ubuntu安装hadoop经验
安装环境:
1 linux系统
2 或(windows下)虚拟机
本文在linux系统ubuntu下尝试安装hadoop
安装前提
1 安装JDK(安装oracle公司的JDK )
(1)检查是否已安装JDK
$ java -version
(2)(本人采用手动安装)官网下载jdk,解压文件,放置在 /usr/目录下 如:/usr/local/jdk
(3)配置环境变量,设置全局(也就是此系统下所有用户的)环境变量
命令:$ sudo vi ~/.bashrc (用vi编辑器)
文件末尾添加:
#set java environment - 注释
export JAVA_HOME=/usr/local/jdk/jdk1..0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存后结束
(4)检查

2 安装ssh
(1)检查是否安装ssh(一般会自带客户端服务:ssh-client,本机需要安装对应的服务端服务ssh-server·「ssh-client与ssh-server版本要对应」)
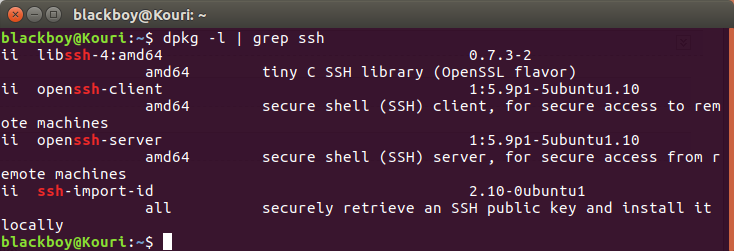
命令:$ dpkg -l | grep ssh
查看是否有 openssh-server
(2)安装openssh-server
命令:sudo apt-get install openssh-server
问题:因为本机已安装的openssh-client 与要安装的openssh-server不匹配,所以要先将openssh-client 降低版本
(3)查看ssh服务是否开启
命令:ps -e | grep sshd
如图:没有服务,而已安装,那就是没有启动

命令 ps -e | grep ssh
说明ssh-client服务开启,而ssh-server服务没启动

(4)启动ssh-server
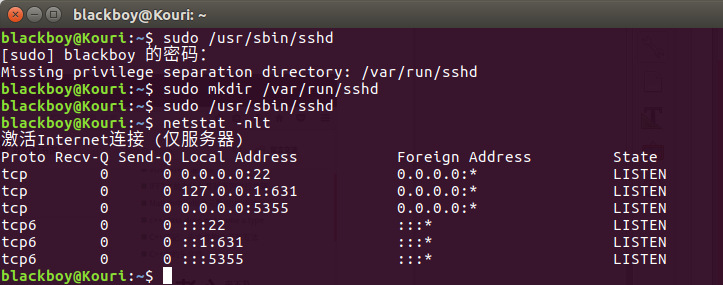
命令:sudo /etc/init.d/ssh start 或 sudo service ssh start
问题:依然没有启动,无法理解错误原因,但是找到解决方法,如图,当第四行 有 :::22表示开启22端口
(5)登录ssh
命令:ssh localhost

