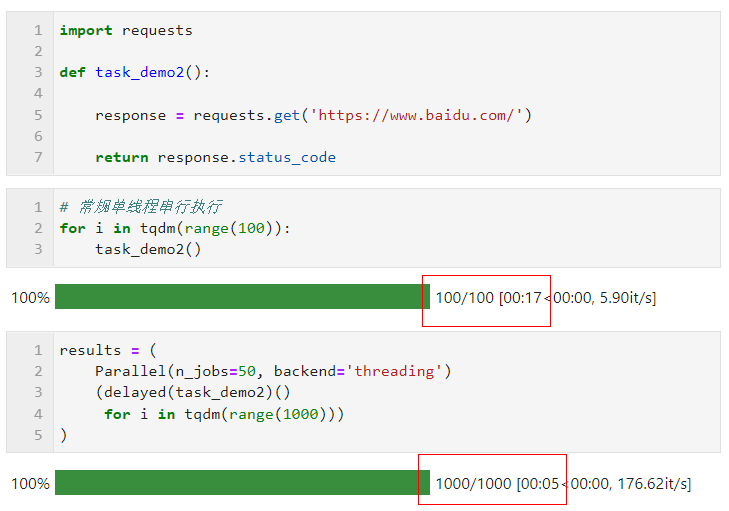
你可以根据自己实际任务的不同,好好利用joblib来加速你的日常工作。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札136)Python中基于joblib实现极简并行计算加速的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
随机推荐
- servlet中的ServletConfig对象
ServletConfig对象对应web.xml文件中的<servlet>节点.当Tomcat初始化一个Servlet时,会创建ServletConfig对象,并将该Servlet的配置信 ...
- 关于css布局、居中的问题以及一些小技巧
CSS的两种经典布局 左右布局 一栏定宽,一栏自适应 <!-- html --> <div class="left">定宽</div> < ...
- 使用Google Closure Compiler高级压缩Javascript代码
背景 前端开发中,特别是移动端,Javascript代码压缩已经成为上线必备条件. 如今主流的Js代码压缩工具主要有: 1)Uglify http://lisperator.net/uglifyjs/ ...
- html5 canvas基础10点
本文主要讲解下一些canvas的基础 1.<canvas id="canvas">若此浏览器不支持canvas会显示该文字</canvas> //创建个ht ...
- 关于css中选择器的小归纳(一)
关于css中选择器的小归纳 一.基本选择器 基本选择器是我们平常用到的最多的也是最便捷的选择器,其中有元素选择器(类似于a,div,body,ul),类选择器(我们在HTML标签里面为其添加的clas ...
- 前端面试题整理——webpack相关考点
webpack是开发工具,面试考点重点在配置和使用,原理理解不需要太深. 一.基本配置 1.拆分配置和merge 将公共配置跟dev和prod的配置拆分,然后通过webpack-merge对配置进行整 ...
- ES6-11学习笔记--let
新声明方式:let 1.不属于顶层对象 window 2.不允许重复声明 3.不存在变量提升 4.暂时性死区 5.块级作用域 原来var声明: var a = 5; console.log(a); ...
- 【每日日报】第四十七天---<div>
1 学习HTML HTML <div> 元素是块级元素,它可用于组合其他 HTML 元素的容器. <div> 元素没有特定的含义.除此之外,由于它属于块级元素,浏览器会在其前后 ...
- SQList基础+ListView基本使用
今日所学: SQList基础语法 SDList下载地址 SQLite Download Page SQList安装教程SQLite的安装与基本操作 - 极客开发者-博客 ListView用法 没遇到什 ...
- video踩坑
查看以及修改video控件样式,原文地址:https://blog.csdn.net/z2181745/article/details/82531686 chrome浏览器,F12调出控制台左上角三点 ...