深入解读阿里云数据库POLARDB核心功能会话读一致性
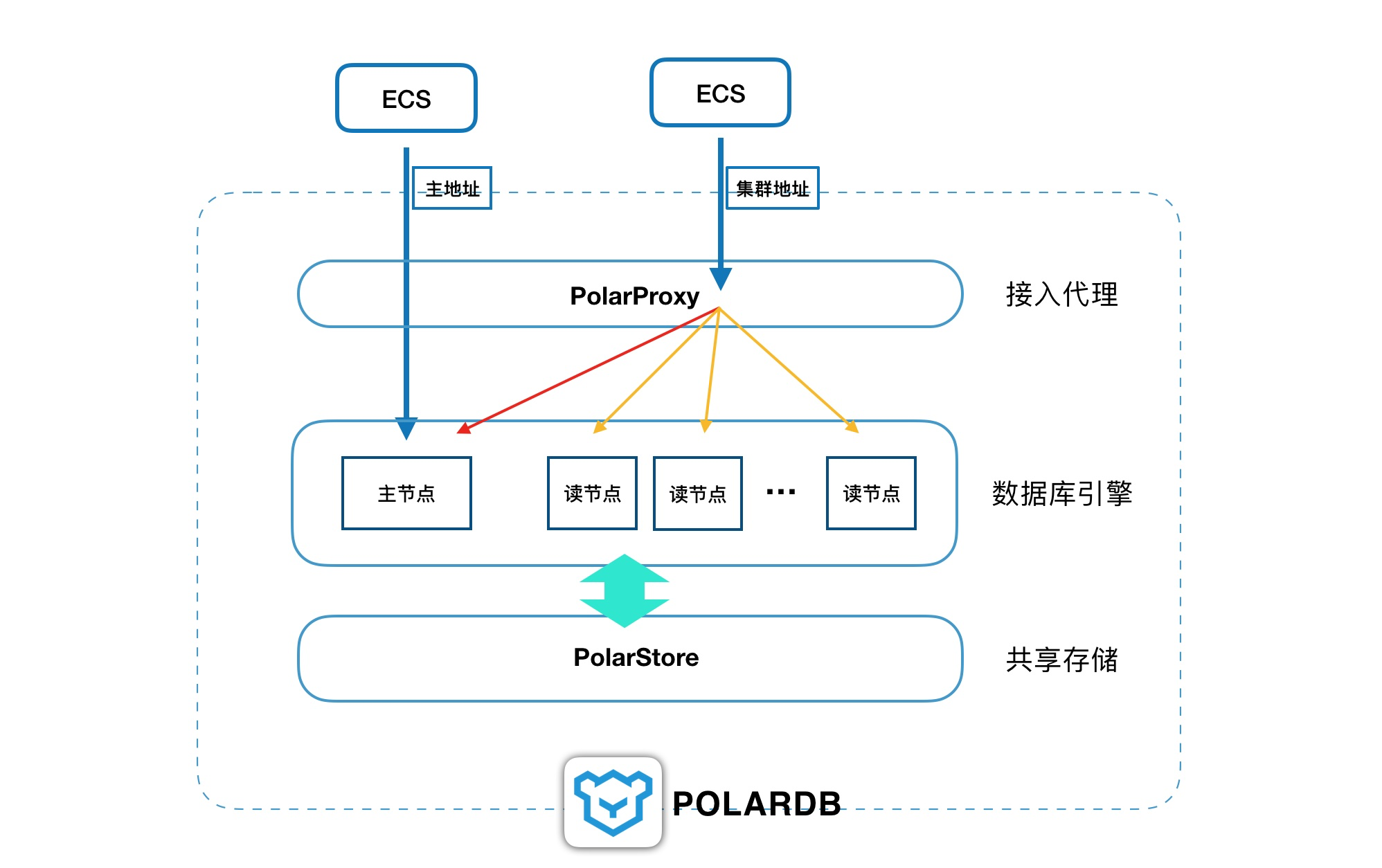
POLARDB架构
我们知道,POLARDB是一个由多个节点构成的数据库集群,一个主节点,多个读节点。对外默认提供两个地址,一个是集群地址,一个是主地址,推荐使用集群地址,因为它具备读写分离功能可以把所有节点的资源整合到一起对外提供服务。
MySQL读写分离解决和引入的问题
用过MySQL的都知道,MySQL的主从复制简单易用,非常流行,通过把主库的Binlog异步地传输到备库并实时应用,一方面可以实现高可用,另一方面备库也可以提供查询,来减轻对主库的压力。
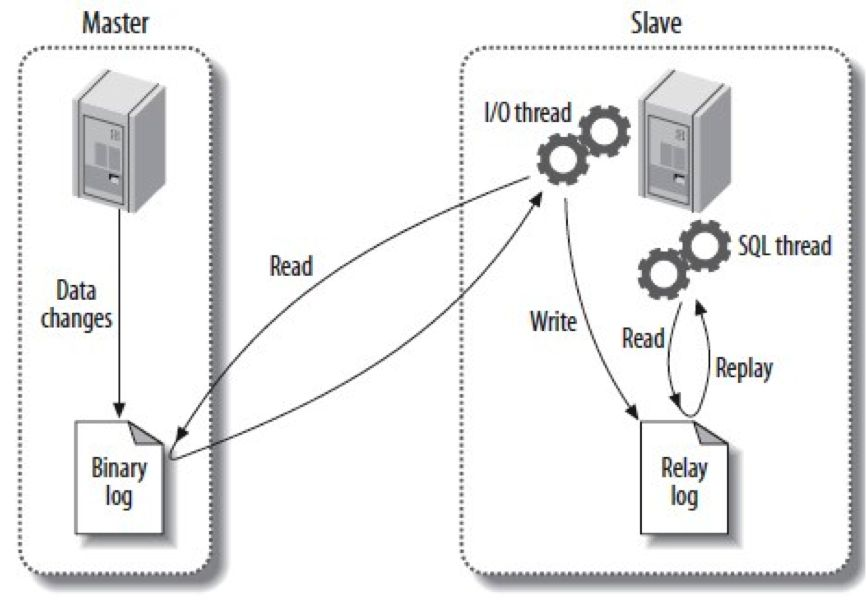
虽然备库可以提供查询,但存在两个问题,一是主库和备库一般提供两个不同的访问地址,应用程序端需要选择使用哪一个,对应用有侵入。二来MySQL的复制是异步的,即使是半同步也没办法做到100%强同步,因此备库的数据并不是最新的,有延迟,无法保证查询的一致性。
为了解决第一个问题,我们引入了读写分离代理,如下图,对应用程序非常友好。一般的实现是,代理会伪造成MySQL与应用程序建立好连接,解析发送进来的每一条SQL,如果是UPDATE、DELETE、INSERT、CREATE等写操作则直接发往主库,如果是SELECT则发送到备库。
