kaggle竞赛分享:NFL大数据碗(上篇)
kaggle竞赛分享:NFL大数据碗 - 上
竞赛简介
一年一度的NFL大数据碗,今年的预测目标是通过两队球员的静态数据,预测该次进攻推进的码数,并转换为该概率分布;
竞赛链接
https://www.kaggle.com/c/nfl-big-data-bowl-2020
项目链接,该项目代码已经public,大家可以copy下来直接运行
https://www.kaggle.com/holoong9291/nfl-big-data-bowl
github仓库链接,更多做的过程中的一些思考、问题等可以在我的github中看到
一些基本概念
- 美式足球:进攻方目的是通过跑动、传球等尽快抵达对方半场,也就是达阵,而防守方的目的则是相反,尽全力去阻止对方的前进以及尽可能断球;
- 球场长120码(109.728米),宽53码(48.768米),周长是361.992米;
- 球员:双方场上共22人,进攻方11人,防守方11人,进攻方持球;
- 进攻机会:进攻方共有四次机会,需要推进至少十码;
- 进攻方:进攻方的职责是通过四次机会,尽可能的向前推进10码或者达阵,以获得下一个四次机会,否则就需要交出球权;
- 防守方:防守方则是相反,尽可能的阻止对方前进,如果能够断球那更好,直接球权交换;
- handoff:传球;
- snap:发球;
- 橄榄球基本知识点我了解;
- QB:四分卫,通常是发球后接球的那个人,一般口袋阵的中心,但是也不乏有像拉马尔-杰克逊这样的跑传结合的QB,目前古典QB代表是新英格兰爱国者NE的汤姆-布雷迪;
- RB:跑卫,通常发球后进行冲刺、摆脱等,试图接住本方QB的传球后尽可能远的冲刺;
球场码线图

一个常见的开球前站位图

数据字段介绍、绘图分析

字段信息:
GameId- a unique game identifier - 比赛IDPlayId- a unique play identifier -Team- home or away - 主场还是客场X- player position along the long axis of the field. See figure below. - 在球场的位置xY- player position along the short axis of the field. See figure below. - 在球场的位置yS- speed in yards/second - 速度,码/秒A- acceleration in yards/second^2Dis- distance traveled from prior time point, in yardsOrientation- orientation of player (deg) 球员面向Dir- angle of player motion (deg) 球员移动方向NflId- a unique identifier of the player - NFL球员IDDisplayName- player's name - 球员名JerseyNumber- jersey number - 球衣号码Season- year of the seasonYardLine- the yard line of the line of scrimmageQuarter- game quarter (1-5, 5 == overtime) - 当前是第几节比赛,5为加时GameClock- time on the game clock - 比赛时间PossessionTeam- team with possession - 持球方Down- the down (1-4) - 达阵Distance- yards needed for a first down - 距离拿首攻所需距离FieldPosition- which side of the field the play is happening onHomeScoreBeforePlay- home team score before play started - 赛前主队分数VisitorScoreBeforePlay- visitor team score before play started - 赛前客队分数NflIdRusher- the NflId of the rushing playerOffenseFormation- offense formationOffensePersonnel- offensive team positional groupingDefendersInTheBox- number of defenders lined up near the line of scrimmage, spanning the width of the offensive lineDefensePersonnel- defensive team positional groupingPlayDirection- direction the play is headedTimeHandoff- UTC time of the handoff - 传球时间TimeSnap- UTC time of the snap - 发球时间Yards- the yardage gained on the play (you are predicting this) - 目标PlayerHeight- player height (ft-in) - 球员身高PlayerWeight- player weight (lbs) - 球员体重PlayerBirthDate- birth date (mm/dd/yyyy) - 生日、岁数PlayerCollegeName- where the player attended college - 大学Position- the player's position (the specific role on the field that they typically play) - 场上位置HomeTeamAbbr- home team abbreviation - 主队缩写VisitorTeamAbbr- visitor team abbreviation - 客队缩写Week- week into the seasonStadium- stadium where the game is being played - 体育场Location- city where the game is being player - 城市StadiumType- description of the stadium environment - 体育场类型Turf- description of the field surface - 草皮GameWeather- description of the game weather - 比赛天气Temperature- temperature (deg F) - 温度Humidity- humidity - 湿度WindSpeed- wind speed in miles/hour - 风速WindDirection- wind direction - 风向
定义问题
回归预测,Target是码数,但是最终结果需要转换为条件概率分布;
Evaluation Function
Continuous Ranked Probability Score (CRPS);
项目流程分享
定义模型输出结果到概率分布的转换类
这里竞赛需要的并不是具体的码数,而是码数对应的概率分布,也就是所有码数在一次进攻中的概率,所以需要这样一个转换类,如下:

缺失值处理
训练数据上看,缺失情况不严重,缺失字段如下:
这里对缺失的处理根据不同类型的字段采取不同的方式:
- 天气相关字段,由于天气具有连续性,因此采用前向填充较为合理:
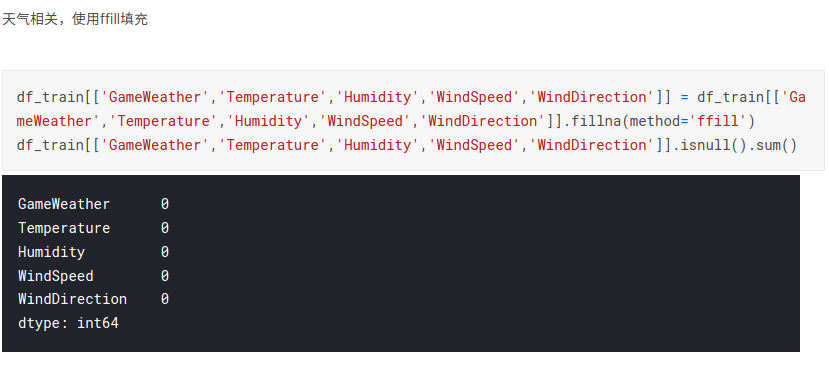
- 体育场类型,严格来说应该是通过baidu、google等去搜索,但是NFL的相关信息baidu搜到的太少,google上看也没找到,所以用取值最多的来填充:
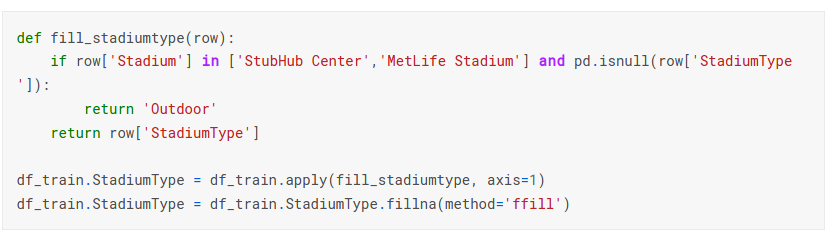
- FieldPosition,这个字段的缺失不同于以上两个,通过对数据的分析,它的缺失源于在中线开球时,此时没法明确指出是在哪个半场,所以缺失,这里用一个特别的值来填充,“Middle”;
- OffenseFormation,进攻队形,实际缺失了5条,统一用取值最多的来填充即可;
- DefendersInTheBox,防守方在混战线附近的人数,通过观察数据可以通过球队、对手、以及防守组成员来填充DefendersInTheBox:
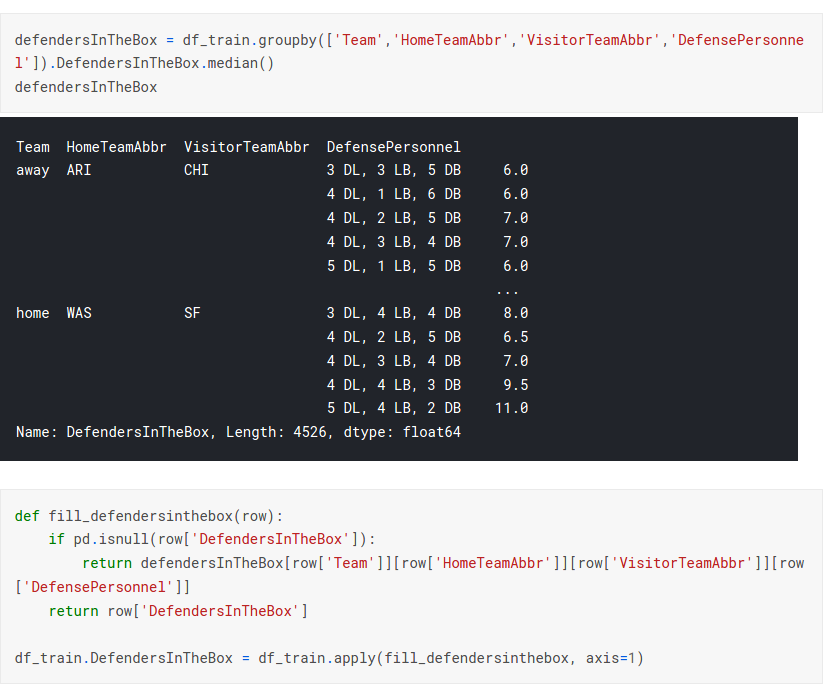
- Orientation 球员方位-角度,Dir 球员移动-角度,只有一条缺失,且该球员正常上场了的,应该是技术型缺失,用mean填充即可;
异常、重复等处理
- StadiumType:存在不同名但是同意思的情况,这里要整理后归一处理,避免对模型产生干扰;