(6)设置ssh免码登录( 没有详细了解,有待继续学习 )
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod ~/.ssh/authorized_keys
安装hadoop(搭建hadoop开发环境)
(1)官网下载hadoop,并解压好文件
(2)安装配置
先了解hadoop的运行模式
@运行模式
单机模式:默认,非分布式模式运行,读取本地资源,不使用hdfs(分布式文件系统),不加载hadoop守护进程
伪分布式:“单节点集群”上运行hadoop,所有守护进程运行在同一台机器上,读取hdfs上资源
全分布式:守护进程运行在一个集群上
@配置:
1 单机环境配置:
没有创建额外用户来使用hadoop,本次在当前用户下操作(可能会遇到权限问题)
$ vi .bashrc (用vi编辑 .bashrc)
将以下代码添加到 .bashrc 中
#set hadoop environment
export HADOOP_HOME=/hadoop/hadoop-2.9.1 //hadoop文件路径
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ISTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
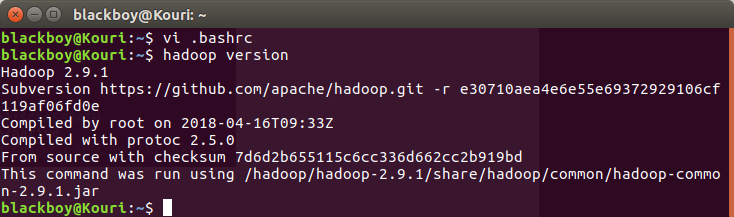
vi /hadoop/hadoop-2.9./etc/hadoop/hadoop-env.sh (配置hadoop-env.sh 的JAVA_HOME环境变量)
export JAVA_HOME=/usr/local/jdk/.. //jdk文件路径
查看是否安装
2 伪分布式配置
(一)修改 /hadoop/hadoop-2.9.1/etc/hadoop/ 目录下的4个文件
注:只是进行简单的初期配置,更详细的配置可以去官网或百度查阅
(1)core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Kouri:9000</value>
</property>
</configuration>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hadoop-2.9.1/tmp/dfs/data</value>
</property>
</configuration>
(3)mapred-site.xml
因为初始只有mapred-site.xml.template,需要修改文件名
mv mapred-site.xml.template mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name></name>
<value></value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name> //主机名
<value>Kouri</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name> //浏览器地址
<value>localhost:8088</value>
</property>
</configuration>
(二)格式化HDFS
$ cd ~
$ hdfs namenode -format
(三)启动 (逐个启动/全部启动)
全部启动:start-all.sh
(四)查看进程
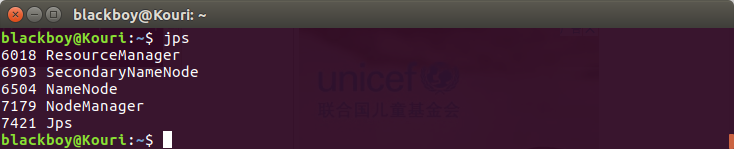
$ jps //列出守护进程
安装成功结果
(五)查看运行状态 - web界面
http://localhost:50070/ - Hadoop hdfs 状态
http://localhost:8088/ - hadoop yarn 管理
ubuntu安装hadoop经验的更多相关文章
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
- Ubuntu 安装 hadoop
安装完Linux后,我们继续(VMWare 安装 Linux http://blog.csdn.net/hanjun0612/article/details/55095955) 这里我们开始学习安装 ...
- Ubuntu 安装hadoop 伪分布式
一.安装JDK : http://www.cnblogs.com/E-star/p/4437788.html 二.配置SSH免密码登录1.安装所需软件 sudo apt-get ins ...
- Ubuntu安装Hadoop
系统:Ubuntu16.04 JDK:jdk-8u201 Hadoop:3.1.2 一.安装JDK https://www.cnblogs.com/tanrong/p/10641803.html 二. ...
- ubuntu安装hadoop 若干问题的解决
问题1:安装openssh-server失败 原因: 下列软件包有未满足的依赖关系: openssh-server : 依赖: openssh-client (= 1:5.9p1-5ubuntu1) ...
- Ubuntu - 安装hadoop(简约版)
相关版本: VMware ubuntuKylin16.04 JDK :openjdk Hadoop-2.9.1 步骤: 1.SSH 配置 [ 远程登陆 ] [ 配置SSH免码登陆 ] *测试:ssh ...
- 在Ubuntu上单机安装Hadoop
最近大数据比较火,所以也想学习一下,所以在虚拟机安装Ubuntu Server,然后安装Hadoop. 以下是安装步骤: 1. 安装Java 如果是新机器,默认没有安装java,运行java –ver ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- 安装Hadoop及Spark(Ubuntu 16.04)
安装Hadoop及Spark(Ubuntu 16.04) 安装JDK 下载jdk(以jdk-8u91-linux-x64.tar.gz为例) 新建文件夹 sudo mkdir /usr/lib/jvm ...
随机推荐
- java文本文件读写
java的IO系统中读写文件使用的是Reader和Writer两个抽象类,Reader中的read()和close()方法是抽象方法,Writer中的write().flush()和close()方法 ...
- python3 之logging模块
logging.getLogger(name=None)Return a logger with the specified name or, if name is None, return a lo ...
- laravel csrf保护
有时候我们的项目需要和外部的项目进行接口对接,如果是post的方式请求;laravel要求csrf保护 但是别人是ci框架或者没有csrf_token的;该如何处理呢? 可以把我们不需要csrf的ur ...
- 无法确定要使用哪一版本的 ASP.NET Web Pages。
若要使用此站点,请在站点的 web.config 文件中指定一个版本.有关详细信息,请参阅 Microsoft 支持站点上的以下文章: http://go.microsoft.com/fwlink/? ...
- java继承初级
总结:重写方法,方法体内容不同. 还有子类都不能加public.它表示公共,一个程序只能有一个公共类 package com.sa; public class Ac { public void rea ...
- net.sf.json.JSONObject 和org.json.JSONObject
参考 net.sf.json.JSONObject 和org.json.JSONObject 的差别
- altium designer 中器件原理图库中,将一个器件分成几部分是如何操作的?就是如何用part表示?
在SCH Library的Components中选中你要添加part的器件,tools菜单--new part即可
- Scala的Json序列化
import java.util.TimeZone import com.fasterxml.jackson.databind.{DeserializationFeature, ObjectMappe ...
- Python函数(一)-return返回值
定义一个函数可以在最后加上return返回值,方便查看函数是否运行完成和返回函数的值 # -*- coding:utf-8 -*- __author__ = "MuT6 Sch01aR&qu ...
- CAD库中列举所有航路点
select distinct f1.airway_point_name,f1.latitude,f1.longitude,upper(f1.airway_point_type_name)type,f ...