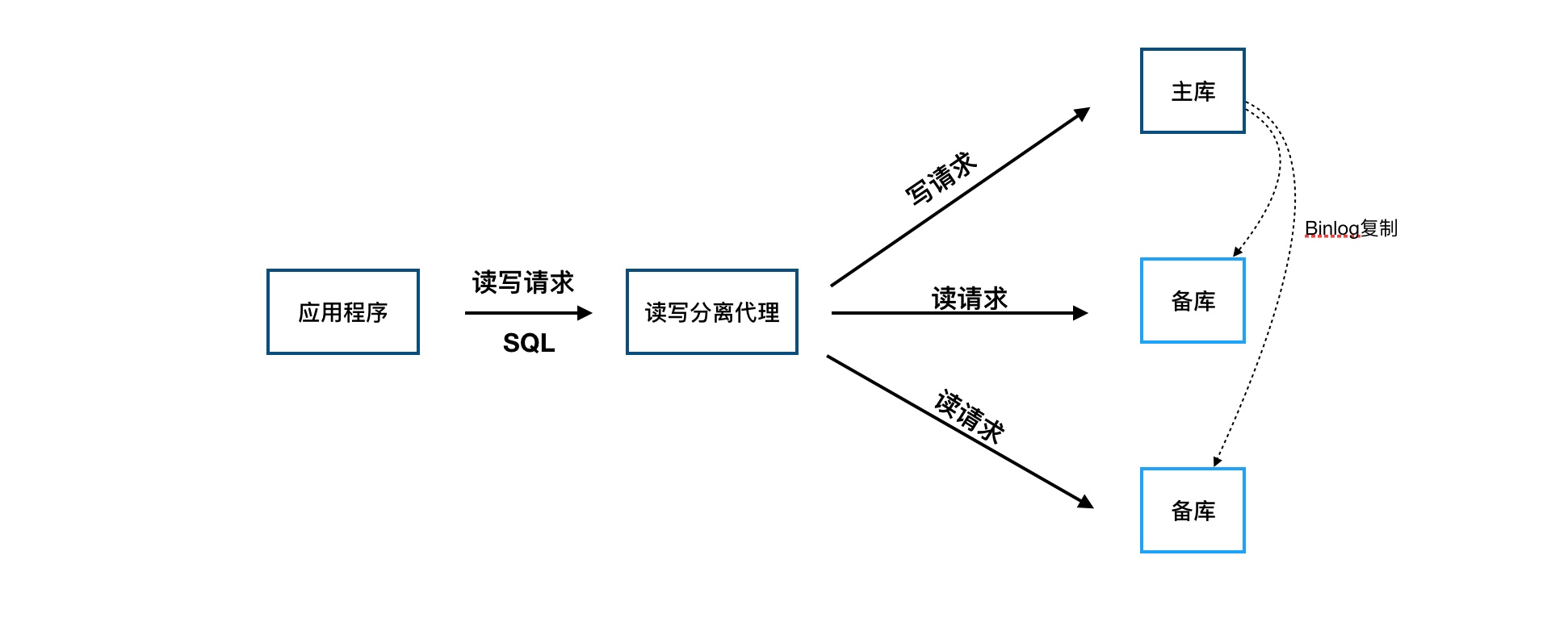
但是第二个问题——延迟导致的查询不一致——还是没有解决,使用时,就不可避免地会遇到备库SELECT查询数据不一致的现象(因为主备有延迟)。MySQL负载低的时候延迟可以控制在5秒内,但当负载很高时,尤其是对大表做DDL(比如加字段)或者大批量插入的时候,延迟会非常严重。
POLARDB读写分离的会话读一致性
POLARDB是读写分离的架构,传统的读写分离都只提供最终一致性的保证,主从复制延迟会导致从不同节点查询到的结果不同,比如一个会话内连续执行以下QUERY:
INSERT INTO t1(id, price) VALUES(111, 96);UPDATE t1 SET price = 100 WHERE id=111;SELECT price FROM t1;
在读写分离的下,最后一个查询的结果是不确定的,因为读会发到只读库,在执行SELECT时之前的更新是否同步到了只读库时不确定的,因此结果也是不确定的;因为有这个问题,所以就要求应用程序去适应最终一致性,而一般的解决方法是: 将业务做拆分,有高一致性要求的请求直连到主库,可以接受最终一致性的部分走读写分离;显然这样会增加应用开发的负担,还会增大主库的压力,影响读写分离的效果;