- 存在PossessionTeam既不是HomeTeamAbbr也不是VisitorTeamAbbr,共有120场比赛中出现这种情况;

- 草皮字段处理;
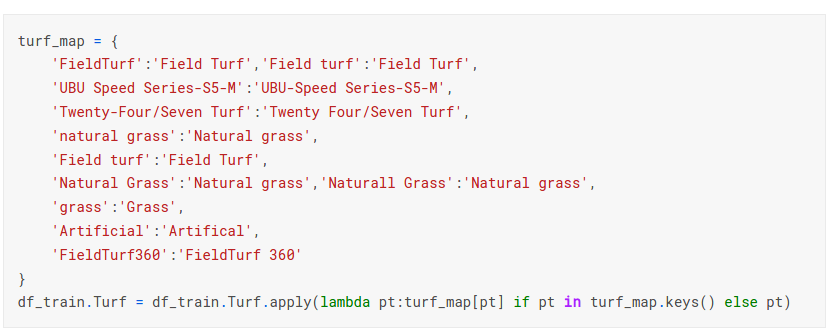
- Location字段也存在重复含义但是不同值的情况需要归一;

EDA:探索性数据分析
下面是通过matplotlib绘制的一场比赛中的多个进攻防守回合的展示图,黑色三角形是QB,红色是进攻方,淡蓝色是防守方:
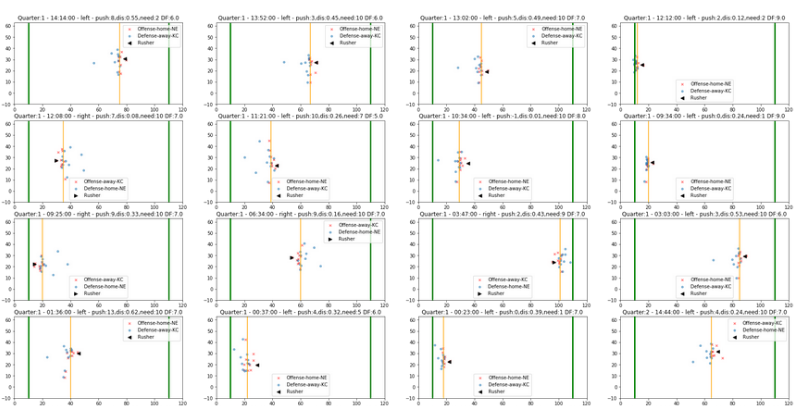
可以清楚的看到每次进攻不同的站位,以及整个推进的过程,这里我记录的一份NFL比赛手记,爱国者vs乌鸦,新老QB的正面交锋,非常精彩,可以对照着看一下;
特征工程
这里由于我个人对橄榄球的了解也并不是很多(强推电影弱点),所以特征工程部分做的并不是很好,从结果看Top61%也反映除了这个问题,但是我依然觉得具有一定的参考意义,下面我会分析每个新特征构建的目的,以及我的想法;
- WindSpeed,WindDirection:直观看,对比赛影响应该不大,可能存在某些传球手喜欢顺风或者逆风,但是影响应该很小,所以我这里选择丢弃;
- PlayerHeight:转为球员身高,身高无疑对比赛是有关系的;
- PlayerBirthDate:生日转为岁数,岁数可以表示一个球员的身体状况是否处于巅峰等;
- 开球到传球的时间 - (TimeHandoff-TimeSnap):我认为这一时间的长短一定程度上决定了战术的选择,而战术肯定是影响了进攻码数的;

