Django之QuerySet 创建对象
在前面的模型介绍中设置了3个对象,出版商(publisher),作者(Authro),书籍(book)。首先我们在网页中添加各个对象信息填写的界面。填写后点击提交。将会传递给后端。传递方式采用post

后端生出处理代码如下:
def show_all_infor(request):
if request.method == 'POST':
publish=request.POST['pubisher']
address=request.POST['address']
city=request.POST['city']
state_province=request.POST['state_province']
coutry=request.POST['coutry']
web=request.POST['web']
ret1=Publisher.objects.get_or_create(name=publish,address=address,city=city,state_province=state_province,country=coutry,website=web)
firstname=request.POST['firstname']
secondname=request.POST['secondname']
email=request.POST['email']
ret2=Author.objects.get_or_create(first_name=firstname,last_name=secondname,email=email)
title=unicode(request.POST['title'])
publish_date=unicode(request.POST['publish_date'])
if len(Book.objects.filter(title=title)) > 0:
return HttpResponse('already exist')
else:
ret3=Book()
ret3.title=title
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.save()
ret3.authors.add(Author.objects.all()[1])
return HttpResponse(Book.objects.all())
首先判断数据传递方式是否是post. 如果是的话则取出post的数据。然后进行对象创建。在这里用的是Publisher.objects.get_or_create方法。其实对象创建总共有4种方法:
方法一:
Publisher.objects.create(name=publish,address=address,city=city,state_province=state_provicen,coutry=coutry,website=web)
方法二:
ret=Publisher(name=publish,address=address,city=city,state_province=state_provicen,coutry=coutry,website=web)
ret.save()
方法三:
ret=Publisher()
ret.name=publish
ret.address=address
ret.save()
方法四:首先尝试获取。不存在就创建,可以防止重复。就是这里采取的方法。
ret1=Publisher.objects.get_or_create(name=publish,address=address,city=city,state_province=state_province,country=coutry,website=web)
Publisher和Author创建的方法都是get_or_create的方法,这里需要重点讲下Book的创建方法。在Book中有个字段authors和publisher分别是ManyToManyField和ForeignKey
authors=models.ManyToManyField(Author)
publisher=models.ForeignKey(Publisher)
首先来看下publisher的创建。由于是ForeignKey的关系,也就是一对多。因此直接从Publisher对象中选择一个进行赋值就可以了
ret3.publisher=Publisher.objects.all()[1]
接下来看下authors的创建,authors是ManyToManyField,也就是多对多的关系。在创建的authors的时候要注意两点:
1 首先是要创建一个Book对象,然后进行保存。才能进行添加authors。如果代码是这样的:
ret3=Book()
ret3.authors.add(Author.objects.all()[1])
ret3.title=title
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.save()
则会报如下的错误"<Book: >" needs to have a value for field "book" before this many-to-many relationship can be used.
这个错误的意思就是需要先创建一个book的对象

因此正确的代码就是:
ret3=Book()
ret3.title=title
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.save()
ret3.authors.add(Author.objects.all()[1])
2 在创建Book对象的时候需要将书名,出版商,出版日期都包含进来,否则会报错。
如果代码是下面的这样:
ret3=Book()
ret3.save()
ret3.title=title
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.authors.add(Author.objects.all()[1])
就会报如下的错误IntegrityError:site_prj_book.publisher_id may not be NULL
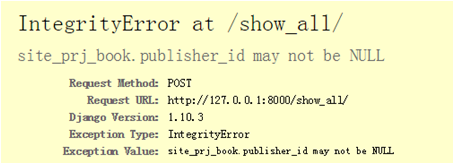
因此正确的代码如下:
ret3=Book()
ret3.title=title
ret3.publisher=Publisher.objects.all()[1]
ret3.publish_date=publish_date
ret3.save()
ret3.authors.add(Author.objects.all()[1])
另外在创建Book对象的时候,并没有用到get_or_create的方法。这是因为Book有ManyToManyField和ForeignKey的关系,需要首先创建一个对象。但是存在一个问题,如果输入的书名已经有记录了,那么如何避免重复记录呢,这里用到了filter方法:
Book.objects.filter(title=title)
过滤该名字的书名,如果存在,则返回already exist的界面。就不会继续新建对象。
if len(Book.objects.filter(title=title)) > 0:
return HttpResponse('already exist')
来看下几个查询界面的后端处理代码:首先是获取所有的对象。然后在网页上显示
def result1(request):
result=Publisher.objects.all()
return HttpResponse(result) def result2(request):
result=Author.objects.all()
return HttpResponse(result) def result3(request):
result=Book.objects.all()
return HttpResponse(result)
其实相对于在网页上显示,在Django工程中也有查询的方法。在pycharm中进入终端,然后输入python manage.py shell进入管理界面。
D:\django_test2>python manage.py shell
Python 2.7.11 (v2.7.11:6d1b6a68f775, Dec 5 2015, 20:32:19) [MSC v.1500 32 bit (Intel)]
Type "copyright", "credits" or "license" for more information.