为了解决这个问题,在POLARDB中我们提供了会话一致性或者说因果一致性的保证,会话一致性即保证同一个会话内,后面的请求一定能够看到此前更新所产生版本的数据或者比这个版本更新的数据,保证单调性,就很好的解决了上面这个例子里的问题;
实现原理
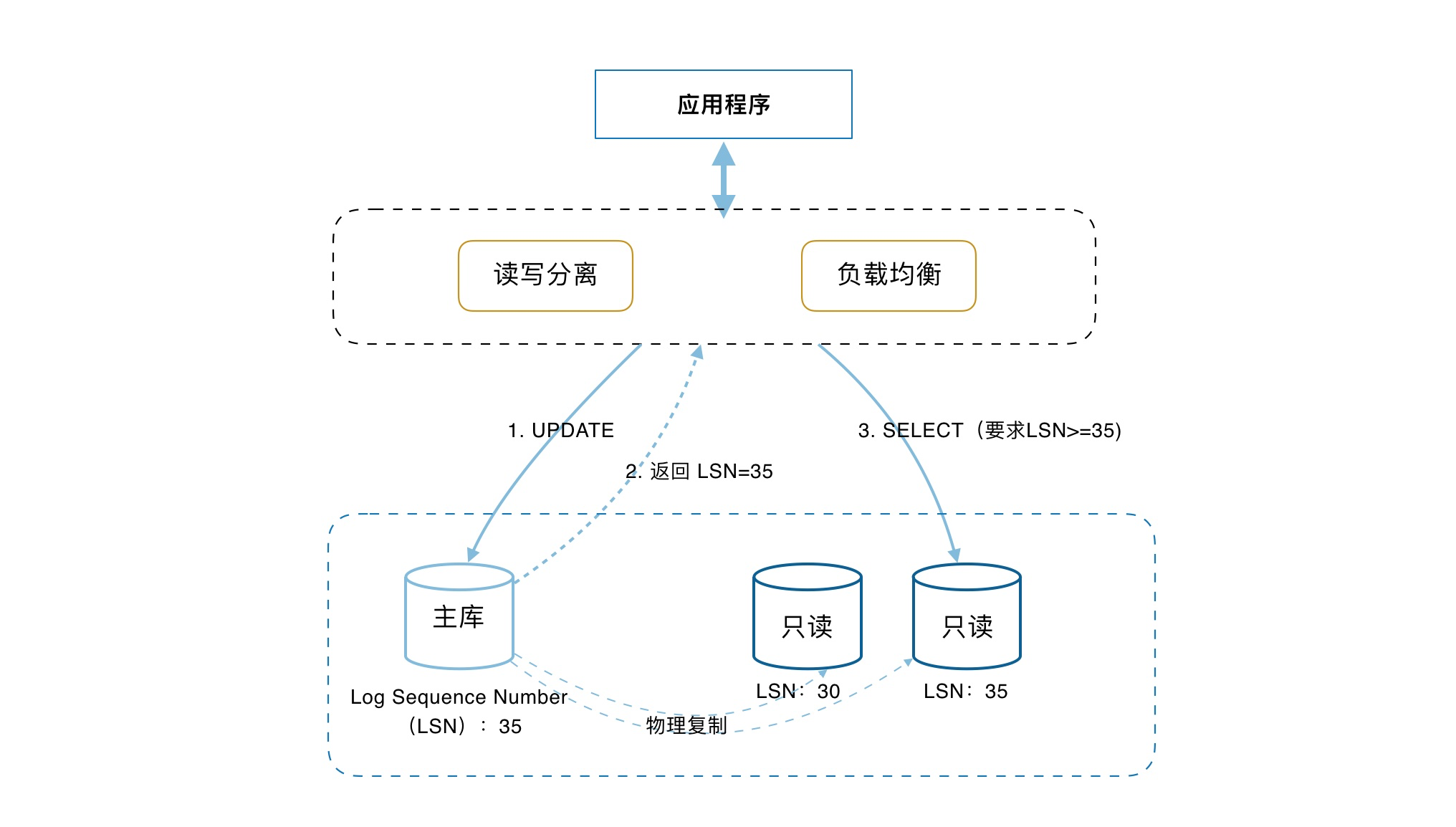
在POLARDB的链路中间层做读写分离的同时,中间层会track各个节点已经apply了的redolog位点即LSN,同时每次更新时会记录此次更新的位点为Session LSN, 当有新请求到来时我们会比较Session LSN 和当前各个节点的LSN,仅将请求发往LSN >= Session LSN的节点,从而保证了会话一致性;表面上看该方案可能导致主库压力大,但是因为POLARDB是物理复制,上一篇已详细介绍过,速度极快,在上述场景中,当更新完成后,返回客户端结果时复制就同步在进行,而当下一个读请求到来时主从极有可能已经完成,然后大多数应用场景都是读多写少,所以经验证在该机制下即保证了会话一致性,也保证了读写分离负载均衡的效果;
相关文章:
- 云数据库POLARDB优势解读系列文章之①——10分钟入门
- 云数据库POLARDB优势解读系列文章之②——高性价比
- 云数据库POLARDB优势解读系列文章之③——分钟级弹性