- 比赛进行时间 - (15-GameClock+Quarter*15):比赛进行了多久对球员们的体力、战术选择等都有很大影响;

- Position_XX:用于统计当前进攻中场上各个角色的人数组成,这也跟战术选择密切关系;

- goal区:码线对方半场10码或10码内,此时距离达阵不到10码,一般这种情况下战术选择会变得与之前不太一样,不管是防守方还是进攻方;

- 首攻危险:这是我自己定义的,即当目前进攻方仅有一次进攻机会,而所需继续进攻的码数大于5时,我认为是有首攻危险的,此时很可能丢失球权,down为4,且distance大于5;

- 距离达阵还有多少码:一般距离的不同,防守方的防守策略会有不同,距离较远一般会较为保守,距离较近则会比较激进;

- 其余object特征做label encode处理;
聚合数据并整理聚体统计特征
这里要注意,训练数据每一行表示的是一次进攻中一个球员的情况,我们预测的是每次进攻,因此需要把每22条数据聚合为1条,这个过程中会有一些数据统计特征的产生,下面简介整个流程:
- 延迟特征:即每个球员分别在之后0.5s,1s,2s,3s后的位置信息;
- 平均特征:分为进攻方和防守方,平均速度、平均加速度、平均身高、平均体重、平均年龄;
- 持球人为中心特征:当前、延迟0.5s,1s,2s,3s时,进攻方和防守方球员与他的平均距离;
- 持球人为中心特征2:当前、延迟0.5s,1s,2s,3s时,进攻方和防守方球员在持球人3码、5码内的人数估计;
一次进攻的成败,大部分情况下取决于四分卫的发挥,而对其发挥其重要作用的,除了他自己,就是他身边的队友以及对手的数量,这一定程度上影响了他的可选择空间大小;
这一段的处理代码较多,只截取了一部分,如下:

