day7(redis的pipline使用)
1.pipeline原理
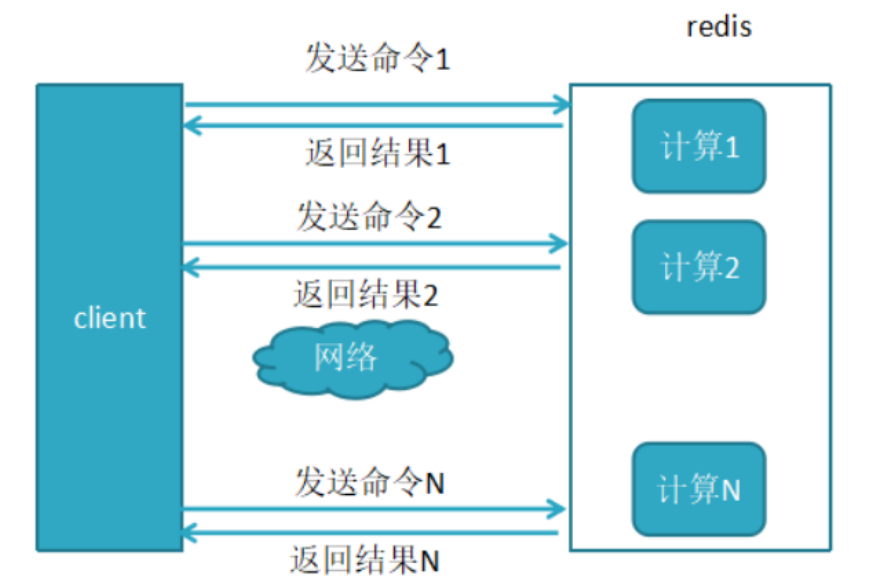
- Redis是建立在TCP协议基础上的CS架构,客户端client对redis server采取请求响应的方式交互。
- 一般来说客户端从提交请求到得到服务器响应,需要传送两个tcp报文
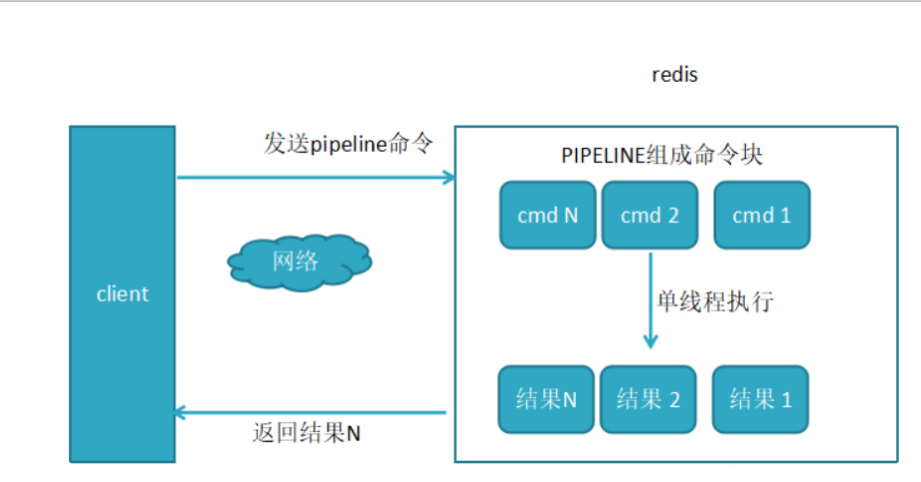
- 设想这样的一个场景,你要批量的执行一系列redis命令,例如执行100次get key,这时你要向redis请求100次+获取响应100次。如果能一次性将100个请求提交给redis server,执行完成之后批量的获取相应,只需要向redis请求1次,然后批量执行完命令,一次性结果,性能是不是会好很多呢?