- 云数据库POLARDB优势解读系列文章之④——物理复制
- 云数据库POLARDB优势解读系列文章之⑤——会话读一致性
1月19日,阿里云数据库技术沙龙——云原生数据库POLARDB核心技术分享将在北京昆泰酒店举行,对POLARDB核心技术细节感兴趣的同学欢迎点击链接报名参加~
深入解读阿里云数据库POLARDB核心功能会话读一致性的更多相关文章
- 深入解读阿里云数据库POLARDB核心功能物理复制技术
日志是数据库的重要组成部份,按顺序以增量的方式记录了数据库上所有的操作,日志模块的设计对于数据库的可靠性.稳定性和性能都非常重要. 可靠性方面,在有一个数据文件的基础全量备份后,对运行中的数据库来说, ...
- 重新定义数据库的时刻,阿里云数据库专家带你了解POLARDB
摘要:POLARDB是阿里云ApsaraDB数据库团队研发的基于云计算架构的下一代关系型数据库,其最大的特色是计算节点与存储节点分离,借助优秀的RDMA网络以及最新的块存储技术.POLARDB不但满足 ...
- 云数据库POLARDB产品解读之二:如何做到高性价比
现在做任何事情都要看投入产出比,对应到数据库上其实就是性价比.POLARDB作为一款阿里自研数据库,经常被问的问题是:性能怎么样?能不能支撑我的业务?价格贵不贵?很显然,在早期调研阶段,对稳定性.可靠 ...
