MYSQL入门总结
创建数据库及创建表
create schema/database ttest(名字); //创建数据库
create table ttest(建好的数据库名字).new_table(表名字)
(
a int not null,
b varchar(20) null,
c char (30) null,
primary key (a)); //这个主键要用括号括起来
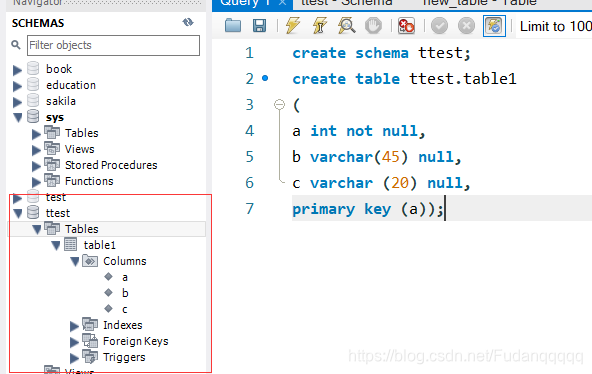
1.show columns from score; 2.desc education.score;
desc是describe的缩写
也可以查看某一列的信息
desc score(表名) s_score(列名);
show columns from ttest.table1; //查看建好的table1的表信息
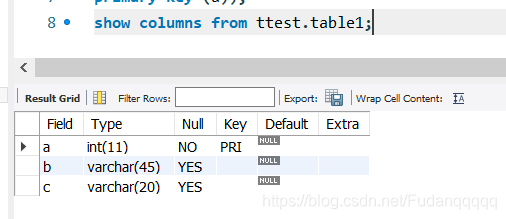
查看table1中b列的信息
desc ttest.table1 b;
表插入列、删除列、修改列、删除表
插入一列d:
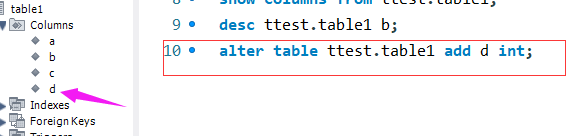
删除d列:

修改c列为varchar(123)
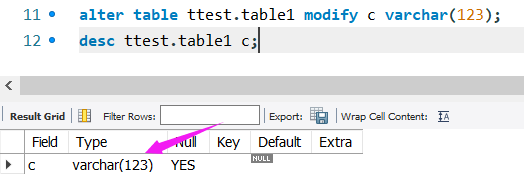
查找数据
select from where group by having order by 语句
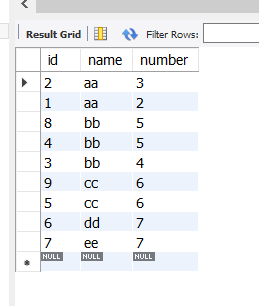
select * from new_table order by name,id desc;
//从表中输出所有列,排序顺序为优先name升序(asc系统默认),若name一样则依照id降序(desc)
select id,name,sum(number) from new_table group by name;
//按name的不同分成不同的组,每组中都输出对应的id,name和该name对应的所有number的和
列表原有数据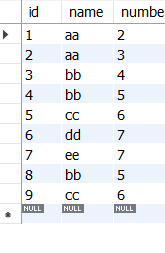 select结果
select结果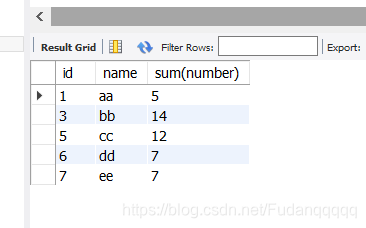
group by 后可以跟多个列,具体看这篇,讲的非常棒。
https://blog.csdn.net/u014717572/article/details/80687042
and且 or或
between A and B not between A and B 含义就是英文意思
字符串匹配 %任意字符串 _匹配一个字符
如:‘abcdefg’ like ‘%’ IS TRUE
‘abc’ like ‘a_c’ IS TRUE
聚合函数:count()计算选定集合中选定列的非NULL值的数目
max() min() 计算集合中选定列中最大最小值
sum() 选定列求和
avg() 选定列求平均值
连接查询
education数据库,包含四个表 课程、成绩、学生信息、教师信息
建数据库代码如下:
CREATE TABLE `Student`(
`s_id` VARCHAR(20),
`s_name` VARCHAR(20) NOT NULL DEFAULT '',
`s_birth` VARCHAR(20) NOT NULL DEFAULT '',
`s_sex` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`s_id`)
);
CREATE TABLE `Course`(
`c_id` VARCHAR(20),
`c_name` VARCHAR(20) NOT NULL DEFAULT '',
`t_id` VARCHAR(20) NOT NULL,
PRIMARY KEY(`c_id`)
);
CREATE TABLE `Teacher`(
`t_id` VARCHAR(20),