IPython 5.3.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
然后从模型中引入各个模块
In [1]: from site_prj.models import Publisher,Author,Book
输入查询语句:
In [2]: Publisher.objects.all()
得到结果:
Out[2]: <QuerySet [<Publisher: 成都日报>
另外我们还可以在shell中打印出对应的SQL语句便于问题定位和查看:
In [5]: print Publisher.objects.all().query
SELECT "site_prj_publisher"."id", "site_prj_publisher"."name", "site_prj_publisher"."address", "site_prj_publisher"."city", "site_prj_publisher"."state_province", "site_prj_publisher"."country", "site_prj_publishe
r"."website" FROM "site_prj_publisher"
这一章介绍了对象创建的基本方法,下一章将介绍更对对象的高级应用。
Django之QuerySet 创建对象的更多相关文章
- Django之queryset API
1. QuerySet 创建对象的方法 >>> from blog.models import Blog >>> b = Blog(name='Beatles Bl ...
- 如何有效的遍历django的QuerySet
最近做了一个小的需求,在django模型中通过前台页面的表单的提交(post),后台对post的参数进行解析,通过models模型查询MySQL,将数据结构进行加工,返回到前台页面进行展示.由于对dj ...
- Django OMR QuerySet的特性/存在意义
QuerySet存在的意义主要在惰性机制和缓存两点 ---------->惰性机制: 所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个Quer ...
- django的queryset和objects对象
1. queryset是查询集,就是传到服务器上的url里面的内容.Django会对查询返回的结果集QerySet进行缓存,这里是为了提高查询效率. 也就是说,在你创建一个QuerySet对象的时候, ...
- Django ORM queryset object 解释(子查询和join连表查询的结果)
#下面两种是基于QuerySet查询 也就是说SQL中用的jion连表的方式查询books = models.UserInfo.objects.all() print(type(books)) --- ...
- Django ORM Queryset 的缓存机制, 惰性查询简述
在Django的ORM中 必须注意由于QuerySet的 cache导致的数据获取不正确的问题 在哪些情况下不会出发QuerySet缓存? 隐式存储QuerySet(查询语句没有显示赋值给变量而直接进 ...
- Django之QuerySet 查询
首先来看下如何查询.我们在网页中增加书名的查询链接 后端的查询处理代码:这里由于authors是manytomanyfiled,因此我们这里用r.authors.all().first()来查询符合条 ...
- django 补充 QuerySet数据类型
1 QuerySet数据类型 特点: (1) 可切片 Entry.objects.all()[:5] (2) 可迭代 : articleLis ...
- Python - Django - ORM QuerySet 方法补充
models.py: from django.db import models class Employee2(models.Model): name = models.CharField(max_l ...
随机推荐
- java中List、Map、Set、Collection、Stack、Queue等的使用
java中这几个东西是比较常用的,虽然我用的不多,也正是因为用的不多,所以我一直搞不清楚他们之间的具体用法以及相互之间的关系,现在特单独作为一个东西来总结一下. 本文参考一下资料: 1.<jav ...
- ODP.NET OracleBulkCopy
using System;using System.Collections.Generic;using System.Linq;using System.Text;using Oracle.DataA ...
- RSA公钥,私钥和数字签名通用理解
一.公钥加密 假设一下,我找了两个数字,一个是1,一个是2.我喜欢2这个数字,就保留起来,不告诉你们(私钥),然后我告诉大家,1是我的公钥. 我有一个文件,不能让别人看,我就用1加密了.别人找到了这个 ...
- Azure上采用Powershell从已有的VHD创建VM
刚刚的一篇Blog采用Json Template的方式从已有的VHD创建了一台新的VM.由于Json Template封装的比较好,可以改的内容不多. 下面将介绍通过用Powershell来从已有的V ...
- vim 显示行号
set nu https://blog.csdn.net/lwj103862095/article/details/8122316
- [C++] 递归之全排列问题、半数集
一.递归的定义 一个过程或函数在其定义或说明中又直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个原问题相似的规模较小的问题来求解. 二.用递归求解问题的主要步骤 1.找出相似性 ...
- Mybatis代码学习
Mybatis架构学习 MyBatis 是支持定制化 SQL.存储过程以及高级映射的持久层框架.MyBatis 封装了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.可以对配置和原生Map使用 ...
- RabbitMQ 基本概念和使用
当前各种应用大量使用异步消息模型,并随之产生众多消息中间件产品及协议,标准的不一致使应用与中间件之间的耦合限制产品的选择,并增加维护成本.AMQP是一个提供统一消息服务的应用层标准协议,基于此协议的客 ...
- 第九章 Java中线程池
Java中的线程池是运用场景最多的并发框架,几乎所有需求异步或并发执行任务的程序都可以使用线程池.在开发过程中,合理地使用线程池能够带来3个好处. 降低资源消耗:通过重复利用已创建的线程降低线程创建和 ...
- Android添加Menu菜单
在安卓中添加Menu菜单十分简单. 步骤: 1.在menu文件夹中的main.xml文件中添加要添加的项目. <menu xmlns:android="http://schemas.a ...