1.2未使用pipeline执行N条命令


In [1]: from django_redis import get_redis_connection # 导入 get_redis_connection模块
In [2]: redis_client = get_redis_connection('default') # 连接redis 0号库
'''方法1:使用普通方法执行'''
In [3]: for i in range(99999): ...:
redis_client.set(i,i)
'''方法2:使用pipeline执行'''
In [4]: p1 = redis_client.pipeline() # 实例化一个pipeline对象
In [5]: for i in range(99999): ...:
p1.set(i,i) # 把要执行的命令打包到pipeline
In [6]: p1.execute()

day7(redis的pipline使用)的更多相关文章
- 网络协议之:redis protocol 详解
目录 简介 redis的高级用法 Redis中的pipline Redis中的Pub/Sub RESP protocol Simple Strings Bulk Strings RESP Intege ...
- 老男孩python第六期
01 python s6 day7 上节回顾02 python s6 day7 SNMP使用03 python s6 day7 大型监控架构讲解04 python s6 day7 Redis使用05 ...
- scrapy-redis
scrapy_redis的大概思路:将爬取的url通过 hashlin.sha1生成唯一的指纹,持久化存入redis,之后的url判断是否已经存在,达到去重的效果 下载scrapy-redis git ...
- scrapy_redis之官网列子domz
一. domz.py from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, ...
- 40+倍提升,详解 JuiceFS 元数据备份恢复性能优化之路
JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同.为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进 ...
- go使用go-redis操作redis 连接类型,pipline, 发布订阅
内容: 一 . 客户端Client(普通模式,主从模式,哨兵模式)二. conn连接(连接, pipline, 发布订阅等)三. 示例程序(连接, pipline, 发布订阅等)客户端Client 普 ...
- redis的Linux系统安装与配置、redis的api使用、高级用法之慢查询、pipline事物
今日内容概要 redis 的linux安装和配置 redis 的api使用 高级用法之慢查询 pipline事务 内容详细 1.redis 的linux安装和配置 # redis 版本选择问题 -最新 ...
- redis pipline 和 事务
1. Pipeline:“管道”,和很多设计模式中的“管道”具有同样的概念,pipleline的操作,将明确client与server端的交互,都是“单向的”:你可以将多个command,依次发给se ...
- 集群Redis使用 Python pipline大批量插入数据
class myRedis(object): def __init__(self,redis_type=None,**args): if redis_type == " ...
随机推荐
- SQL删除语句DROP、TRUNCATE、 DELETE 的区别
主要介绍了SQL删除语句DROP.TRUNCATE. DELETE 的区别,帮助大家更好的理解和学习sql语句,感兴趣的朋友可以了解下 DROP: 1 DROP TABLE test; 删除表test ...
- CentOS6.x 安装 nginx-1.19.4
1.下载nginx http://nginx.org/en/download.html wget http://nginx.org/download/nginx-1.19.4.tar.gz 2.解压 ...
- js常用的遍历方法以及flter,map方法
1.首先明确vue主要操作数据.他并不提倡操作dom. 数组的变异:能改变原数组. *** 先来复习下便利==遍历一个数组的四种方法: <script> let arr = [1, 2, ...
- 什么是麒麟(kylin)?查数据贼快的哟
前言 微信搜[Java3y]关注这个有梦想的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创文 ...
- Java 实现输入公历日期输出农历日期、生肖、天干地支、节日、节气等信息
最近的工作中客户要求前台页面展示日历,日历内容包括:农历年月日日.公历年月日.生肖.天干地支.农历节日.公历节日.24节气等信息,之前在网上查找资料关于Java实现方面的文章不少,但是大多数针对节气. ...
- maven install 时 pom中skip test
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-suref ...
- Hadoop2.6伪分布式按照官网指点安装(1)
参考:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/SingleCluster.html 照抄:安装成功 ...
- 最全总结 | 聊聊 Python 办公自动化之 Word(中)
1. 前言 上一篇文章,对 Word 写入数据的一些常见操作进行了总结 最全总结 | 聊聊 Python 办公自动化之 Word(上) 相比写入数据,读取数据同样很实用! 本篇文章,将谈谈如何全面读取 ...
- webug第一关:很简单的一个注入
第一关:很简单的一个注入 上单引号报错 存在注入,用order by猜列的个数 union select 出现显示位 查数据库版本,用户和当前数据库名 查表名和列名 最后,激动人心的拿flag
- 7、Spring Boot检索
1.ElasticSearch简介 Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard(分片)的方式保证数据安全,并且提供自动resha ...