`t_name` VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY(`t_id`)
);
CREATE TABLE `Score`(
`s_id` VARCHAR(20),
`c_id` VARCHAR(20),
`s_score` INT(3),
PRIMARY KEY(`s_id`,`c_id`)
);
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-05-20' , '男');
insert into Student values('04' , '李云' , '1990-08-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-03-01' , '女');
insert into Student values('07' , '郑竹' , '1989-07-01' , '女');
insert into Student values('08' , '王菊' , '1990-01-20' , '女');
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
insert into Score values('01' , '01' , 80);
insert into Score values('01' , '02' , 90);
insert into Score values('01' , '03' , 99);
insert into Score values('02' , '01' , 70);
insert into Score values('02' , '02' , 60);
insert into Score values('02' , '03' , 80);
insert into Score values('03' , '01' , 80);
insert into Score values('03' , '02' , 80);
insert into Score values('03' , '03' , 80);
insert into Score values('04' , '01' , 50);
insert into Score values('04' , '02' , 30);
insert into Score values('04' , '03' , 20);
insert into Score values('05' , '01' , 76);
insert into Score values('05' , '02' , 87);
insert into Score values('06' , '01' , 31);
insert into Score values('06' , '03' , 34);
insert into Score values('07' , '02' , 89);
insert into Score values('07' , '03' , 98);
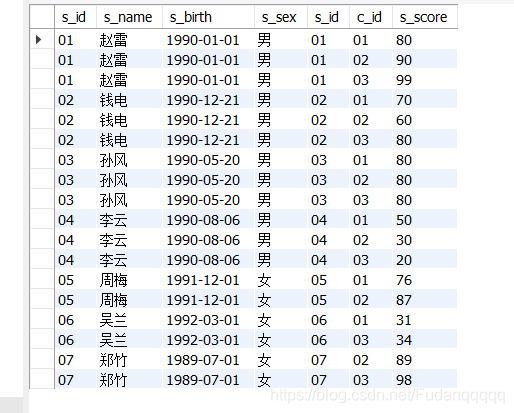
内连接:
A inner join B
select *
from student inner join score
on student.s_id = score.s_id; //on表示条件
运行:
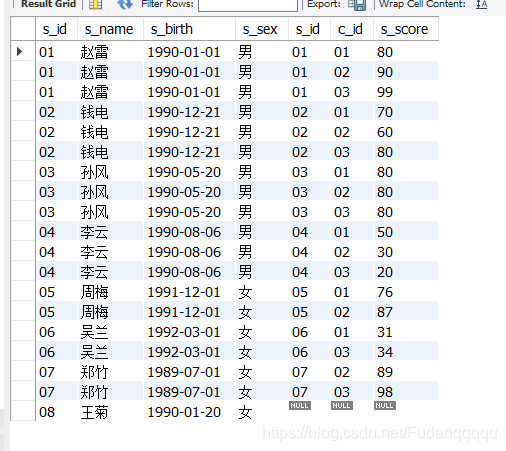
外连接:
left join:
左侧表全部输出,同时输出右侧表满足 on后的条件 的值,不满足则输出null
select *
from student left join score
on student.s_id=score.s_id; //用on表示条件
right join:
与left join相反
full join
全连接 返回左右表全部行,full join可以不跟on,此情况下等同于下面的交叉连接
交叉连接(笛卡尔积)
select count(*)