- 阿里云云服务器 ECS和云数据库 PolarDB的简单使用
阿里云云服务器 ECS和云数据库 PolarDB的简单使用 仅作为记录自己的操作使用,主要是怕自己太久不用都忘了 登录阿里云以后点击控制台 然后找到云服务器ECS,点击进入 在左侧找到实例,点击进入 ...
- Future Maker | 领跑亚太 进击的阿里云数据库
7月31日,阿里云马来西亚峰会在吉隆坡召开,阿里巴巴集团副总裁.阿里云智能数据库事业部总裁李飞飞在演讲中表示:“作为亚太地区第一的云服务提供商,阿里云数据库已为多家马来西亚知名企业提供技术支持,助力企 ...
- 选择阿里云数据库HBase版十大理由
根据Gartner的预计,全球非关系型数据库(NoSQL)在2020~2022预计保持在30%左右高速增长,远高于数据库整体市场. 阿里云数据库HBase版也是踏着技术发展的节奏,伴随着NoSQL和大 ...
- 【IT名人堂】何云飞:阿里云数据库的架构演进之路
[IT名人堂]何云飞:阿里云数据库的架构演进之路 原文转载自:IT168 如果说淘宝革了零售的命,那么DT革了企业IT消费的命.在阿里巴巴看来,DT时代,企业IT消费的模式变成了“云服务+数据”, ...
- 从运维的角度分析使用阿里云数据库RDS的必要性--你不应该在阿里云上使用自建的MySQL/SQL Server/Oracle/PostgreSQL数据库
开宗明义,你不应该在阿里云上使用自建的MySQL or SQL Server数据库,对了,还有Oracle or PostgreSQL数据库. 云数据库 RDS(Relational Database ...
- 赋能时空云计算,阿里云数据库时空引擎Ganos上线
随着移动互联网.位置感知技术.对地观测技术的快速发展,时空信息已从传统GIS行业渗透到大众应用及各行各业.从静态POI(兴趣点)到APP位置信息,从导航电子地图到车辆行驶轨迹,从卫星影像到三维城市建模 ...
随机推荐
- ARM 汇编 简单介绍
1. 汇编文件说明 : 汇编文件以 [.s]结尾的文件格式 注释:多行注释 /* */ : 单行注释 @ 2. 符号说明: 1) 汇编指令,一条指令对应一个机器码,完成一定的功能 2) 伪指令, ...
- python模块:typing
很多人在写完代码一段时间后回过头看代码,很可能忘记了自己写的函数需要传什么参数,返回什么类型的结果,就不得不去阅读代码的具体内容,降低了阅读的速度,加上Python本身就是一门弱类型的语言,这种现象就 ...
- R语言 基本语法
R语言基本语法 我们将开始学习R语言编程,首先编写一个"你好,世界! 的程序. 根据需要,您可以在R语言命令提示符处编程,也可以使用R语言脚本文件编写程序. 让我们逐个体验不同之处. 命令提 ...
- 7.12模拟T2(套路容斥+多项式求逆)
Description: \(n<=10,max(w)<=1e6\) 题解: 考虑暴力,相当于走多维格子图,不能走有些点. 套路就是设\(f[i]\)表示第一次走到i的方案数 \(f[i] ...
- thinkphp 数据库缓存
默认的数据库驱动位于Think\Db\Driver命名空间下面,驱动类必须继承Think\Db类,每个数据库驱动必须要实现的接口方法包括(具体参数可以参考现有的数据库驱动类库): 驱动方法 方法说明 ...
- NX二次开发-NXOPEN创建工程图表格Annotations::TableSectionBuilder *tableSectionBuilder1;
NX9+VS2012 #include <uf.h> #include <uf_tabnot.h> #include <NXOpen/Part.hxx> #incl ...
- [转]C# 将类的内容写成JSON格式的字符串
将类的内容写入到JSON格式的字符串中 本例中建立了Person类,赋值后将类中内容写入到字符串中 运行本代码需要添加引用动态库Newtonsoft.Json 程序代码: using System; ...
- 拾遗:不用使 sizeof 获取数组大小
... #include <stdio.h> #include <unistd.h> int main(void) { ] = {}; size_t num = () - (i ...
- CSS3新属性之---flex box布局实例
flex box布局实例 flex的强大之处在于不管什么布局,几行命令即可实现 /*本节模板div元素(代表骰子的一个面)是Flex容器,span元素(代表一个点)是Flex项目.如果有多个项目,就要 ...
- 12-MySQL-Ubuntu-数据表的查询-数据准备和基本查询(一)
一,数据准备 创建数据库.数据表 -- 创建数据库 create database python_test_1 charset=utf8; -- 使用数据库 use python_test_1; -- ...