测试数据处理
测试数据处理与训练数据保持一致即可;
建模
到此,数据处理完毕,后续就是建模、调参、combine等优化处理了,这一步我没有花太多精力,模型选择ExtraTreesRegressor,由于其使用了oob,因此不需要CV,结果如下:
最后
大家可以到我的Github上看看有没有其他需要的东西,目前主要是自己做的机器学习项目、Python各种脚本工具、数据分析挖掘项目以及Follow的大佬、Fork的项目等:
https://github.com/NemoHoHaloAi
kaggle竞赛分享:NFL大数据碗(上篇)的更多相关文章
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 老李分享:大数据测试之HDFS文件系统
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 老李分享:大数据框架Hadoop和Spark的异同
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 老李分享:大数据框架Hadoop和Spark的异同 2
Spark数据处理速度秒杀MapReduce Spark因为其处理数据的方式不一样,会比MapReduce快上很多.MapReduce是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果 ...
- Kaggle大数据竞赛平台入门
Kaggle大数据竞赛平台入门 大数据竞赛平台,国内主要是天池大数据竞赛和DataCastle,国外主要就是Kaggle.Kaggle是一个数据挖掘的竞赛平台,网站为:https://www.kagg ...
- 追本溯源 解析“大数据生态环境”发展现状(CSDN)
程学旗先生是中科院计算所副总工.研究员.博士生导师.网络科学与技术重点实验室主任.本次程学旗带来了中国大数据生态系统的基础问题方面的内容分享.大数据的发展越来越快,但是对于大数据的认知大都还停留在最初 ...
- 大数据学习路线:Zookeeper集群管理与选举
大数据技术的学习,逐渐成为很多程序员的必修课,因为趋势也是因为自己的职业生涯.在各个技术社区分享交流成为很多人学习的方式,今天很荣幸给我们分享一些大数据基础知识,大家可以一起学习! 1.集群机器监控 ...
- 阿里巴巴年薪800k大数据全栈工程师成长记
大数据全栈工程师一词,最早出现于Facebook工程师Calos Bueno的一篇文章 - Full Stack (需fanqiang).他把全栈工程师定义为对性能影响有着深入理解的技术通才.自那以后 ...
- 大数据竞赛平台——Kaggle 入门
Reference: http://blog.csdn.net/witnessai1/article/details/52612012 Kaggle是一个数据分析的竞赛平台,网址:https://ww ...
随机推荐
- 深度优先遍历 and 广度优先遍历
深度优先遍历 and 广度优先遍历 遍历在前端的应用场景不多,多数是处理DOM节点数或者 深拷贝.下面笔者以深拷贝为例,简单说明一些这两种遍历.
- LOGO的浮空显示-Verilog
为了方便生成准确的mif数据,以实现特定的透明效果.使用Photoshop将网上下载的Logo修改颜色,保存大小为120*120像素,如图1所示. 图1 ps修改后的Logo 使用Pic2mif软件, ...
- js 正则匹配 两个字符串之间,某个字符串之前(之后)的内容
1.js截取两个字符串之间的内容: var str = "aaabbbcccdddeeefff"; str = str.match(/aaa(\S*)fff/)[1]; alert ...
- zookeeper(1)-概述
ZooKeeper概述 ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现.它提供了简单原始的功能,分布式应用可以基于它实现更高级 ...
- 面试中常考的字符串操作方法大全,包含ES6
原文链接:http://caibaojian.com/js-string.html 一.charAt() 返回在指定位置的字符. var str="abc" console.log ...
- Python的驻留机制(仅对数字,字母,下划线有效)
Python的驻留机制及为在同一运行空间内,当两变量的值相同,则地址也相同. 举例: a = 'abc' b = 'abc' print(id(a)) print(id(b)) 以上示例为驻留机制有效 ...
- com.netflix.discovery.DiscoveryClient : Completed shut down of DiscoveryClient
启动报错:com.netflix.discovery.DiscoveryClient : Completed shut down of DiscoveryClient 解决方案: 添加web主件 ...
- python元祖(tuple)
# 列表:有序,元素可以被修改 # 列表 # list # li = [111,22,33,44] # 元组:元素不可被修改,不能被增加或者删除 # ps: # tuple # tu = (11,22 ...
- 利用脚本运行APP
1.电脑安装Xcode(iOS)/Androidsdk(Android),连接手机,并在手机上安装相应代理,下图为iOS的Xcode代理样式: 2.打开Appium,点击搜索图标,添加并设置该手机信息 ...
- DEVOPS技术实践_13:使用Jenkins持续传送设计-CD基础
1. 分支策略 持续集成中使用的分支策略包括以下三个: The master branch The integration branch The feature branch 而CD只在Integra ...