from student, score; //返回144
select count(*)
from student cross join score; //返回144
子查询
带in的子查询
in 或not in
//输出姓赵的同学的成绩
select * from score
where s_id in (select s_id from student where s_name like '赵%');
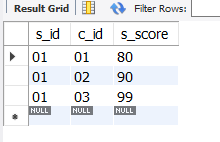
带exists的子查询
exists或not exists
select * from score;
select * from score
where exists (select s_id from student where s_name like '赵%');
运行结果:
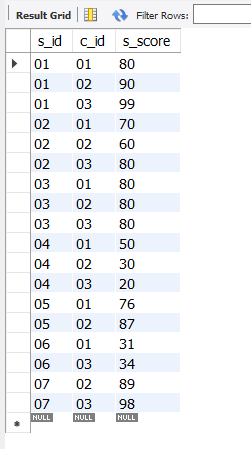
上面两个语句都返回score的全部信息,即下面的exists子查询未起到筛选作用
改进:
select * from score
where exists (select s_sex from student where s_name like '赵%' and student.s_id=score.s_id);
运行结果:
筛选成功
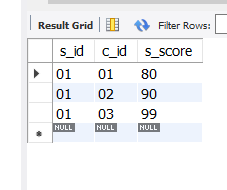
那么思考一下,exists其实只是一个存在量词的作用,即若exists后面跟的语句若返回一个非空集合则继续与前面比较,返回空集则不再继续比较。注意上面代码中exists后面select的是s_sex,但最终运行结果正确,即这里select的是什么不重要,再改成s_birth运行依然正确。
可以参考这里:
http://www.cnblogs.com/V1haoge/p/6385312.html
带any的子查询
any表示随便一个,比如 > any(select …),表示大于括号集合中任意一个值即可,不要与any的英文释义弄混了。
带all的子查询
all与any对应,表示后面集合中全部一个不漏都得怎么怎么样才行
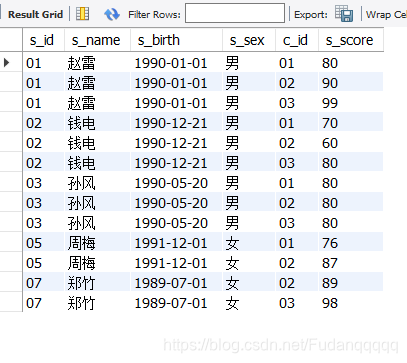
select student.*,c_id,s_score
from student left join score
on student.s_id=score.s_id
where s_score > all (select s_score from score where s_id=04);
运行结果:
多表查询
粘贴的,记录一下
本文链接:https://blog.csdn.net/adingyb/article/details/81234980
t2和t3数据表中存有他t1表中数据的id
选择删除t1表中的数据以及t2和t3表中相关(task_id)的数据
SQL语句如下:
DELETE t1,t2,t3 from cl_delivery_task t1
LEFT JOIN xh_saleact t2 ON t1.id=t2.task_id
LEFT JOIN xh_sale_detail t3 ON t1.id=t3.task_id
WHERE t1.id=‘2c27ec183faa4706ba3843c8238ced21’
MYSQL入门总结的更多相关文章
- 21分钟 MySQL 入门教程(转载!!!)
21分钟 MySQL 入门教程 目录 一.MySQL的相关概念介绍 二.Windows下MySQL的配置 配置步骤 MySQL服务的启动.停止与卸载 三.MySQL脚本的基本组成 四.MySQL中的数 ...
- MySQL入门02-MySQL二进制版本快速部署
在上篇文章 MySQL入门01-MySQL源码安装 中,我们介绍了MySQL源码安装的方法. 源码安装虽然有着更加灵活和更加优化等诸多优势.但源码编译安装部署的过程相对复杂,而且整个过程所花费的时间很 ...
- MYSQL入门全套(第三部)
MYSQL入门全套(第一部) MYSQL入门全套(第二部) 索引简介 索引是对数据库表中一个或多个列(例如,employee 表的姓名 (name) 列)的值进行排序的结构.如果想按特定职员的姓来查找 ...
- MySQL入门(三)
写了两篇<MySQL入门>以后我发现,写书的人还是都挺有本事的,起码人家知道怎么编排自己想讲的知识点,我实在是不知道该先说那里后说哪里,那我就想到什么讲什么吧. 一 写SQL 其实我是不想 ...
- MySQL入门笔记
MySQL入门笔记 版本选择: 5.x.20 以上版本比较稳定 一.MySQL的三种安装方式: 安装MySQL的方式常见的有三种: · rpm包形式 · 通用二进制 ...
- MySQL入门转载
21分钟 MySQL 入门教程 http://www.cnblogs.com/mr-wid/archive/2013/05/09/3068229.html 目录 一.MySQL的相关概念介绍 二.Wi ...
- mysql 入门 基本命令
MYSQL入门学习之一:基本操作 1.登录数据库 www.2cto.com 命令:mysql -u username –p (mysql -h主机地址 -u用户名 -p用户密码) ...
- MySQL入门笔记(一)
一.数据类型 1. 整型 2. 浮点型 3. 字符型 4. 日期时间型 二.数据库操作 1. 创建库 CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_nam ...
- MySQL入门(上)
1 课程回顾 自定义标签&编码实战 1)自定义标签步骤: 1.1 编写标签处理器类,继承SimpleTagSupport类,覆盖doTag方法 1.2 在WEB-INF目录下建立tld文件,在 ...
- 第二章 MySQL入门篇
第一章 MySQL入门篇 一.MySql简介 简言: 和SQL Server数据库相同,MySQl也是一个关系型数据库管理系统.由瑞典的MySQL AB公司开发,2008年被SUN公司收购,2009年 ...
随机推荐
- perfdog使用手册
PerfDog(性能狗)测试须知 Android平台 ScreenShot(只支持USB模式) FPS(1秒内游戏画面或者应用界面真实平均刷新次数,俗称帖率/FPS) 1)Avg(FPS):平均帖率 ...
- Email-发送邮件
Email 发送邮件 import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIME ...
- JS表单验证源码(带错误提示及密码等级)
先晒图 index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- IntelliJ IDEA搭建一个简单的springboot项目
一.IDEA 安装包 百度网盘链接:https://pan.baidu.com/s/1MYgZaBVWXgy64KxnoeJSyg 提取码:7dh2 IDEA注册码获取:http://idea.lan ...
- 使用vegrant安装centos7
1.首先去安装需要先安装好 Vagrant 和 VirtualBox. 安装好需要重启电脑. 可能网速会很慢,建议复制链接到迅雷下载,或者国内随便找个下载也可以. 2.在电脑创建vagrant_vm目 ...
- css实现带边框的冒泡提示框
需求是实现这种效果, 因为内容是动态的,使用图片不是很好: 原因: 如果内容确定只是一行,可以效果图裁剪3部分,分别是两侧和中间部分,然后用backgroud插入三张图片,但是要是内容是2行就不好处理 ...
- java集合框架备忘
List,Set,Map三者的区别? List(对付顺序的好帮手): List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象 Set(注重独一无二的性质): 不允许重复的集合.不会有多 ...
- java学习笔记之反射—Class类实例化和对象的反射实例化
反射之中所有的核心操作都是通过Class类对象展开的,可以说Class类是反射操作的根源所在,但是这个类的实例化对象,可以采用三种方式完成. java.lang.Class类的定义: public f ...
- jQuery---tab栏切换
tab栏切换 <!DOCTYPE html> <html> <head lang="en"> <meta charset="UT ...
- VNote笔记本和画图
VNote笔记本 跨平台的,以markdown标记语言记录的文本文档.从sourceforget.org开源网址下载即可. 画图集成: 1.集成graphviz http://www.graphviz ...